Como fazer Scraping do Open Collective: Guia de Dados Financeiros e de Contribuidores
Saiba como fazer scraping do Open Collective para transações financeiras, listas de contribuidores e dados de financiamento de projetos. Extraia insights...
Proteção Anti-Bot Detectada
- Cloudflare
- WAF e gestão de bots de nível empresarial. Usa desafios JavaScript, CAPTCHAs e análise comportamental. Requer automação de navegador com configurações stealth.
- Limitação de taxa
- Limita requisições por IP/sessão ao longo do tempo. Pode ser contornado com proxies rotativos, atrasos de requisição e scraping distribuído.
- WAF
Sobre Open Collective
Descubra o que Open Collective oferece e quais dados valiosos podem ser extraídos.
Sobre o Open Collective
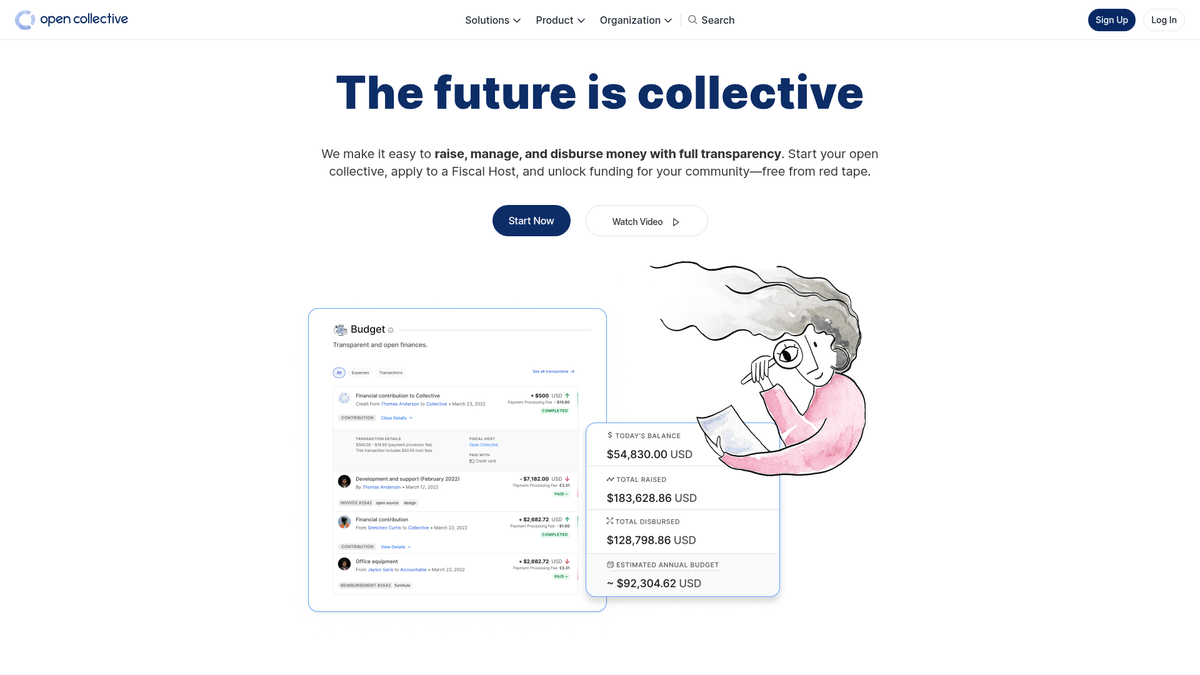
O Open Collective é uma plataforma financeira e jurídica única, projetada para fornecer transparência para organizações lideradas pela comunidade, projetos de software open-source e associações de bairro. Atuando como uma ferramenta de financiamento descentralizada, permite que 'coletivos' arrecadem dinheiro e gerenciem despesas sem a necessidade de uma entidade jurídica formal, muitas vezes utilizando anfitriões fiscais para suporte administrativo. Grandes projetos de tecnologia como Babel e Webpack dependem desta plataforma para gerenciar seus ecossistemas financiados pela comunidade.
A plataforma é reconhecida por sua transparência radical. Cada transação, seja uma doação de uma grande corporação ou uma pequena despesa para um encontro comunitário, é registrada e visível publicamente. Isso fornece uma riqueza de dados sobre a saúde financeira e os hábitos de consumo de algumas das dependências open-source mais críticas do mundo.
Fazer scraping do Open Collective é altamente valioso para organizações que buscam realizar pesquisas de mercado sobre a economia open-source. Ele permite que os usuários identifiquem leads de patrocínio corporativo, acompanhem tendências de financiamento de desenvolvedores e auditem a sustentabilidade financeira de projetos de software críticos. Os dados servem como uma janela direta para o fluxo de capital dentro da comunidade global de desenvolvedores.
Por Que Fazer Scraping de Open Collective?
Descubra o valor comercial e os casos de uso para extração de dados de Open Collective.
Analisar a Sustentabilidade de Projetos open-source
Acompanhe a saúde financeira e a viabilidade a longo prazo de projetos críticos de infraestrutura tecnológica como Webpack, Babel e Logseq.
Prospecção de Patrocínios Corporativos
Identifique organizações que já patrocinam softwares open-source para criar uma lista segmentada de leads em potencial para suas próprias iniciativas.
Auditorias de Transparência Financeira
Monitore como grupos descentralizados e coletivos comunitários alocam seus fundos para garantir a prestação de contas aos doadores e partes interessadas.
Descoberta de Tendências de Mercado
Avalie quais categorias — como tecnologia, ativismo ambiental ou educação — estão recebendo o maior crescimento em financiamento comunitário.
Pesquisa de Contribuidores e Influenciadores
Descubra os principais contribuidores individuais e corporativos em nichos específicos para encontrar influenciadores-chave para divulgação ou recrutamento.
Rastreamento do Impacto de Subsídios
Agregue dados sobre como grandes subsídios são desembolsados em vários projetos para medir o impacto real dos gastos filantrópicos.
Desafios do Scraping
Desafios técnicos que você pode encontrar ao fazer scraping de Open Collective.
Renderização Pesada em JavaScript
O Open Collective é construído como uma aplicação web moderna que requer a execução completa de JavaScript para renderizar livros contábeis e listas de contribuidores.
Arquitetura GraphQL Complexa
O site busca dados por meio de consultas GraphQL profundamente aninhadas, tornando o parsing de HTML tradicional menos eficiente do que o monitoramento das respostas da API.
Padrões de Carregamento Dinâmico
Históricos de transações e listas de membros geralmente usam rolagem infinita ou botões 'Carregar Mais', que exigem automação orientada a eventos para extração total.
Cloudflare e Rate Limiting
O scraping de alta frequência pode disparar o Web Application Firewall (WAF) do Cloudflare ou resultar em banimentos temporários de IP devido a limites globais de taxa rigorosos.
Estruturas de Dados Aninhadas
As informações sobre anfitriões fiscais, coletivos e despesas estão distribuídas em diferentes camadas da página, exigindo uma navegação complexa em várias etapas.
Scrape Open Collective com IA
Sem código necessário. Extraia dados em minutos com automação por IA.
Como Funciona
Descreva o que você precisa
Diga à IA quais dados você quer extrair de Open Collective. Apenas digite em linguagem natural — sem código ou seletores.
A IA extrai os dados
Nossa inteligência artificial navega Open Collective, lida com conteúdo dinâmico e extrai exatamente o que você pediu.
Obtenha seus dados
Receba dados limpos e estruturados prontos para exportar como CSV, JSON ou enviar diretamente para seus aplicativos.
Por Que Usar IA para Scraping
A IA facilita o scraping de Open Collective sem escrever código. Nossa plataforma com inteligência artificial entende quais dados você quer — apenas descreva em linguagem natural e a IA os extrai automaticamente.
How to scrape with AI:
- Descreva o que você precisa: Diga à IA quais dados você quer extrair de Open Collective. Apenas digite em linguagem natural — sem código ou seletores.
- A IA extrai os dados: Nossa inteligência artificial navega Open Collective, lida com conteúdo dinâmico e extrai exatamente o que você pediu.
- Obtenha seus dados: Receba dados limpos e estruturados prontos para exportar como CSV, JSON ou enviar diretamente para seus aplicativos.
Why use AI for scraping:
- Extração Visual de Dados: Extraia registros financeiros complexos e tabelas de contribuidores usando uma interface de apontar e clicar sem escrever nenhuma lógica de consulta GraphQL.
- Gerenciamento Inteligente de Paginação: Lide automaticamente com rolagem infinita ou botões 'Carregar Mais' para garantir que cada despesa ou doação seja capturada do livro contábil.
- Agendamentos de Monitoramento Automatizados: Configure um bot recorrente para extrair dados a cada 24 horas, garantindo que você sempre tenha o saldo e os registros de transações mais atualizados.
- Contornar Medidas Anti-Bot: Utilize a rotação de IP integrada e recursos de interação humana para evitar ser sinalizado pelo Cloudflare ao fazer scraping em escala.
- Exportação Direta para JSON/CSV: Transforme instantaneamente dados brutos da web em formatos estruturados prontos para análise no Google Sheets, Excel ou bancos de dados internos.
Scrapers Web No-Code para Open Collective
Alternativas point-and-click ao scraping com IA
Várias ferramentas no-code como Browse.ai, Octoparse, Axiom e ParseHub podem ajudá-lo a fazer scraping de Open Collective sem escrever código. Essas ferramentas usam interfaces visuais para selecionar dados, embora possam ter dificuldades com conteúdo dinâmico complexo ou medidas anti-bot.
Workflow Típico com Ferramentas No-Code
Desafios Comuns
Curva de aprendizado
Compreender seletores e lógica de extração leva tempo
Seletores quebram
Mudanças no site podem quebrar todo o fluxo de trabalho
Problemas com conteúdo dinâmico
Sites com muito JavaScript requerem soluções complexas
Limitações de CAPTCHA
A maioria das ferramentas requer intervenção manual para CAPTCHAs
Bloqueio de IP
Scraping agressivo pode resultar no bloqueio do seu IP
Scrapers Web No-Code para Open Collective
Várias ferramentas no-code como Browse.ai, Octoparse, Axiom e ParseHub podem ajudá-lo a fazer scraping de Open Collective sem escrever código. Essas ferramentas usam interfaces visuais para selecionar dados, embora possam ter dificuldades com conteúdo dinâmico complexo ou medidas anti-bot.
Workflow Típico com Ferramentas No-Code
- Instalar extensão do navegador ou registrar-se na plataforma
- Navegar até o site alvo e abrir a ferramenta
- Selecionar com point-and-click os elementos de dados a extrair
- Configurar seletores CSS para cada campo de dados
- Configurar regras de paginação para scraping de múltiplas páginas
- Resolver CAPTCHAs (frequentemente requer intervenção manual)
- Configurar agendamento para execuções automáticas
- Exportar dados para CSV, JSON ou conectar via API
Desafios Comuns
- Curva de aprendizado: Compreender seletores e lógica de extração leva tempo
- Seletores quebram: Mudanças no site podem quebrar todo o fluxo de trabalho
- Problemas com conteúdo dinâmico: Sites com muito JavaScript requerem soluções complexas
- Limitações de CAPTCHA: A maioria das ferramentas requer intervenção manual para CAPTCHAs
- Bloqueio de IP: Scraping agressivo pode resultar no bloqueio do seu IP
Exemplos de Código
import requests
# O endpoint GraphQL do Open Collective
url = 'https://api.opencollective.com/graphql/v2'
# Consulta GraphQL para obter informações básicas sobre um coletivo
query = '''
query {
collective(slug: "webpack") {
name
stats {
totalAmountReceived { value }
balance { value }
}
}
}
'''
headers = {'Content-Type': 'application/json'}
try:
# Enviando requisição POST para a API
response = requests.post(url, json={'query': query}, headers=headers)
response.raise_for_status()
data = response.json()
# Extraindo e imprimindo o nome e o saldo
collective = data['data']['collective']
print(f"Nome: {collective['name']}")
print(f"Saldo: {collective['stats']['balance']['value']}")
except Exception as e:
print(f"Ocorreu um erro: {e}")Quando Usar
Ideal para páginas HTML estáticas com JavaScript mínimo. Perfeito para blogs, sites de notícias e páginas de produtos e-commerce simples.
Vantagens
- ●Execução mais rápida (sem overhead do navegador)
- ●Menor consumo de recursos
- ●Fácil de paralelizar com asyncio
- ●Ótimo para APIs e páginas estáticas
Limitações
- ●Não pode executar JavaScript
- ●Falha em SPAs e conteúdo dinâmico
- ●Pode ter dificuldades com sistemas anti-bot complexos
Como Fazer Scraping de Open Collective com Código
Python + Requests
import requests
# O endpoint GraphQL do Open Collective
url = 'https://api.opencollective.com/graphql/v2'
# Consulta GraphQL para obter informações básicas sobre um coletivo
query = '''
query {
collective(slug: "webpack") {
name
stats {
totalAmountReceived { value }
balance { value }
}
}
}
'''
headers = {'Content-Type': 'application/json'}
try:
# Enviando requisição POST para a API
response = requests.post(url, json={'query': query}, headers=headers)
response.raise_for_status()
data = response.json()
# Extraindo e imprimindo o nome e o saldo
collective = data['data']['collective']
print(f"Nome: {collective['name']}")
print(f"Saldo: {collective['stats']['balance']['value']}")
except Exception as e:
print(f"Ocorreu um erro: {e}")Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_opencollective():
with sync_playwright() as p:
# Lançando o browser com suporte a JS
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://opencollective.com/discover')
# Aguarda o carregamento dos cards dos coletivos
page.wait_for_selector('.CollectiveCard')
# Extrai dados do DOM
collectives = page.query_selector_all('.CollectiveCard')
for c in collectives:
name = c.query_selector('h2').inner_text()
print(f'Projeto encontrado: {name}')
browser.close()
scrape_opencollective()Python + Scrapy
import scrapy
import json
class OpenCollectiveSpider(scrapy.Spider):
name = 'opencollective'
start_urls = ['https://opencollective.com/webpack']
def parse(self, response):
# O Open Collective usa Next.js; os dados geralmente estão dentro de uma tag script
next_data = response.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
if next_data:
parsed_data = json.loads(next_data)
collective = parsed_data['props']['pageProps']['collective']
yield {
'name': collective.get('name'),
'balance': collective.get('stats', {}).get('balance'),
'currency': collective.get('currency')
}Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://opencollective.com/discover');
// Aguarda o carregamento do conteúdo dinâmico
await page.waitForSelector('.CollectiveCard');
// Mapeia os elementos para extrair nomes
const data = await page.evaluate(() => {
return Array.from(document.querySelectorAll('.CollectiveCard')).map(el => ({
name: el.querySelector('h2').innerText
}));
});
console.log(data);
await browser.close();
})();O Que Você Pode Fazer Com Os Dados de Open Collective
Explore aplicações práticas e insights dos dados de Open Collective.
Previsão de Crescimento Open-source
Identifique tecnologias em tendência rastreando as taxas de crescimento financeiro de categorias coletivas específicas.
Como implementar:
- 1Extrair a receita mensal para os principais projetos em tags específicas
- 2Calcular as taxas de crescimento anual compostas (CAGR)
- 3Visualizar a saúde financeira do projeto para prever a adoção de tecnologia
Use Automatio para extrair dados de Open Collective e construir essas aplicações sem escrever código.
O Que Você Pode Fazer Com Os Dados de Open Collective
- Previsão de Crescimento Open-source
Identifique tecnologias em tendência rastreando as taxas de crescimento financeiro de categorias coletivas específicas.
- Extrair a receita mensal para os principais projetos em tags específicas
- Calcular as taxas de crescimento anual compostas (CAGR)
- Visualizar a saúde financeira do projeto para prever a adoção de tecnologia
- Geração de Leads para SaaS
Identifique projetos bem financiados que podem precisar de ferramentas de desenvolvedor, hospedagem ou serviços profissionais.
- Filtrar coletivos por orçamento e valor total arrecadado
- Extrair descrições de projetos e URLs de sites externos
- Verificar o stack tecnológico através de repositórios vinculados no GitHub
- Auditoria de Filantropia Corporativa
Acompanhe onde as grandes corporações estão gastando seus orçamentos de contribuição open-source.
- Extrair listas de contribuidores para os principais projetos
- Filtrar perfis organizacionais vs perfis individuais
- Agregar valores de contribuição por entidade corporativa
- Pesquisa de Impacto Comunitário
Analise como grupos descentralizados distribuem seus fundos para entender o impacto social.
- Extrair o livro-razão completo de transações para um coletivo específico
- Categorizar despesas (viagens, salários, hardware)
- Gerar relatórios sobre a alocação de recursos dentro de grupos comunitários
- Pipeline de Recrutamento de Desenvolvedores
Encontre líderes ativos em ecossistemas específicos com base em sua gestão comunitária e histórico de contribuições.
- Extrair listas de membros de coletivos técnicos importantes
- Cruzar referências de contribuidores com seus perfis sociais públicos
- Identificar mantenedores ativos para abordagens de alto nível
Potencialize seu fluxo de trabalho com Automacao de IA
Automatio combina o poder de agentes de IA, automacao web e integracoes inteligentes para ajuda-lo a realizar mais em menos tempo.
Dicas Pro para Scraping de Open Collective
Dicas de especialistas para extrair dados com sucesso de Open Collective.
Extrair via URL Slugs
A maneira mais fácil de segmentar coletivos específicos é usar seus URL slugs exclusivos, que podem ser coletados na página principal de descoberta.
Verificar por __NEXT_DATA__
O código-fonte da página geralmente contém uma tag de script com o ID __NEXT_DATA__ que contém JSON pré-renderizado, o que pode ser mais rápido do que fazer scraping da interface do usuário.
Usar Seletores 'data-cy'
Direcione os atributos 'data-cy' em seus seletores, pois são IDs de teste que permanecem estáveis mesmo quando as classes CSS mudam durante as atualizações do site.
Monitorar Requisições XHR
Use as ferramentas de desenvolvedor do navegador para encontrar as chamadas diretas do endpoint GraphQL, pois elas fornecem a estrutura de dados mais limpa para transações financeiras.
Implementar Delays Aleatórios
Adicione tempos de espera aleatórios entre 2 e 6 segundos para imitar a navegação natural e permanecer fora do radar da detecção automatizada de bots.
Aproveitar a Documentação Oficial
Revise a documentação da API GraphQL do Open Collective para entender as convenções de nomenclatura para diferentes campos de dados financeiros.
Depoimentos
O Que Nossos Usuarios Dizem
Junte-se a milhares de usuarios satisfeitos que transformaram seu fluxo de trabalho
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relacionados Web Scraping
How to Scrape Moon.ly | Step-by-Step NFT Data Extraction Guide
How to Scrape Yahoo Finance: Extract Stock Market Data
How to Scrape Rocket Mortgage: A Comprehensive Guide
How to Scrape jup.ag: Jupiter DEX Web Scraper Guide
How to Scrape Indiegogo: The Ultimate Crowdfunding Data Extraction Guide
How to Scrape ICO Drops: Comprehensive Crypto Data Guide
How to Scrape Crypto.com: Comprehensive Market Data Guide
How to Scrape Coinpaprika: Crypto Market Data Extraction Guide
Perguntas Frequentes Sobre Open Collective
Encontre respostas para perguntas comuns sobre Open Collective