Как парсить Web Designer News
Узнайте, как парсить Web Designer News для извлечения трендовых новостей дизайна, URL источников и временных меток. Идеально для мониторинга трендов и...
О Web Designer News
Узнайте, что предлагает Web Designer News и какие ценные данные можно извлечь.
Обзор Web Designer News
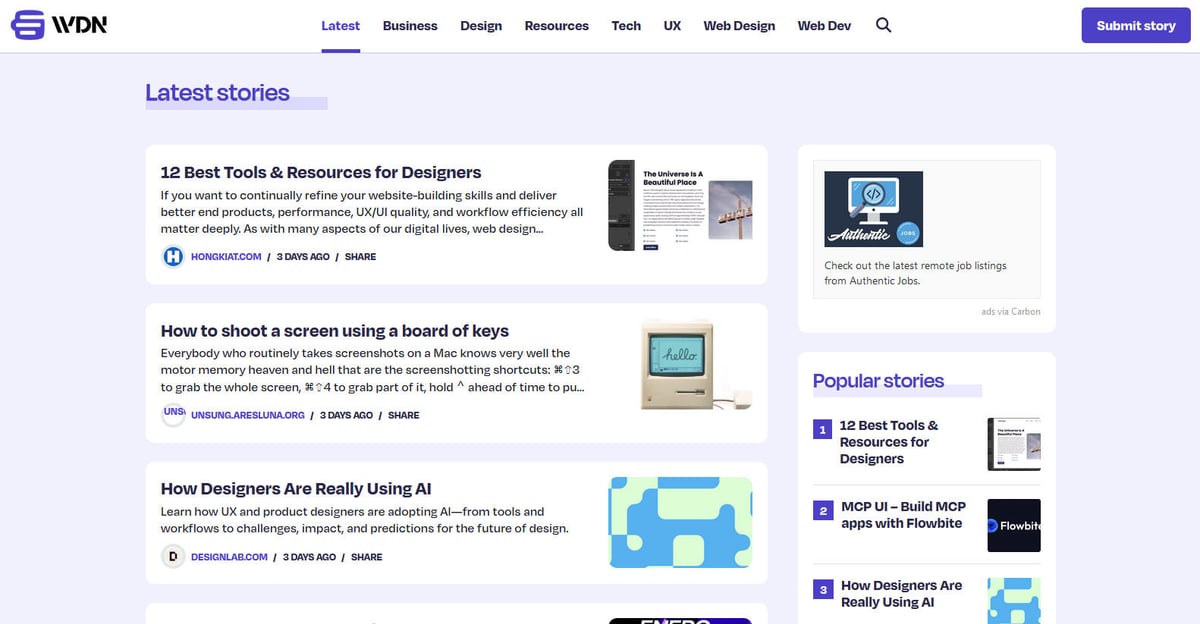
Web Designer News — это ведущий новостной агрегатор, управляемый сообществом и созданный специально для экосистемы веб-дизайна и разработки. С момента своего основания платформа служит центральным хабом, где профессионалы находят тщательно отобранные новости, туториалы, инструменты и ресурсы со всего интернета. Она охватывает широкий спектр тем, включая UX-дизайн, бизнес-стратегии, технологические обновления и графический дизайн, представленные в виде чистой хронологической ленты.
Архитектура сайта и потенциал данных
Архитектура веб-сайта построена на WordPress и имеет четко структурированную разметку, которая организует контент по категориям, таким как «Web Design», «Web Dev», «UX» и «Resources». Благодаря агрегации данных из тысяч отдельных блогов и журналов в единый интерфейс с возможностью поиска, сайт выступает в роли высококачественного фильтра отраслевой информации. Такая структура делает его идеальным объектом для веб-скрейпинга, предоставляя доступ к проверенному потоку ценных отраслевых данных без необходимости обхода сотен отдельных доменов.
Зачем Парсить Web Designer News?
Узнайте о бизнес-ценности и сценариях использования извлечения данных из Web Designer News.
Выявление новых трендов и инструментов в дизайне в режиме реального времени.
Автоматизация курирования отраслевых новостей для рассылок и лент в социальных сетях.
Проведение конкурентного анализа путем мониторинга контента соперников.
Генерация качественных наборов данных для обучения моделей Natural Language Processing (NLP).
Создание централизованной библиотеки ресурсов для внутренних баз знаний команд.
Проблемы При Парсинге
Технические проблемы, с которыми вы можете столкнуться при парсинге Web Designer News.
Обработка технических редиректов через систему внутренних ссылок 'go'.
Непостоянное наличие миниатюр изображений в старых архивных записях.
Ограничение частоты запросов (rate limiting) на стороне сервера через защиту Nginx.
Скрапинг Web Designer News с помощью ИИ
Код не нужен. Извлекайте данные за минуты с автоматизацией на базе ИИ.
Как это работает
Опишите, что вам нужно
Расскажите ИИ, какие данные вы хотите извлечь из Web Designer News. Просто напишите на обычном языке — без кода и селекторов.
ИИ извлекает данные
Наш искусственный интеллект навигирует по Web Designer News, обрабатывает динамический контент и извлекает именно то, что вы запросили.
Получите ваши данные
Получите чистые, структурированные данные, готовые к экспорту в CSV, JSON или отправке напрямую в ваши приложения.
Почему стоит использовать ИИ для скрапинга
ИИ упрощает скрапинг Web Designer News без написания кода. Наша платформа на базе искусственного интеллекта понимает, какие данные вам нужны — просто опишите их на обычном языке, и ИИ извлечёт их автоматически.
How to scrape with AI:
- Опишите, что вам нужно: Расскажите ИИ, какие данные вы хотите извлечь из Web Designer News. Просто напишите на обычном языке — без кода и селекторов.
- ИИ извлекает данные: Наш искусственный интеллект навигирует по Web Designer News, обрабатывает динамический контент и извлекает именно то, что вы запросили.
- Получите ваши данные: Получите чистые, структурированные данные, готовые к экспорту в CSV, JSON или отправке напрямую в ваши приложения.
Why use AI for scraping:
- Полный no-code процесс для дизайнеров и маркетологов без технических навыков.
- Облачное планирование задач позволяет ежедневно извлекать новости в автоматическом режиме.
- Встроенная обработка пагинации и автоматическое обнаружение структурированных элементов.
- Прямая интеграция с Google Sheets для мгновенного распределения данных.
No-Code Парсеры для Web Designer News
Point-and-click альтернативы AI-парсингу
Несколько no-code инструментов, таких как Browse.ai, Octoparse, Axiom и ParseHub, могут помочь парсить Web Designer News без написания кода. Эти инструменты используют визуальные интерфейсы для выбора данных, хотя могут иметь проблемы со сложным динамическим контентом или антибот-защитой.
Типичный Рабочий Процесс с No-Code Инструментами
Частые Проблемы
Кривая обучения
Понимание селекторов и логики извлечения требует времени
Селекторы ломаются
Изменения на сайте могут сломать весь рабочий процесс
Проблемы с динамическим контентом
Сайты с большим количеством JavaScript требуют сложных обходных путей
Ограничения CAPTCHA
Большинство инструментов требуют ручного вмешательства для CAPTCHA
Блокировка IP
Агрессивный парсинг может привести к блокировке вашего IP
No-Code Парсеры для Web Designer News
Несколько no-code инструментов, таких как Browse.ai, Octoparse, Axiom и ParseHub, могут помочь парсить Web Designer News без написания кода. Эти инструменты используют визуальные интерфейсы для выбора данных, хотя могут иметь проблемы со сложным динамическим контентом или антибот-защитой.
Типичный Рабочий Процесс с No-Code Инструментами
- Установить расширение браузера или зарегистрироваться на платформе
- Перейти на целевой сайт и открыть инструмент
- Выбрать элементы данных для извлечения методом point-and-click
- Настроить CSS-селекторы для каждого поля данных
- Настроить правила пагинации для парсинга нескольких страниц
- Обработать CAPTCHA (часто требуется ручное решение)
- Настроить расписание для автоматических запусков
- Экспортировать данные в CSV, JSON или подключить через API
Частые Проблемы
- Кривая обучения: Понимание селекторов и логики извлечения требует времени
- Селекторы ломаются: Изменения на сайте могут сломать весь рабочий процесс
- Проблемы с динамическим контентом: Сайты с большим количеством JavaScript требуют сложных обходных путей
- Ограничения CAPTCHA: Большинство инструментов требуют ручного вмешательства для CAPTCHA
- Блокировка IP: Агрессивный парсинг может привести к блокировке вашего IP
Примеры кода
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Отправка запроса на главную страницу
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Поиск контейнеров постов
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Проверка наличия названия сайта-источника
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Заголовок: {title} | Источник: {source} | Ссылка: {link}')
except Exception as e:
print(f'Произошла ошибка: {e}')Когда Использовать
Лучше всего для статических HTML-страниц с минимальным JavaScript. Идеально для блогов, новостных сайтов и простых страниц товаров электронной коммерции.
Преимущества
- ●Самое быстрое выполнение (без нагрузки браузера)
- ●Минимальное потребление ресурсов
- ●Легко распараллелить с asyncio
- ●Отлично для API и статических страниц
Ограничения
- ●Не может выполнять JavaScript
- ●Не работает на SPA и динамическом контенте
- ●Может иметь проблемы со сложными антибот-системами
Как парсить Web Designer News с помощью кода
Python + Requests
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Отправка запроса на главную страницу
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Поиск контейнеров постов
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Проверка наличия названия сайта-источника
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Заголовок: {title} | Источник: {source} | Ссылка: {link}')
except Exception as e:
print(f'Произошла ошибка: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_wdn():
with sync_playwright() as p:
# Запуск headless browser
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://webdesignernews.com/')
# Ожидание загрузки элементов постов
page.wait_for_selector('.single-post')
posts = page.query_selector_all('.single-post')
for post in posts:
title_el = post.query_selector('h3 a')
if title_el:
title = title_el.inner_text()
link = title_el.get_attribute('href')
print(f'Собрано: {title} - {link}')
browser.close()
scrape_wdn()Python + Scrapy
import scrapy
class WdnSpider(scrapy.Spider):
name = 'wdn_spider'
start_urls = ['https://webdesignernews.com/']
def parse(self, response):
# Извлекаем каждый пост из ленты
for post in response.css('.single-post'):
yield {
'title': post.css('h3 a::text').get(),
'source': post.css('.site_name::text').get(),
'link': post.css('h3 a::attr(href)').get()
}
# Обрабатываем пагинацию, находя ссылку 'Next'
next_page = response.css('a.next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://webdesignernews.com/', { waitUntil: 'domcontentloaded' });
// Оцениваем страницу для извлечения полей данных
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.single-post'));
return items.map(item => ({
title: item.querySelector('h3 a') ? item.querySelector('h3 a').innerText : null,
source: item.querySelector('.site_name') ? item.querySelector('.site_name').innerText : null,
link: item.querySelector('h3 a') ? item.querySelector('h3 a').href : null
}));
});
console.log(results);
await browser.close();
})();Что Можно Делать С Данными Web Designer News
Изучите практические применения и инсайты из данных Web Designer News.
Автоматизированная лента новостей дизайна
Создайте живой курируемый канал новостей для профессиональных команд дизайнеров через Slack или Discord.
Как реализовать:
- 1Парсите самые популярные истории каждые 4 часа.
- 2Фильтруйте результаты по релевантным тегам категорий, таким как 'UX' или 'Web Dev'.
- 3Отправляйте извлеченные заголовки и краткие описания в вебхук мессенджера.
- 4Архивируйте данные для отслеживания долгосрочной популярности отраслевых инструментов.
Используйте Automatio для извлечения данных из Web Designer News и создания этих приложений без написания кода.
Что Можно Делать С Данными Web Designer News
- Автоматизированная лента новостей дизайна
Создайте живой курируемый канал новостей для профессиональных команд дизайнеров через Slack или Discord.
- Парсите самые популярные истории каждые 4 часа.
- Фильтруйте результаты по релевантным тегам категорий, таким как 'UX' или 'Web Dev'.
- Отправляйте извлеченные заголовки и краткие описания в вебхук мессенджера.
- Архивируйте данные для отслеживания долгосрочной популярности отраслевых инструментов.
- Трекер трендов инструментов дизайна
Определите, какое программное обеспечение или библиотеки для дизайна набирают наибольшую популярность в сообществе.
- Извлеките заголовки и анонсы из архива категории 'Resources'.
- Проведите частотный анализ ключевых слов для конкретных терминов (например, 'Figma', 'React').
- Сравните рост упоминаний месяц к месяцу для выявления новых трендов.
- Экспортируйте визуальные отчеты для отделов маркетинга или продуктовой стратегии.
- Мониторинг обратных ссылок конкурентов
Узнайте, какие блоги или агентства успешно размещают свой контент на крупнейших хабах.
- Соберите данные из поля 'Source Website Name' для всех исторических записей.
- Агрегируйте количество упоминаний для каждого внешнего домена, чтобы увидеть наиболее цитируемые ресурсы.
- Анализируйте типы контента, которые проходят модерацию, для улучшения охвата.
- Выявите потенциальных партнеров для сотрудничества в сфере дизайна.
- Набор данных для обучения Machine Learning
Используйте курируемые сниппеты и саммари для обучения моделей технического реферирования.
- Соберите более 10 000 заголовков статей и соответствующих кратких анонсов.
- Очистите текстовые данные от параметров отслеживания и HTML.
- Используйте заголовок как целевой результат, а анонс — как входные данные для fine-tuning.
- Протестируйте model на новых статьях о дизайне для оценки производительности.
Улучшите свой рабочий процесс с ИИ-Автоматизацией
Automatio объединяет мощь ИИ-агентов, веб-автоматизации и умных интеграций, чтобы помочь вам достигать большего за меньшее время.
Советы Профессионала По Парсингу Web Designer News
Экспертные советы для успешного извлечения данных из Web Designer News.
Используйте эндпоинт WordPress REST API (/wp-json/wp/v2/posts) для более быстрого и надежного получения структурированных данных по сравнению с парсингом HTML.
Отслеживайте RSS-фид сайта по адресу webdesignernews.com/feed/, чтобы фиксировать новые истории в момент их публикации.
Планируйте задачи парсинга на 9
00 AM EST, чтобы попасть на ежедневный пик публикации контента от сообщества.
Настройте ротацию User-Agent и установите задержку в 2 секунды между запросами, чтобы не срабатывали лимиты Nginx.
Всегда разрешайте внутренние ссылки «/go/», следуя по редиректам, чтобы извлечь конечный канонический URL источника.
Очищайте текстовые данные анонсов, удаляя теги HTML и многоточия в конце, для получения более качественных результатов анализа.
Отзывы
Что Говорят Наши Пользователи
Присоединяйтесь к тысячам довольных пользователей, которые трансформировали свой рабочий процесс
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Похожие Web Scraping




Часто задаваемые вопросы о Web Designer News
Найдите ответы на частые вопросы о Web Designer News