Si të bëni Scraping në Web Designer News
Mësoni si të bëni scraping në Web Designer News për të nxjerrë histori trendi të dizajnit, URL burimore dhe vula kohore. Ideale për monitorimin e trendeve të...
Rreth Web Designer News
Zbuloni çfarë ofron Web Designer News dhe cilat të dhëna të vlefshme mund të nxirren.
Përmbledhje e Web Designer News
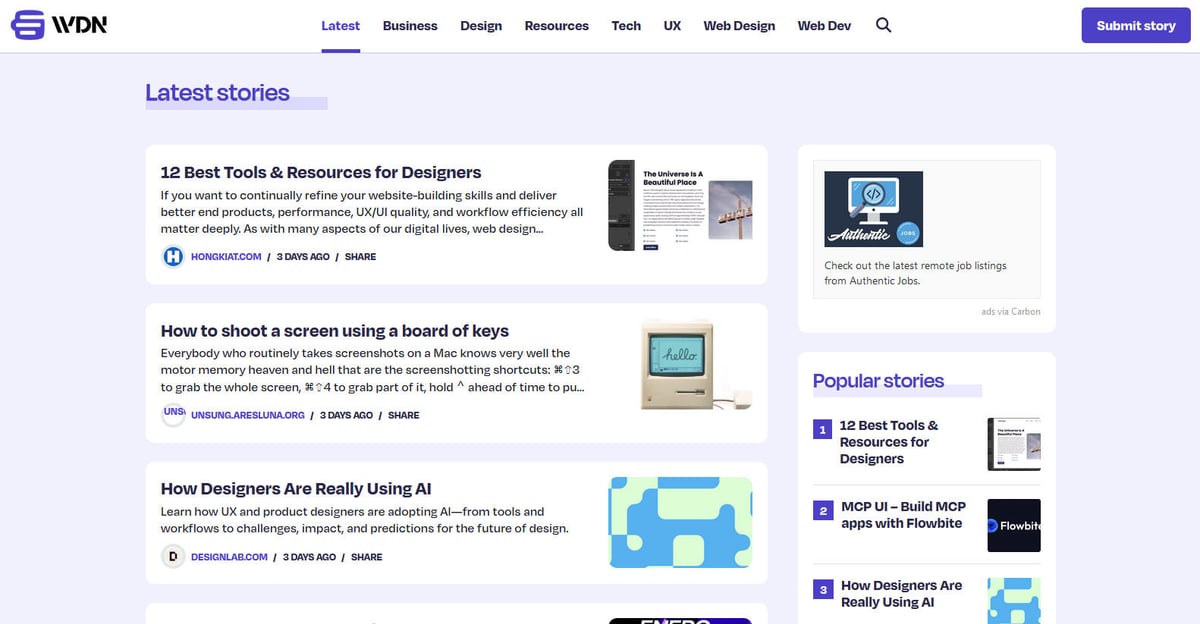
Web Designer News është një agregator parësor lajmesh i drejtuar nga komuniteti, i kuruar posaçërisht për ekosistemin e dizajnit dhe zhvillimit web. Që nga fillimi i tij, platforma ka funksionuar si një qendër qendrore ku profesionistët zbulojnë një përzgjedhje të zgjedhur me dorë të historive më relevante, tutorialeve, veglave dhe burimeve nga i gjithë interneti. Ai mbulon një spektër të gjerë temash, duke përfshirë UX design, strategjinë e biznesit, përditësimet teknologjike dhe dizajnin grafik, të paraqitura në një feed të pastër kronologjik.
Arkitektura e Faqes dhe Potenciali i të Dhënave
Arkitektura e faqes është ndërtuar mbi WordPress, duke paraqitur një strukturë shumë të organizuar që kategorizon përmbajtjen në kategori specifike si 'Web Design', 'Web Dev', 'UX' dhe 'Resources'. Pasi agregon të dhëna nga mijëra blogje dhe revista individuale në një ndërfaqe të vetme të kërkueshme, ai shërben si një filtër i cilësisë së lartë për inteligjencën e industrisë. Kjo strukturë e bën atë një objekt ideal për web scraping, pasi ofron akses në një rrymë të dhënash të vlerësueshme të industrisë, të verifikuara paraprakisht, pa pasur nevojë për të bërë crawl në qindra domene të veçanta.
Pse Të Bëni Scraping Web Designer News?
Zbuloni vlerën e biznesit dhe rastet e përdorimit për nxjerrjen e të dhënave nga Web Designer News.
Identifikoni trendet dhe veglat e reja të dizajnit në kohë reale.
Automatizoni kurimin e lajmeve të industrisë për newsletter dhe feed-et e rrjeteve sociale.
Kryeni analizë konkurruese duke monitoruar përmbajtjen e paraqitur nga rivalët.
Gjeneroni datasets të cilësisë së lartë për trajnimin e Natural Language Processing (NLP).
Ndërtoni një librari qendrore të burimeve të dizajnit për bazat e njohurive të ekipit të brendshëm.
Sfidat e Scraping
Sfidat teknike që mund të hasni gjatë scraping të Web Designer News.
Trajtimi i redirektimeve teknike përmes sistemit të link-eve të brendshme 'go' të faqes.
Disponueshmëria jo e qëndrueshme e imazheve thumbnail në postimet më të vjetra të arkivuara.
Rate limiting në anën e serverit për kërkesat me frekuencë të lartë përmes mbrojtjes Nginx.
Nxirr të dhëna nga Web Designer News me AI
Pa nevojë për kod. Nxirrni të dhëna në minuta me automatizimin e bazuar në AI.
Si funksionon
Përshkruani çfarë ju nevojitet
Tregojini AI-së çfarë të dhënash dëshironi të nxirrni nga Web Designer News. Thjesht shkruajeni në gjuhë natyrale — pa nevojë për kod apo selektorë.
AI nxjerr të dhënat
Inteligjenca jonë artificiale lundron Web Designer News, përpunon përmbajtjen dinamike dhe nxjerr saktësisht atë që kërkuat.
Merrni të dhënat tuaja
Merrni të dhëna të pastra dhe të strukturuara gati për eksport si CSV, JSON ose për t'i dërguar drejtpërdrejt te aplikacionet tuaja.
Pse të përdorni AI për nxjerrjen e të dhënave
AI e bën të lehtë nxjerrjen e të dhënave nga Web Designer News pa shkruar kod. Platforma jonë e bazuar në inteligjencë artificiale kupton çfarë të dhënash dëshironi — thjesht përshkruajini në gjuhë natyrale dhe AI i nxjerr automatikisht.
How to scrape with AI:
- Përshkruani çfarë ju nevojitet: Tregojini AI-së çfarë të dhënash dëshironi të nxirrni nga Web Designer News. Thjesht shkruajeni në gjuhë natyrale — pa nevojë për kod apo selektorë.
- AI nxjerr të dhënat: Inteligjenca jonë artificiale lundron Web Designer News, përpunon përmbajtjen dinamike dhe nxjerr saktësisht atë që kërkuat.
- Merrni të dhënat tuaja: Merrni të dhëna të pastra dhe të strukturuara gati për eksport si CSV, JSON ose për t'i dërguar drejtpërdrejt te aplikacionet tuaja.
Why use AI for scraping:
- Workflow i plotë no-code për dizajnerët dhe marketerët jo-teknikë.
- Programimi i bazuar në cloud mundëson nxjerrjen e lajmeve ditore pa ndërhyrje manuale.
- Trajtim i integruar i faqëzimit dhe detektimit të elementeve të strukturuara.
- Integrim direkt me Google Sheets për shpërndarje të menjëhershme të të dhënave.
Web Scraper Pa Kod për Web Designer News
Alternativa klikoni-dhe-zgjidhni për scraping të fuqizuar nga AI
Disa mjete pa kod si Browse.ai, Octoparse, Axiom dhe ParseHub mund t'ju ndihmojnë të bëni scraping Web Designer News pa shkruar kod. Këto mjete zakonisht përdorin ndërfaqe vizuale për të zgjedhur të dhënat, edhe pse mund të kenë vështirësi me përmbajtje dinamike komplekse ose masa anti-bot.
Rrjedha Tipike e Punës me Mjete Pa Kod
Sfida të Zakonshme
Kurba e të mësuarit
Kuptimi i selektorëve dhe logjikës së nxjerrjes kërkon kohë
Selektorët prishen
Ndryshimet e faqes mund të prishin të gjithë rrjedhën e punës
Probleme me përmbajtje dinamike
Faqet me shumë JavaScript kërkojnë zgjidhje komplekse
Kufizimet e CAPTCHA
Shumica e mjeteve kërkojnë ndërhyrje manuale për CAPTCHA
Bllokimi i IP
Scraping agresiv mund të çojë në bllokimin e IP-së tuaj
Web Scraper Pa Kod për Web Designer News
Disa mjete pa kod si Browse.ai, Octoparse, Axiom dhe ParseHub mund t'ju ndihmojnë të bëni scraping Web Designer News pa shkruar kod. Këto mjete zakonisht përdorin ndërfaqe vizuale për të zgjedhur të dhënat, edhe pse mund të kenë vështirësi me përmbajtje dinamike komplekse ose masa anti-bot.
Rrjedha Tipike e Punës me Mjete Pa Kod
- Instaloni shtesën e shfletuesit ose regjistrohuni në platformë
- Navigoni në faqen e internetit të synuar dhe hapni mjetin
- Zgjidhni elementet e të dhënave për nxjerrje me point-and-click
- Konfiguroni selektorët CSS për çdo fushë të dhënash
- Vendosni rregullat e faqosjes për të scrape faqe të shumta
- Menaxhoni CAPTCHA (shpesh kërkon zgjidhje manuale)
- Konfiguroni planifikimin për ekzekutime automatike
- Eksportoni të dhënat në CSV, JSON ose lidhuni përmes API
Sfida të Zakonshme
- Kurba e të mësuarit: Kuptimi i selektorëve dhe logjikës së nxjerrjes kërkon kohë
- Selektorët prishen: Ndryshimet e faqes mund të prishin të gjithë rrjedhën e punës
- Probleme me përmbajtje dinamike: Faqet me shumë JavaScript kërkojnë zgjidhje komplekse
- Kufizimet e CAPTCHA: Shumica e mjeteve kërkojnë ndërhyrje manuale për CAPTCHA
- Bllokimi i IP: Scraping agresiv mund të çojë në bllokimin e IP-së tuaj
Shembuj kodesh
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Dërgo kërkesën në faqen kryesore
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Lokalizo kontinerët e postimeve
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Kontrollo nëse emri i faqes burimore ekziston
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Titulli: {title} | Burimi: {source} | Link: {link}')
except Exception as e:
print(f'Ndodhi një gabim: {e}')Kur të Përdoret
Më e mira për faqe HTML statike ku përmbajtja ngarkohet në anën e serverit. Qasja më e shpejtë dhe më e thjeshtë kur renderimi i JavaScript nuk është i nevojshëm.
Avantazhet
- ●Ekzekutimi më i shpejtë (pa overhead të shfletuesit)
- ●Konsumi më i ulët i burimeve
- ●E lehtë për tu paralelizuar me asyncio
- ●E shkëlqyer për API dhe faqe statike
Kufizimet
- ●Nuk mund të ekzekutojë JavaScript
- ●Dështon në SPA dhe përmbajtje dinamike
- ●Mund të ketë vështirësi me sisteme komplekse anti-bot
How to Scrape Web Designer News with Code
Python + Requests
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Dërgo kërkesën në faqen kryesore
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Lokalizo kontinerët e postimeve
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Kontrollo nëse emri i faqes burimore ekziston
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Titulli: {title} | Burimi: {source} | Link: {link}')
except Exception as e:
print(f'Ndodhi një gabim: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_wdn():
with sync_playwright() as p:
# Hap browser-in headless
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://webdesignernews.com/')
# Prit që elementet e postimit të ngarkohen
page.wait_for_selector('.single-post')
posts = page.query_selector_all('.single-post')
for post in posts:
title_el = post.query_selector('h3 a')
if title_el:
title = title_el.inner_text()
link = title_el.get_attribute('href')
print(f'Scraped: {title} - {link}')
browser.close()
scrape_wdn()Python + Scrapy
import scrapy
class WdnSpider(scrapy.Spider):
name = 'wdn_spider'
start_urls = ['https://webdesignernews.com/']
def parse(self, response):
# Ekstrakto çdo postim në feed
for post in response.css('.single-post'):
yield {
'title': post.css('h3 a::text').get(),
'source': post.css('.site_name::text').get(),
'link': post.css('h3 a::attr(href)').get()
}
# Trajto faqëzimin duke gjetur linkun 'Tjetër'
next_page = response.css('a.next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://webdesignernews.com/', { waitUntil: 'domcontentloaded' });
// Vlerëso faqen për të nxjerrë fushat e të dhënave
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.single-post'));
return items.map(item => ({
title: item.querySelector('h3 a') ? item.querySelector('h3 a').innerText : null,
source: item.querySelector('.site_name') ? item.querySelector('.site_name').innerText : null,
link: item.querySelector('h3 a') ? item.querySelector('h3 a').href : null
}));
});
console.log(results);
await browser.close();
})();Çfarë Mund Të Bëni Me Të Dhënat e Web Designer News
Eksploroni aplikacionet praktike dhe njohuritë nga të dhënat e Web Designer News.
Feed i Automatizuar i Lajmeve të Dizajnit
Krijoni një kanal lajmesh të kuruar live për ekipet profesionale të dizajnit përmes Slack ose Discord.
Si të implementohet:
- 1Bëni scraping të historive më të vlerësuara çdo 4 orë.
- 2Filtroni rezultatet sipas tag-eve përkatëse të kategorive si 'UX' ose 'Web Dev'.
- 3Dërgoni titujt dhe përmbledhjet e nxjerra në një webhook mesazhesh.
- 4Arkivoni të dhënat për të ndjekur popullaritetin afatgjatë të veglave të industrisë.
Përdorni Automatio për të nxjerrë të dhëna nga Web Designer News dhe ndërtoni këto aplikacione pa shkruar kod.
Çfarë Mund Të Bëni Me Të Dhënat e Web Designer News
- Feed i Automatizuar i Lajmeve të Dizajnit
Krijoni një kanal lajmesh të kuruar live për ekipet profesionale të dizajnit përmes Slack ose Discord.
- Bëni scraping të historive më të vlerësuara çdo 4 orë.
- Filtroni rezultatet sipas tag-eve përkatëse të kategorive si 'UX' ose 'Web Dev'.
- Dërgoni titujt dhe përmbledhjet e nxjerra në një webhook mesazhesh.
- Arkivoni të dhënat për të ndjekur popullaritetin afatgjatë të veglave të industrisë.
- Ndjekësi i Trendeve të Veglave të Dizajnit
Identifikoni cilat softuerë ose librari dizajni po fitojnë më shumë tërheqje në komunitet.
- Nxirrni titujt dhe ekstraktet nga arkiva e kategorisë 'Resources'.
- Kryeni analizën e frekuencës së fjalëve kyçe për terma specifikë (p.sh., 'Figma', 'React').
- Krahasoni rritjen e përmendjeve muaj pas muaji për të identifikuar trendet e reja.
- Eksportoni raporte vizuale për ekipet e marketingut ose strategjisë së produktit.
- Monitorimi i Backlink-eve të Konkurrentëve
Identifikoni cilat blogje ose agjenci po vendosin me sukses përmbajtje në qendrat kryesore.
- Bëni scraping të fushës 'Source Website Name' për të gjitha listimet historike.
- Agregoni numrin e përmendjeve për çdo domen të jashtëm për të parë kush shfaqet më shpesh.
- Analizoni llojet e përmbajtjes që pranohen për një outreach më të mirë.
- Identifikoni partnerë të mundshëm bashkëpunimi në hapësirën e dizajnit.
- Dataset Trajnimi për Machine Learning
Përdorni snippet-et dhe përmbledhjet e kuruara për të trajnuar modele të përmbledhjes teknike.
- Bëni scraping të mbi 10,000 titujve të historive dhe përmbledhjeve përkatëse.
- Pastroni të dhënat e tekstit për të hequr parametrat e gjurmimit të brendshëm dhe HTML.
- Përdorni titullin si objektiv dhe ekstraktin si input për fine-tuning.
- Testoni model-in në artikuj të rinj dizajni për performancën.
Superkariko workflow-n tend me automatizimin AI
Automatio kombinon fuqine e agjenteve AI, automatizimin e web-it dhe integrimet inteligjente per te te ndihmuar te arrish me shume ne me pak kohe.
Këshilla Pro Për Scraping të Web Designer News
Këshilla ekspertësh për nxjerrjen e suksesshme të të dhënave nga Web Designer News.
Synoni endpoint-in e WordPress REST API (/wp-json/wp/v2/posts) për të dhëna të strukturuara më të shpejta dhe më të besueshme sesa HTML parsing.
Monitoroni RSS feed-in e faqes në webdesignernews.com/feed/ për të kapur histori të reja në momentin që ato publikohen.
Programoni detyrat tuaja të scraping për në orën 9:00 AM EST për t'u përshtatur me kulmin ditor të përmbajtjes së dërguar nga komuniteti.
Rrotulloni string-et e User-Agent dhe zbatoni një vonesë prej 2 sekondash mes kërkesave për të shmangur aktivizimin e rate limits të Nginx.
Gjithmonë zgjidhni link-et e brendshme '/go/' duke ndjekur redirect-et për të nxjerrë URL-në përfundimtare burimore kanonike.
Pastroni të dhënat e tekstit të ekstraktit duke hequr tag-et HTML dhe pikat pezulluese në fund për rezultate më të mira analize.
Deshmi
Cfare thone perdoruesit tane
Bashkohu me mijera perdorues te kenaqur qe kane transformuar workflow-n e tyre
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Te lidhura Web Scraping




Pyetjet e bera shpesh rreth Web Designer News
Gjej pergjigje per pyetjet e zakonshme rreth Web Designer News