Hur du scrapar StubHub: Den ultimata guiden för web scraping
Lär dig hur du scrapar StubHub för biljettpriser i realtid, tillgänglighet för evenemang och platsdata. Upptäck hur du bypassar Akamai och extraherar...
Anti-bot-skydd upptäckt
- Akamai Bot Manager
- Avancerad botdetektering med enhetsfingeravtryck, beteendeanalys och maskininlärning. Ett av de mest sofistikerade anti-bot-systemen.
- PerimeterX (HUMAN)
- Beteendebiometri och prediktiv analys. Upptäcker automatisering genom musrörelser, skriveymönster och sidinteraktion.
- Cloudflare
- WAF och bothantering på företagsnivå. Använder JavaScript-utmaningar, CAPTCHA och beteendeanalys. Kräver webbläsarautomatisering med stealth-inställningar.
- Hastighetsbegränsning
- Begränsar förfrågningar per IP/session över tid. Kan kringgås med roterande proxyservrar, fördröjda förfrågningar och distribuerad skrapning.
- IP-blockering
- Blockerar kända datacenter-IP:er och flaggade adresser. Kräver bostads- eller mobilproxyservrar för effektiv kringgång.
- Webbläsarfingeravtryck
- Identifierar botar genom webbläsaregenskaper: canvas, WebGL, typsnitt, plugins. Kräver förfalskning eller riktiga webbläsarprofiler.
Om StubHub
Upptäck vad StubHub erbjuder och vilka värdefulla data som kan extraheras.
StubHub är världens största marknadsplats för andrahandsbiljetter och erbjuder en enorm plattform för fans att köpa och sälja biljetter till sport, konserter, teater och andra liveevenemang. Ägt av Viagogo fungerar det som en säker mellanhand som garanterar biljetternas äkthet och hanterar miljontals transaktioner globalt. Webbplatsen är en skattkista av dynamisk data, inklusive arenakartor, prisfluktuationer i realtid och lagernivåer.
För företag och analytiker är StubHub-data ovärderlig för att förstå marknadens efterfrågan och pristrender inom underhållningsbranschen. Eftersom plattformen speglar det sanna marknadsvärdet på biljetter (vilket ofta skiljer sig från det ursprungliga nominella värdet), fungerar den som en primär källa för konkurrensanalys, ekonomisk forskning och lagerhantering för biljettmäklare och arrangörer.
Scraping av denna plattform gör det möjligt att extrahera mycket detaljerad data, från specifika platsnummer till historiska prisändringar. Denna data hjälper organisationer att optimera sina egna prisstrategier, förutse populariteten för kommande turnéer och bygga omfattande prisjämförelseverktyg för konsumenter.
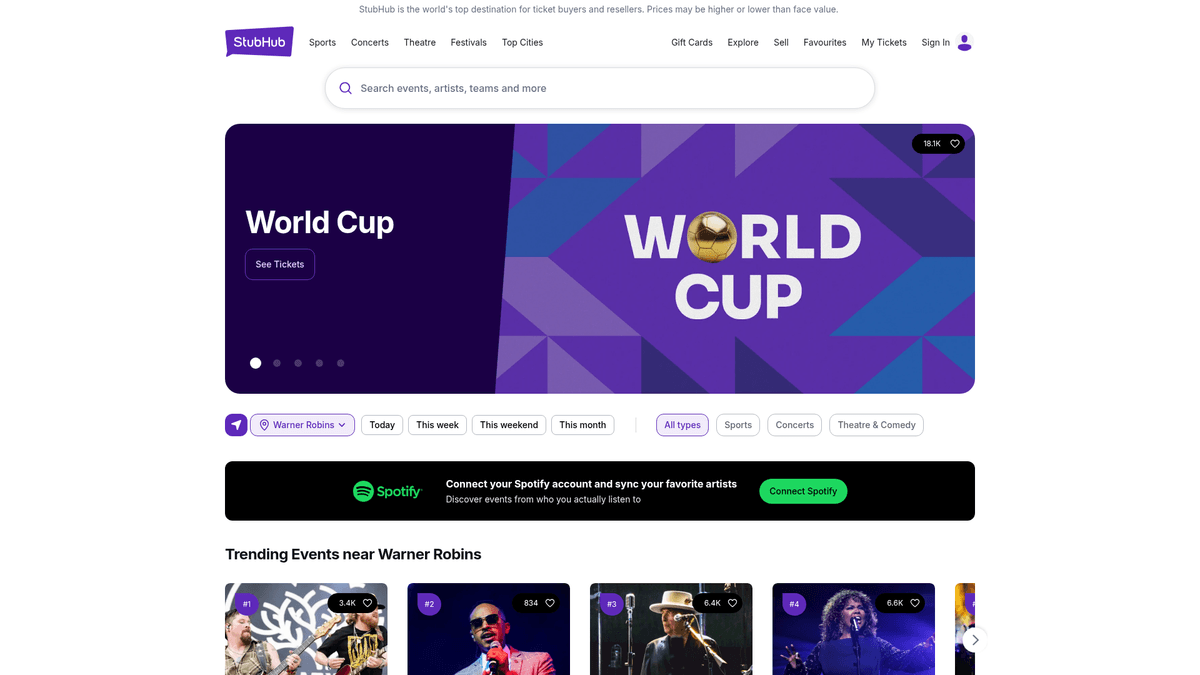
Varför Skrapa StubHub?
Upptäck affärsvärdet och användningsfallen för dataextraktion från StubHub.
Realtidsövervakning av prisfluktuationer på biljetter över olika arenor
Spårning av lagernivåer för att fastställa evenemangens försäljningsgrad
Konkurrensanalys mot andra andrahandsmarknader som SeatGeek eller Vivid Seats
Insamling av historisk prisdata för stora sportligor och konsertturnéer
Identifiering av arbitrage-möjligheter mellan primär- och andrahandsmarknader
Marknadsundersökningar för arrangörer för att mäta efterfrågan i specifika regioner
Skrapningsutmaningar
Tekniska utmaningar du kan stöta på när du skrapar StubHub.
Aggressivt anti-bot-skydd (Akamai) som identifierar och blockerar automatiserade webbläsarmönster
Omfattande användning av JavaScript och React för rendering av dynamiska listor och kartor
Frekventa ändringar i HTML-struktur och CSS-selektorer för att störa statiska scrapers
Strikt IP-baserad rate limiting som kräver användning av högkvalitativa residential proxies
Komplexa interaktioner med arenakartor som kräver sofistikerad webbläsarautomation
Skrapa StubHub med AI
Ingen kod krävs. Extrahera data på minuter med AI-driven automatisering.
Hur det fungerar
Beskriv vad du behöver
Berätta för AI vilka data du vill extrahera från StubHub. Skriv det bara på vanligt språk — ingen kod eller selektorer behövs.
AI extraherar datan
Vår artificiella intelligens navigerar StubHub, hanterar dynamiskt innehåll och extraherar exakt det du bad om.
Få dina data
Få ren, strukturerad data redo att exportera som CSV, JSON eller skicka direkt till dina appar och arbetsflöden.
Varför använda AI för skrapning
AI gör det enkelt att skrapa StubHub utan att skriva kod. Vår AI-drivna plattform använder artificiell intelligens för att förstå vilka data du vill ha — beskriv det bara på vanligt språk och AI extraherar dem automatiskt.
How to scrape with AI:
- Beskriv vad du behöver: Berätta för AI vilka data du vill extrahera från StubHub. Skriv det bara på vanligt språk — ingen kod eller selektorer behövs.
- AI extraherar datan: Vår artificiella intelligens navigerar StubHub, hanterar dynamiskt innehåll och extraherar exakt det du bad om.
- Få dina data: Få ren, strukturerad data redo att exportera som CSV, JSON eller skicka direkt till dina appar och arbetsflöden.
Why use AI for scraping:
- Bypassar enkelt avancerade anti-bot-åtgärder som Akamai och PerimeterX
- Hanterar komplex JavaScript-rendering och dynamiskt innehåll utan att skriva kod
- Automatiserar schemalagd datainsamling för dygnet-runt-övervakning av pris och lager
- Använder inbyggd proxy-rotation för att bibehålla höga framgångsgrader och undvika IP-spärrar
No-code webbskrapare för StubHub
Peka-och-klicka-alternativ till AI-driven skrapning
Flera no-code-verktyg som Browse.ai, Octoparse, Axiom och ParseHub kan hjälpa dig att skrapa StubHub utan att skriva kod. Dessa verktyg använder vanligtvis visuella gränssnitt för att välja data, även om de kan ha problem med komplext dynamiskt innehåll eller anti-bot-åtgärder.
Typiskt arbetsflöde med no-code-verktyg
Vanliga utmaningar
Inlärningskurva
Att förstå selektorer och extraktionslogik tar tid
Selektorer går sönder
Webbplatsändringar kan förstöra hela ditt arbetsflöde
Problem med dynamiskt innehåll
JavaScript-tunga sidor kräver komplexa lösningar
CAPTCHA-begränsningar
De flesta verktyg kräver manuell hantering av CAPTCHAs
IP-blockering
Aggressiv scraping kan leda till att din IP blockeras
No-code webbskrapare för StubHub
Flera no-code-verktyg som Browse.ai, Octoparse, Axiom och ParseHub kan hjälpa dig att skrapa StubHub utan att skriva kod. Dessa verktyg använder vanligtvis visuella gränssnitt för att välja data, även om de kan ha problem med komplext dynamiskt innehåll eller anti-bot-åtgärder.
Typiskt arbetsflöde med no-code-verktyg
- Installera webbläsartillägg eller registrera dig på plattformen
- Navigera till målwebbplatsen och öppna verktyget
- Välj dataelement att extrahera med point-and-click
- Konfigurera CSS-selektorer för varje datafält
- Ställ in pagineringsregler för att scrapa flera sidor
- Hantera CAPTCHAs (kräver ofta manuell lösning)
- Konfigurera schemaläggning för automatiska körningar
- Exportera data till CSV, JSON eller anslut via API
Vanliga utmaningar
- Inlärningskurva: Att förstå selektorer och extraktionslogik tar tid
- Selektorer går sönder: Webbplatsändringar kan förstöra hela ditt arbetsflöde
- Problem med dynamiskt innehåll: JavaScript-tunga sidor kräver komplexa lösningar
- CAPTCHA-begränsningar: De flesta verktyg kräver manuell hantering av CAPTCHAs
- IP-blockering: Aggressiv scraping kan leda till att din IP blockeras
Kodexempel
import requests
from bs4 import BeautifulSoup
# StubHub uses Akamai; a simple request will likely be blocked without advanced headers or a proxy.
url = 'https://www.stubhub.com/find/s/?q=concerts'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9'
}
try:
# Sending the request with headers to mimic a real browser
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Example: Attempting to find event titles (Selectors change frequently)
events = soup.select('.event-card-title')
for event in events:
print(f'Found Event: {event.get_text(strip=True)}')
except requests.exceptions.RequestException as e:
print(f'Request failed: {e}')När ska det användas
Bäst för statiska HTML-sidor med minimal JavaScript. Idealiskt för bloggar, nyhetssidor och enkla e-handelsproduktsidor.
Fördelar
- ●Snabbaste exekveringen (ingen webbläsaröverhead)
- ●Lägsta resursförbrukning
- ●Lätt att parallellisera med asyncio
- ●Utmärkt för API:er och statiska sidor
Begränsningar
- ●Kan inte köra JavaScript
- ●Misslyckas på SPA:er och dynamiskt innehåll
- ●Kan ha problem med komplexa anti-bot-system
Hur man skrapar StubHub med kod
Python + Requests
import requests
from bs4 import BeautifulSoup
# StubHub uses Akamai; a simple request will likely be blocked without advanced headers or a proxy.
url = 'https://www.stubhub.com/find/s/?q=concerts'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9'
}
try:
# Sending the request with headers to mimic a real browser
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Example: Attempting to find event titles (Selectors change frequently)
events = soup.select('.event-card-title')
for event in events:
print(f'Found Event: {event.get_text(strip=True)}')
except requests.exceptions.RequestException as e:
print(f'Request failed: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_stubhub():
with sync_playwright() as p:
# Launching a headed or headless browser
browser = p.chromium.launch(headless=True)
context = browser.new_context(user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36')
page = context.new_page()
# Navigate to a specific event page
page.goto('https://www.stubhub.com/concert-tickets/')
# Wait for dynamic ticket listings to load into the DOM
page.wait_for_selector('.event-card', timeout=10000)
# Extracting data using locator
titles = page.locator('.event-card-title').all_inner_texts()
for title in titles:
print(title)
browser.close()
if __name__ == '__main__':
scrape_stubhub()Python + Scrapy
import scrapy
class StubHubSpider(scrapy.Spider):
name = 'stubhub_spider'
start_urls = ['https://www.stubhub.com/search']
def parse(self, response):
# StubHub's data is often inside JSON script tags or rendered via JS
# This example assumes standard CSS selectors for demonstration
for event in response.css('.event-item-container'):
yield {
'name': event.css('.event-title::text').get(),
'price': event.css('.price-amount::text').get(),
'location': event.css('.venue-info::text').get()
}
# Handling pagination by finding the 'Next' button
next_page = response.css('a.pagination-next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Set a realistic User Agent
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36');
try {
await page.goto('https://www.stubhub.com', { waitUntil: 'networkidle2' });
// Wait for the listings to be rendered by React
await page.waitForSelector('.event-card');
const data = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.event-card'));
return items.map(item => ({
title: item.querySelector('.event-title-class')?.innerText,
price: item.querySelector('.price-class')?.innerText
}));
});
console.log(data);
} catch (err) {
console.error('Error during scraping:', err);
} finally {
await browser.close();
}
})();Vad Du Kan Göra Med StubHub-Data
Utforska praktiska tillämpningar och insikter från StubHub-data.
Dynamisk prisanalys för biljetter
Biljettåterförsäljare kan justera sina priser i realtid baserat på nuvarande utbud och efterfrågan som observeras på StubHub.
Så här implementerar du:
- 1Extrahera konkurrentpriser för specifika sektioner varje timme.
- 2Identifiera pristrender fram till evenemangsdatumet.
- 3Justera automatiskt priser på andrahandsmarknader för att förbli mest konkurrenskraftig.
Använd Automatio för att extrahera data från StubHub och bygga dessa applikationer utan att skriva kod.
Vad Du Kan Göra Med StubHub-Data
- Dynamisk prisanalys för biljetter
Biljettåterförsäljare kan justera sina priser i realtid baserat på nuvarande utbud och efterfrågan som observeras på StubHub.
- Extrahera konkurrentpriser för specifika sektioner varje timme.
- Identifiera pristrender fram till evenemangsdatumet.
- Justera automatiskt priser på andrahandsmarknader för att förbli mest konkurrenskraftig.
- Arbitrage-bot för andrahandsmarknaden
Hitta biljetter som är prissatta betydligt under marknadsgenomsnittet för snabb vinst vid återförsäljning.
- Scrapa flera biljettplattformar (StubHub, SeatGeek, Vivid Seats) samtidigt.
- Jämför priser för exakt samma rad och sektion.
- Skicka omedelbara aviseringar när en biljett på en plattform är prissatt lågt nog för en lönsam 'flip'.
- Prognostisering av evenemangspopularitet
Arrangörer använder lagerdata för att avgöra om de ska lägga till fler datum på en turné eller byta arena.
- Övervaka fältet 'Quantity Available' för en specifik artist i flera städer.
- Beräkna hastigheten med vilken lagret töms (velocity).
- Generera efterfrågerapporter för att motivera extra föreställningar i områden med hög efterfrågan.
- Arena-analys för hotell och restaurang
Närliggande hotell och restauranger kan förutsäga hektiska kvällar genom att spåra slutsålda evenemang och biljettvolym.
- Scrapa kommande scheman för lokala arenor och teatrar.
- Spåra biljetters sällsynthet för att identifiera datum med hög genomslagskraft.
- Justera personalnivåer och marknadsföringskampanjer för populära evenemangskvällar.
Superladda ditt arbetsflode med AI-automatisering
Automatio kombinerar kraften av AI-agenter, webbautomatisering och smarta integrationer for att hjalpa dig astadkomma mer pa kortare tid.
Proffstips för Skrapning av StubHub
Expertråd för framgångsrik dataextraktion från StubHub.
Använd högkvalitativa residential proxies. Datacenter-IP:ar flaggas och blockeras nästan omedelbart av Akamai.
Övervaka XHR/Fetch-förfrågningar i din webbläsares Network-flik. Ofta hämtar StubHub biljettdata i JSON-format, vilket är lättare att parsa än HTML.
Implementera slumpmässiga fördröjningar och mänskliga interaktioner (musrörelser, scrollning) för att minska risken för upptäckt.
Fokusera på att scrapa specifika Event ID
n. URL-strukturen innehåller vanligtvis ett unikt ID som kan användas för att bygga direktlänkar till biljettlistor.
Scrapa under tider med låg trafik när serverbelastningen är lägre för att minimera risken för att trigga aggressiva rate limits.
Rotera mellan olika webbläsarprofiler och User-Agents för att efterlikna en varierad grupp av riktiga användare.
Omdomen
Vad vara anvandare sager
Ga med tusentals nojda anvandare som har transformerat sitt arbetsflode
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relaterat Web Scraping
How to Scrape Tata 1mg | 1mg.com Medicine Data Scraper
How to Scrape Carwow: Extract Used Car Data and Prices

How to Scrape Kalodata: TikTok Shop Data Extraction Guide
How to Scrape HP.com: A Technical Guide to Product & Price Data
How to Scrape eBay | eBay Web Scraper Guide
How to Scrape The Range UK | Product Data & Prices Scraper
How to Scrape ThemeForest Web Data
How to Scrape AliExpress: The Ultimate 2025 Data Extraction Guide
Vanliga fragor om StubHub
Hitta svar pa vanliga fragor om StubHub