Hur man scrapar Web Designer News
Lär dig hur du scrapar Web Designer News för att extrahera trendande designartiklar, käll-URL:er och tidsstämplar. Perfekt för trendbevakning och...
Om Web Designer News
Upptäck vad Web Designer News erbjuder och vilka värdefulla data som kan extraheras.
Översikt av Web Designer News
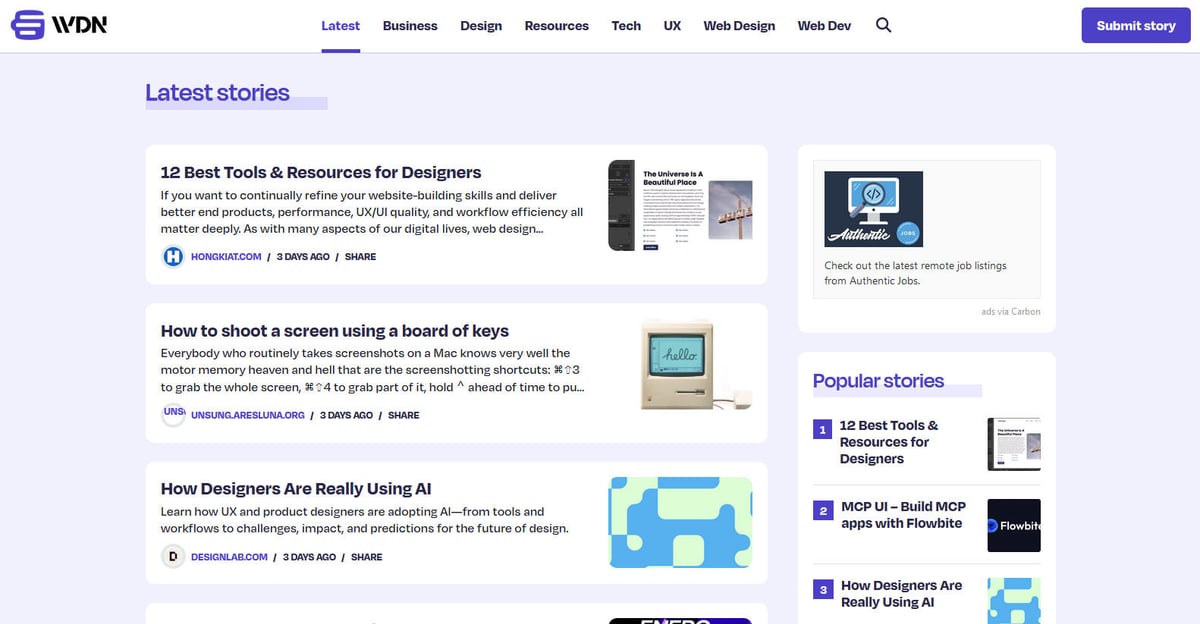
Web Designer News är en ledande community-driven nyhetsaggregator specifikt kurerad för ekosystemet inom webbdesign och utveckling. Sedan starten har plattformen fungerat som en central knutpunkt där yrkesverksamma upptäcker ett handplockat urval av de mest relevanta nyheterna, tutorials, verktyg och resurser från hela internet. Den täcker ett brett spektrum av ämnen inklusive UX-design, affärsstrategi, teknikuppdateringar och grafisk design, presenterat i ett rent, kronologiskt flöde.
Webbplatsarkitektur och datapotential
Webbplatsens arkitektur är byggd på WordPress, med en högst strukturerad layout som organiserar innehåll i specifika kategorier som 'Web Design', 'Web Dev', 'UX' och 'Resources'. Eftersom den aggregerar data från tusentals enskilda bloggar och tidskrifter till ett enda sökbart gränssnitt, fungerar den som ett högkvalitativt filter för branschinformation. Denna struktur gör den till ett idealiskt mål för web scraping, då den ger tillgång till en förhandsgranskad ström av värdefull industridata utan att behöva crawla hundratals separata domäner.
Varför Skrapa Web Designer News?
Upptäck affärsvärdet och användningsfallen för dataextraktion från Web Designer News.
Identifiera framväxande designtrender och verktyg i realtid.
Automatisera kurering av branschnyheter för nyhetsbrev och flöden i sociala medier.
Utför konkurrentanalys genom att övervaka innehåll från rivaler som lyfts fram.
Generera högkvalitativa dataset för träning av Natural Language Processing (NLP).
Bygg ett centraliserat bibliotek för designresurser för interna kunskapsbaser.
Skrapningsutmaningar
Tekniska utmaningar du kan stöta på när du skrapar Web Designer News.
Hantering av tekniska omdirigeringar via webbplatsens interna 'go'-länksystem.
Inkonsekvent tillgänglighet av tumnagelbilder i äldre arkiverade inlägg.
Rate limiting på serversidan vid högfrekventa förfrågningar via Nginx-skydd.
Skrapa Web Designer News med AI
Ingen kod krävs. Extrahera data på minuter med AI-driven automatisering.
Hur det fungerar
Beskriv vad du behöver
Berätta för AI vilka data du vill extrahera från Web Designer News. Skriv det bara på vanligt språk — ingen kod eller selektorer behövs.
AI extraherar datan
Vår artificiella intelligens navigerar Web Designer News, hanterar dynamiskt innehåll och extraherar exakt det du bad om.
Få dina data
Få ren, strukturerad data redo att exportera som CSV, JSON eller skicka direkt till dina appar och arbetsflöden.
Varför använda AI för skrapning
AI gör det enkelt att skrapa Web Designer News utan att skriva kod. Vår AI-drivna plattform använder artificiell intelligens för att förstå vilka data du vill ha — beskriv det bara på vanligt språk och AI extraherar dem automatiskt.
How to scrape with AI:
- Beskriv vad du behöver: Berätta för AI vilka data du vill extrahera från Web Designer News. Skriv det bara på vanligt språk — ingen kod eller selektorer behövs.
- AI extraherar datan: Vår artificiella intelligens navigerar Web Designer News, hanterar dynamiskt innehåll och extraherar exakt det du bad om.
- Få dina data: Få ren, strukturerad data redo att exportera som CSV, JSON eller skicka direkt till dina appar och arbetsflöden.
Why use AI for scraping:
- Komplett no-code-arbetsflöde för icke-tekniska designers och marknadsförare.
- Molnbaserad schemaläggning möjliggör daglig nyhetsextraktion helt automatiskt.
- Inbyggd hantering av paginering och detektering av strukturerade element.
- Direktintegration med Google Sheets för omedelbar datadistribution.
No-code webbskrapare för Web Designer News
Peka-och-klicka-alternativ till AI-driven skrapning
Flera no-code-verktyg som Browse.ai, Octoparse, Axiom och ParseHub kan hjälpa dig att skrapa Web Designer News utan att skriva kod. Dessa verktyg använder vanligtvis visuella gränssnitt för att välja data, även om de kan ha problem med komplext dynamiskt innehåll eller anti-bot-åtgärder.
Typiskt arbetsflöde med no-code-verktyg
Vanliga utmaningar
Inlärningskurva
Att förstå selektorer och extraktionslogik tar tid
Selektorer går sönder
Webbplatsändringar kan förstöra hela ditt arbetsflöde
Problem med dynamiskt innehåll
JavaScript-tunga sidor kräver komplexa lösningar
CAPTCHA-begränsningar
De flesta verktyg kräver manuell hantering av CAPTCHAs
IP-blockering
Aggressiv scraping kan leda till att din IP blockeras
No-code webbskrapare för Web Designer News
Flera no-code-verktyg som Browse.ai, Octoparse, Axiom och ParseHub kan hjälpa dig att skrapa Web Designer News utan att skriva kod. Dessa verktyg använder vanligtvis visuella gränssnitt för att välja data, även om de kan ha problem med komplext dynamiskt innehåll eller anti-bot-åtgärder.
Typiskt arbetsflöde med no-code-verktyg
- Installera webbläsartillägg eller registrera dig på plattformen
- Navigera till målwebbplatsen och öppna verktyget
- Välj dataelement att extrahera med point-and-click
- Konfigurera CSS-selektorer för varje datafält
- Ställ in pagineringsregler för att scrapa flera sidor
- Hantera CAPTCHAs (kräver ofta manuell lösning)
- Konfigurera schemaläggning för automatiska körningar
- Exportera data till CSV, JSON eller anslut via API
Vanliga utmaningar
- Inlärningskurva: Att förstå selektorer och extraktionslogik tar tid
- Selektorer går sönder: Webbplatsändringar kan förstöra hela ditt arbetsflöde
- Problem med dynamiskt innehåll: JavaScript-tunga sidor kräver komplexa lösningar
- CAPTCHA-begränsningar: De flesta verktyg kräver manuell hantering av CAPTCHAs
- IP-blockering: Aggressiv scraping kan leda till att din IP blockeras
Kodexempel
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Skicka förfrågan till huvudsidan
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Hitta behållare för inlägg
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Kontrollera om källans webbplatsnamn finns
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Okänd'
link = post.find('h3').find('a')['href']
print(f'Titel: {title} | Källa: {source} | Länk: {link}')
except Exception as e:
print(f'Ett fel uppstod: {e}')När ska det användas
Bäst för statiska HTML-sidor med minimal JavaScript. Idealiskt för bloggar, nyhetssidor och enkla e-handelsproduktsidor.
Fördelar
- ●Snabbaste exekveringen (ingen webbläsaröverhead)
- ●Lägsta resursförbrukning
- ●Lätt att parallellisera med asyncio
- ●Utmärkt för API:er och statiska sidor
Begränsningar
- ●Kan inte köra JavaScript
- ●Misslyckas på SPA:er och dynamiskt innehåll
- ●Kan ha problem med komplexa anti-bot-system
Hur man skrapar Web Designer News med kod
Python + Requests
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Skicka förfrågan till huvudsidan
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Hitta behållare för inlägg
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Kontrollera om källans webbplatsnamn finns
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Okänd'
link = post.find('h3').find('a')['href']
print(f'Titel: {title} | Källa: {source} | Länk: {link}')
except Exception as e:
print(f'Ett fel uppstod: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_wdn():
with sync_playwright() as p:
# Starta en headless browser
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://webdesignernews.com/')
# Vänta på att inläggselementen ska laddas
page.wait_for_selector('.single-post')
posts = page.query_selector_all('.single-post')
for post in posts:
title_el = post.query_selector('h3 a')
if title_el:
title = title_el.inner_text()
link = title_el.get_attribute('href')
print(f'Scraped: {title} - {link}')
browser.close()
scrape_wdn()Python + Scrapy
import scrapy
class WdnSpider(scrapy.Spider):
name = 'wdn_spider'
start_urls = ['https://webdesignernews.com/']
def parse(self, response):
# Extrahera varje inlägg i flödet
for post in response.css('.single-post'):
yield {
'title': post.css('h3 a::text').get(),
'source': post.css('.site_name::text').get(),
'link': post.css('h3 a::attr(href)').get()
}
# Hantera paginering genom att hitta 'Nästa'-länken
next_page = response.css('a.next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://webdesignernews.com/', { waitUntil: 'domcontentloaded' });
// Utvärdera sidan för att extrahera datafält
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.single-post'));
return items.map(item => ({
title: item.querySelector('h3 a') ? item.querySelector('h3 a').innerText : null,
source: item.querySelector('.site_name') ? item.querySelector('.site_name').innerText : null,
link: item.querySelector('h3 a') ? item.querySelector('h3 a').href : null
}));
});
console.log(results);
await browser.close();
})();Vad Du Kan Göra Med Web Designer News-Data
Utforska praktiska tillämpningar och insikter från Web Designer News-data.
Automatiserat nyhetsflöde för design
Skapa en live, kurerad nyhetskanal för professionella designteam via Slack eller Discord.
Så här implementerar du:
- 1Scrapa topprankade artiklar var fjärde timme.
- 2Filtrera resultaten efter relevanta kategoritaggar som 'UX' eller 'Web Dev'.
- 3Skicka extraherade titlar och sammanfattningar till en messaging-webhook.
- 4Arkivera datan för att spåra långsiktig popularitet för branschverktyg.
Använd Automatio för att extrahera data från Web Designer News och bygga dessa applikationer utan att skriva kod.
Vad Du Kan Göra Med Web Designer News-Data
- Automatiserat nyhetsflöde för design
Skapa en live, kurerad nyhetskanal för professionella designteam via Slack eller Discord.
- Scrapa topprankade artiklar var fjärde timme.
- Filtrera resultaten efter relevanta kategoritaggar som 'UX' eller 'Web Dev'.
- Skicka extraherade titlar och sammanfattningar till en messaging-webhook.
- Arkivera datan för att spåra långsiktig popularitet för branschverktyg.
- Trendbevakning för designverktyg
Identifiera vilken designprogramvara eller vilka bibliotek som får mest uppmärksamhet i communityn.
- Extrahera titlar och utdrag från arkivet i kategorin 'Resources'.
- Utför sökordsfrekvensanalys på specifika termer (t.ex. 'Figma', 'React').
- Jämför tillväxt i omnämnanden månad för månad för att identifiera stigande stjärnor.
- Exportera visuella rapporter för marknadsförings- eller produktstrategiteam.
- Övervakning av konkurrenters bakåtlänkar
Identifiera vilka bloggar eller byråer som framgångsrikt placerar innehåll på stora hubbar.
- Scrapa fältet 'Source Website Name' för alla historiska listningar.
- Aggregera antal omnämnanden per extern domän för att se vem som förekommer mest.
- Analysera de typer av innehåll som accepteras för bättre outreach.
- Identifiera potentiella samarbetspartners inom designområdet.
- Dataset för machine learning-träning
Använd kurerade utdrag och sammanfattningar för att träna tekniska sammanfattningsmodeller.
- Scrapa 10 000+ artikelrubriker och motsvarande sammanfattningar.
- Rensa textdata för att ta bort interna spårningsparametrar och HTML.
- Använd titeln som mål och utdraget som indata för fine-tuning.
- Testa din model på nya, okända designartiklar för att utvärdera prestanda.
Superladda ditt arbetsflode med AI-automatisering
Automatio kombinerar kraften av AI-agenter, webbautomatisering och smarta integrationer for att hjalpa dig astadkomma mer pa kortare tid.
Proffstips för Skrapning av Web Designer News
Expertråd för framgångsrik dataextraktion från Web Designer News.
Rikta in dig på WordPress REST API-ändpunkten (/wp-json/wp/v2/posts) för snabbare och mer pålitlig strukturerad data än HTML-parsing.
Övervaka webbplatsens RSS-flöde på webdesignernews.com/feed/ för att fånga upp nya artiklar i samma ögonblick som de publiceras.
Schemalägg dina scraping-uppgifter till 9
00 AM EST för att sammanfalla med den dagliga toppen av community-inskickat innehåll.
Rotera User-Agent-strängar och implementera en 2-sekunders fördröjning mellan förfrågningar för att undvika att trigga Nginx rate limits.
Hantera alltid interna '/go/'-länkar genom att följa omdirigeringar för att extrahera den slutgiltiga kanoniska käll-URL:en.
Rensa utdrag av textdata genom att ta bort HTML-taggar och avslutande ellipser för bättre analysresultat.
Omdomen
Vad vara anvandare sager
Ga med tusentals nojda anvandare som har transformerat sitt arbetsflode
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relaterat Web Scraping




Vanliga fragor om Web Designer News
Hitta svar pa vanliga fragor om Web Designer News