วิธีการ Scrape CoinMarketCap: คู่มือการทำ Web Scraping ฉบับสมบูรณ์
เรียนรู้วิธีการ Scrape CoinMarketCap เพื่อดึงข้อมูลราคาคริปโตเคอร์เรนซีแบบเรียลไทม์, Market Cap และปริมาณการซื้อขาย...
ตรวจพบการป้องกันบอท
- Cloudflare
- WAF และการจัดการบอทระดับองค์กร ใช้ JavaScript challenges, CAPTCHAs และการวิเคราะห์พฤติกรรม ต้องมีระบบอัตโนมัติของเบราว์เซอร์พร้อมการตั้งค่าซ่อนตัว
- การจำกัดอัตรา
- จำกัดคำขอต่อ IP/เซสชันตามเวลา สามารถหลีกเลี่ยงได้ด้วยพร็อกซีหมุนเวียน การหน่วงเวลาคำขอ และการสแกรปแบบกระจาย
- ลายนิ้วมือเบราว์เซอร์
- ระบุบอทผ่านลักษณะเฉพาะของเบราว์เซอร์: canvas, WebGL, ฟอนต์, ปลั๊กอิน ต้องมีการปลอมแปลงหรือโปรไฟล์เบราว์เซอร์จริง
- Dynamic CSS Classes
- JavaScript Challenge
- ต้องมีการเรียกใช้ JavaScript เพื่อเข้าถึงเนื้อหา คำขอแบบง่ายจะล้มเหลว ต้องใช้เบราว์เซอร์ headless เช่น Playwright หรือ Puppeteer
เกี่ยวกับ CoinMarketCap
ค้นพบสิ่งที่ CoinMarketCap นำเสนอและข้อมูลที่มีค่าที่สามารถดึงได้
ผู้นำด้านข้อมูลคริปโต
CoinMarketCap เป็นเว็บไซต์ติดตามราคาคริปโตเคอร์เรนซีที่ถูกอ้างอิงมากที่สุดในโลก โดยให้ข้อมูลที่แม่นยำและเรียลไทม์สำหรับสินทรัพย์ดิจิทัลหลายพันรายการ ก่อตั้งขึ้นในปี 2013 และทำหน้าที่เป็นศูนย์กลางสำคัญของระบบนิเวศคริปโตด้วยการรวบรวมข้อมูลจากเว็บเทรดหลายร้อยแห่งทั่วโลกมาไว้ในอินเทอร์เฟซที่โปร่งใสและเป็นหนึ่งเดียว แพลตฟอร์มนี้มีความจำเป็นอย่างยิ่งสำหรับการติดตาม market capitalization, ปริมาณการซื้อขาย และข้อมูลอุปทาน
ความลึกและโครงสร้างของข้อมูล
เว็บไซต์ประกอบด้วยข้อมูลที่มีโครงสร้างสูงสำหรับคริปโตเคอร์เรนซี รวมถึงอันดับ กราฟย้อนหลัง ตลาดซื้อขาย และข้อมูลเฉพาะของโปรเจกต์ เช่น ที่อยู่สัญญา (contract addresses) และลิงก์โซเชียล สำหรับนักพัฒนาและนักลงทุน ข้อมูลนี้คือรากฐานในการสร้างเครื่องมือติดตามพอร์ตการลงทุน เครื่องมือวิเคราะห์ความรู้สึก (sentiment analysis) และระบบเทรดอัตโนทัศน์
ทำไมการ Scrape จึงเป็นสิ่งจำเป็น
การ Scrape CoinMarketCap มีคุณค่าสูงเพราะช่วยให้เห็นภาพรวมของตลาดคริปโตที่กระจัดกระจายได้ในที่เดียว การดึงข้อมูลแบบอัตโนมัติช่วยให้ผู้ใช้ก้าวข้ามข้อจำกัดของ API ระดับฟรี สามารถตรวจสอบการเคลื่อนไหวของราคาในตลาดทั้งหมดได้แบบเรียลไทม์ และทำการวิเคราะห์ข้อมูลย้อนหลังเชิงลึกได้โดยไม่ต้องป้อนข้อมูลด้วยตนเอง
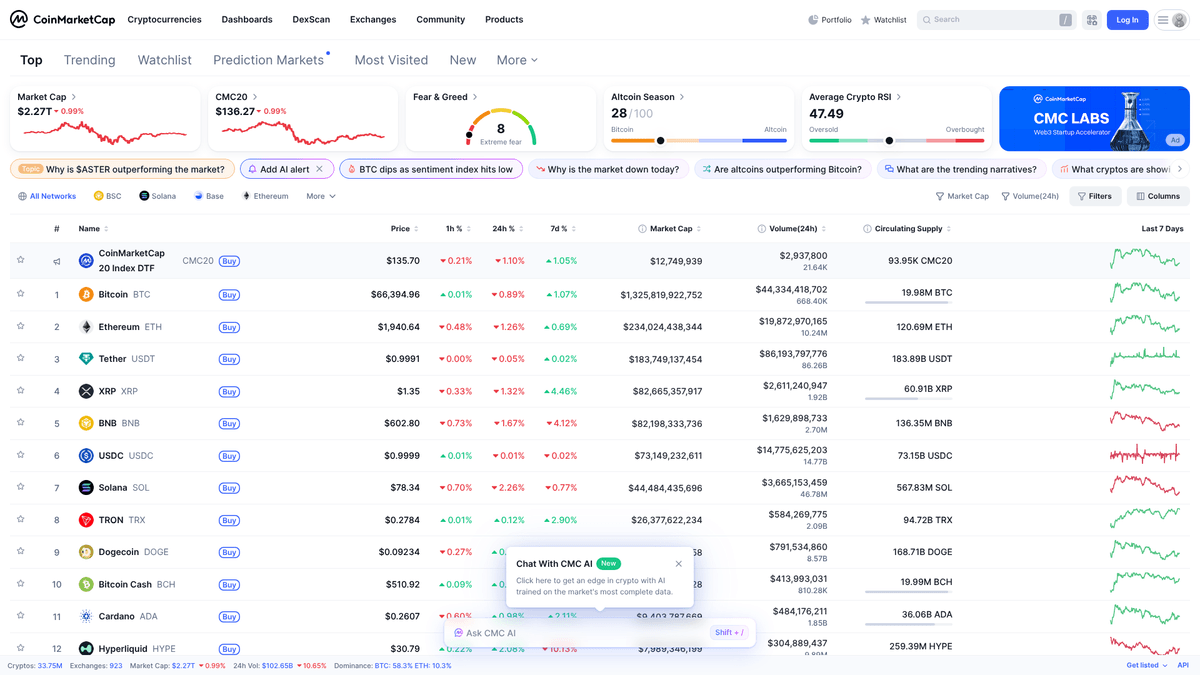
ทำไมต้อง Scrape CoinMarketCap?
ค้นพบคุณค่าทางธุรกิจและกรณีการใช้งานสำหรับการดึงข้อมูลจาก CoinMarketCap
ตรวจสอบราคาแบบเรียลไทม์สำหรับบอทเทรดอัลกอริทึม
รวบรวมปริมาณการซื้อขายย้อนหลังสำหรับการวิจัยตลาดเชิงลึก
ติดตามเหรียญที่เข้าใหม่และโปรเจกต์ที่เพิ่งเพิ่มเข้ามา
การวิเคราะห์คู่แข่งสำหรับผู้ให้บริการด้านบล็อกเชน
สร้างเครื่องมือจัดการพอร์ตการลงทุนคริปโตแบบกำหนดเอง
วิเคราะห์ความรู้สึกของตลาดตามลิงก์ชุมชนและความนิยม
ความท้าทายในการ Scrape
ความท้าทายทางเทคนิคที่คุณอาจพบเมื่อ Scrape CoinMarketCap
ระบบ Cloudflare Bot Management ที่เข้มงวดซึ่งบล็อกคำขอมาตรฐาน
การพึ่งพา JavaScript อย่างหนักในการแสดงผลตารางข้อมูล
CSS selectors ที่มีการพรางข้อมูลและเปลี่ยนไปตามระยะเวลา
การจำกัดอัตราการส่งคำขอที่เข้มงวดบน IP addresses ทำให้การดึงข้อมูลความเร็วสูงทำได้ยาก
การโหลดเนื้อหาแบบไดนามิกที่ต้องมีการเลื่อนหน้าจอเพื่อกระตุ้นการดึงข้อมูล
สกัดข้อมูลจาก CoinMarketCap ด้วย AI
ไม่ต้องเขียนโค้ด สกัดข้อมูลภายในไม่กี่นาทีด้วยระบบอัตโนมัติที่ขับเคลื่อนด้วย AI
วิธีการทำงาน
อธิบายสิ่งที่คุณต้องการ
บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก CoinMarketCap แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
AI สกัดข้อมูล
ปัญญาประดิษฐ์ของเรานำทาง CoinMarketCap จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
รับข้อมูลของคุณ
รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
ทำไมต้องใช้ AI ในการสกัดข้อมูล
AI ทำให้การสกัดข้อมูลจาก CoinMarketCap เป็นเรื่องง่ายโดยไม่ต้องเขียนโค้ด แพลตฟอร์มที่ขับเคลื่อนด้วยปัญญาประดิษฐ์ของเราเข้าใจว่าคุณต้องการข้อมูลอะไร — แค่อธิบายเป็นภาษาธรรมชาติ แล้ว AI จะสกัดให้โดยอัตโนมัติ
How to scrape with AI:
- อธิบายสิ่งที่คุณต้องการ: บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก CoinMarketCap แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
- AI สกัดข้อมูล: ปัญญาประดิษฐ์ของเรานำทาง CoinMarketCap จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
- รับข้อมูลของคุณ: รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
Why use AI for scraping:
- ข้ามผ่านระบบป้องกัน Cloudflare และระบบป้องกันบอทโดยอัตโนมัติ
- อินเทอร์เฟซแบบ no-code สำหรับเลือกองค์ประกอบไดนามิกที่ซับซ้อน
- การตั้งเวลาทำงานช่วยให้สามารถเก็บข้อมูลย้อนหลังได้อย่างสม่ำเสมอ
- ส่งออกข้อมูลที่มีโครงสร้างไปยัง Google Sheets หรือ API ได้โดยตรง
No-code web scrapers สำหรับ CoinMarketCap
ทางเลือกแบบ point-and-click สำหรับการ scraping ด้วย AI
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape CoinMarketCap โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
ความท้าทายทั่วไป
เส้นโค้งการเรียนรู้
การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
Selectors เสีย
การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
ปัญหาเนื้อหาไดนามิก
เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
ข้อจำกัด CAPTCHA
เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
การบล็อก IP
การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
No-code web scrapers สำหรับ CoinMarketCap
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape CoinMarketCap โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
- ติดตั้งส่วนขยายเบราว์เซอร์หรือสมัครใช้งานแพลตฟอร์ม
- นำทางไปยังเว็บไซต์เป้าหมายและเปิดเครื่องมือ
- เลือกองค์ประกอบข้อมูลที่ต้องการดึงด้วยการชี้และคลิก
- กำหนดค่า CSS selectors สำหรับแต่ละฟิลด์ข้อมูล
- ตั้งค่ากฎการแบ่งหน้าเพื่อ scrape หลายหน้า
- จัดการ CAPTCHA (มักต้องแก้ไขด้วยตนเอง)
- กำหนดค่าการตั้งเวลาสำหรับการรันอัตโนมัติ
- ส่งออกข้อมูลเป็น CSV, JSON หรือเชื่อมต่อผ่าน API
ความท้าทายทั่วไป
- เส้นโค้งการเรียนรู้: การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
- Selectors เสีย: การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
- ปัญหาเนื้อหาไดนามิก: เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
- ข้อจำกัด CAPTCHA: เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
- การบล็อก IP: การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
ตัวอย่างโค้ด
import requests
from bs4 import BeautifulSoup
# Headers are crucial to mimic a real browser session
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
def scrape_cmc():
url = 'https://coinmarketcap.com/'
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# CMC uses dynamic classes; finding the table is the first step
table = soup.find('table', class_='cmc-table')
rows = table.find('tbody').find_all('tr', limit=10)
for row in rows:
name = row.find('p', class_='coin-item-name').text if row.find('p', class_='coin-item-name') else 'N/A'
print(f'Asset Name: {name}')
except Exception as e:
print(f'Error: {e}')
if __name__ == '__main__':
scrape_cmc()เมื่อไหร่ควรใช้
เหมาะที่สุดสำหรับหน้า HTML แบบ static ที่มี JavaScript น้อย เหมาะสำหรับบล็อก ไซต์ข่าว และหน้าสินค้า e-commerce ธรรมดา
ข้อดี
- ●ประมวลผลเร็วที่สุด (ไม่มี overhead ของเบราว์เซอร์)
- ●ใช้ทรัพยากรน้อยที่สุด
- ●ง่ายต่อการทำงานแบบขนานด้วย asyncio
- ●เหมาะมากสำหรับ API และหน้า static
ข้อจำกัด
- ●ไม่สามารถรัน JavaScript ได้
- ●ล้มเหลวใน SPA และเนื้อหาไดนามิก
- ●อาจมีปัญหากับระบบ anti-bot ที่ซับซ้อน
วิธีสเครปข้อมูล CoinMarketCap ด้วยโค้ด
Python + Requests
import requests
from bs4 import BeautifulSoup
# Headers are crucial to mimic a real browser session
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
def scrape_cmc():
url = 'https://coinmarketcap.com/'
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# CMC uses dynamic classes; finding the table is the first step
table = soup.find('table', class_='cmc-table')
rows = table.find('tbody').find_all('tr', limit=10)
for row in rows:
name = row.find('p', class_='coin-item-name').text if row.find('p', class_='coin-item-name') else 'N/A'
print(f'Asset Name: {name}')
except Exception as e:
print(f'Error: {e}')
if __name__ == '__main__':
scrape_cmc()Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
# Launching a headed browser can sometimes help with debugging
browser = p.chromium.launch(headless=True)
context = browser.new_context(user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/120.0.0.0')
page = context.new_page()
page.goto('https://coinmarketcap.com/')
# Wait for the dynamic React table to render fully
page.wait_for_selector('table.cmc-table')
# Extracting the top 10 coin names using the specific class
coins = page.query_selector_all('.coin-item-name')
for coin in coins[:10]:
print(coin.inner_text())
browser.close()
run()Python + Scrapy
import scrapy
class CoinSpider(scrapy.Spider):
name = 'coin_spider'
start_urls = ['https://coinmarketcap.com/']
def parse(self, response):
# Scrapy selectors can handle CSS paths efficiently
for row in response.css('table.cmc-table tbody tr'):
yield {
'name': row.css('p.coin-item-name::text').get(),
'symbol': row.css('p.coin-item-symbol::text').get(),
'price': row.css('div.sc-131cee3c-0 span::text').get()
}
# Basic pagination handling for subsequent pages
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setViewport({ width: 1280, height: 800 });
// Using networkidle2 ensures most React components have finished loading
await page.goto('https://coinmarketcap.com/', { waitUntil: 'networkidle2' });
const data = await page.evaluate(() => {
const results = [];
const rows = document.querySelectorAll('table.cmc-table tbody tr');
rows.forEach((row, index) => {
if (index < 10) {
results.push({
name: row.querySelector('.coin-item-name')?.innerText,
price: row.querySelector('.sc-131cee3c-0')?.innerText
});
}
});
return results;
});
console.log(data);
await browser.close();
})();คุณสามารถทำอะไรกับข้อมูล CoinMarketCap
สำรวจการใช้งานจริงและข้อมูลเชิงลึกจากข้อมูล CoinMarketCap
การค้นหาโอกาสทำ Arbitrage แบบอัตโนมัติ
นักเทรดสามารถใช้ข้อมูลเพื่อระบุความแตกต่างของราคาในเว็บเทรดต่างๆ ที่แสดงอยู่บน CMC
วิธีการนำไปใช้:
- 1Scrape ราคาและสภาพคล่องของเหรียญที่ต้องการจากทุกตลาดที่มีชื่ออยู่
- 2เปรียบเทียบราคากับข้อมูลเรียลไทม์จาก exchange API
- 3ดำเนินการเทรดเมื่อส่วนต่างของราคาครอบคลุมค่าธรรมเนียมการทำธุรกรรม
ใช้ Automatio เพื่อดึงข้อมูลจาก CoinMarketCap และสร้างแอปพลิเคชันเหล่านี้โดยไม่ต้องเขียนโค้ด
คุณสามารถทำอะไรกับข้อมูล CoinMarketCap
- การค้นหาโอกาสทำ Arbitrage แบบอัตโนมัติ
นักเทรดสามารถใช้ข้อมูลเพื่อระบุความแตกต่างของราคาในเว็บเทรดต่างๆ ที่แสดงอยู่บน CMC
- Scrape ราคาและสภาพคล่องของเหรียญที่ต้องการจากทุกตลาดที่มีชื่ออยู่
- เปรียบเทียบราคากับข้อมูลเรียลไทม์จาก exchange API
- ดำเนินการเทรดเมื่อส่วนต่างของราคาครอบคลุมค่าธรรมเนียมการทำธุรกรรม
- การวิเคราะห์ความรู้สึกของเหรียญที่เข้าใหม่
นักวิจัยสามารถติดตามโปรเจกต์ใหม่ๆ เพื่อดูว่าสัญญาณทางโซเชียลสัมพันธ์กับการเคลื่อนไหวของราคาอย่างไร
- Scrape ส่วน 'Recently Added' ของ CMC เป็นรายวัน
- ดึงลิงก์โปรเจกต์อย่างเป็นทางการและบัญชีโซเชียลมีเดีย
- วิเคราะห์การเติบโตของโซเชียลมีเดียใน 48 ชั่วโมงแรกเพื่อคาดการณ์แนวโน้มของตลาด
- การสร้าง model สำหรับ Market Cap ย้อนหลัง
นักวิเคราะห์การเงินสามารถสร้าง model โดยอิงจากตัวชี้วัดอุปทานและ market cap ในช่วงเวลาต่างๆ
- Scrape ข้อมูลย้อนหลังของคริปโตเคอร์เรนซี 100 อันดับแรก
- ดึงข้อมูลอุปทานหมุนเวียน (circulating supply) และอุปทานทั้งหมด (total supply)
- ใช้ regression model เพื่อพยากรณ์การกระจายตัวของ market cap ในอนาค
- การค้นหาลูกค้าเป้าหมายในวงการคริปโต
ผู้ให้บริการสามารถค้นหาโปรเจกต์ใหม่ที่ต้องการความช่วยเหลือด้านการตลาด กฎหมาย หรือเทคนิค
- Scrape ข้อมูลติดต่อหรือลิงก์โซเชียลจากหน้าโปรไฟล์ของเหรียญใหม่
- กรองโปรเจกต์ตาม market cap หรือหมวดหมู่ (เช่น DeFi, Gaming)
- ติดต่อหัวหน้าโปรเจกต์ผ่านแพลตฟอร์มโซเชียลที่ดึงข้อมูลมาได้
เพิ่มพลังให้เวิร์กโฟลว์ของคุณด้วย ระบบอัตโนมัติ AI
Automatio รวมพลังของ AI agents การอัตโนมัติเว็บ และการผสานรวมอัจฉริยะเพื่อช่วยให้คุณทำงานได้มากขึ้นในเวลาน้อยลง
เคล็ดลับมืออาชีพสำหรับการ Scrape CoinMarketCap
คำแนะนำจากผู้เชี่ยวชาญสำหรับการดึงข้อมูลจาก CoinMarketCap อย่างประสบความสำเร็จ
ใช้ residential proxies คุณภาพสูงเพื่อหลีกเลี่ยงข้อผิดพลาด Cloudflare 403 Forbidden
มองหา script tag window.__NEXT_DATA__ ในหน้า source code เพื่อค้นหาข้อมูล JSON ดิบ
หมุนเวียน User-Agent strings และ TLS fingerprints เพื่อข้ามผ่านการตรวจจับบอทขั้นสูง
ตั้งค่าช่วงเวลาการหยุดพักแบบสุ่มระหว่าง 3-10 วินาที เพื่อเลียนแบบพฤติกรรมการใช้งานของมนุษย์
ทำการ Scrape ในช่วงเวลาที่มีผู้ใช้งานน้อยเพื่อลดโอกาสในการเผชิญกับข้อจำกัดอัตราการส่งคำขอ (rate limits) ที่เข้มงวด
ใช้ headless browsers อย่าง Playwright เพื่อจัดการกับการประมวลผล JavaScript ที่ซับซ้อน
คำรับรอง
ผู้ใช้ของเราพูดอย่างไร
เข้าร่วมกับผู้ใช้ที่พึงพอใจนับพันที่ได้เปลี่ยนแปลงเวิร์กโฟลว์ของพวกเขา
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
ที่เกี่ยวข้อง Web Scraping
How to Scrape Moon.ly | Step-by-Step NFT Data Extraction Guide
How to Scrape Yahoo Finance: Extract Stock Market Data
How to Scrape Rocket Mortgage: A Comprehensive Guide
How to Scrape Open Collective: Financial and Contributor Data Guide
How to Scrape jup.ag: Jupiter DEX Web Scraper Guide
How to Scrape Indiegogo: The Ultimate Crowdfunding Data Extraction Guide
How to Scrape ICO Drops: Comprehensive Crypto Data Guide
How to Scrape Crypto.com: Comprehensive Market Data Guide
คำถามที่พบบ่อยเกี่ยวกับ CoinMarketCap
ค้นหาคำตอบสำหรับคำถามทั่วไปเกี่ยวกับ CoinMarketCap