วิธี scrape Coinpaprika: คู่มือการดึงข้อมูลตลาดคริปโทฯ
เรียนรู้วิธี scrape Coinpaprika เพื่อดึงราคาคริปโทฯ แบบ real-time, มูลค่าตลาด และปริมาณการซื้อขายใน exchange ดึงข้อมูลตลาดที่มีค่าเพื่อการวิเคราะห์และวิจัยได้ตั...
ตรวจพบการป้องกันบอท
- Cloudflare
- WAF และการจัดการบอทระดับองค์กร ใช้ JavaScript challenges, CAPTCHAs และการวิเคราะห์พฤติกรรม ต้องมีระบบอัตโนมัติของเบราว์เซอร์พร้อมการตั้งค่าซ่อนตัว
- การจำกัดอัตรา
- จำกัดคำขอต่อ IP/เซสชันตามเวลา สามารถหลีกเลี่ยงได้ด้วยพร็อกซีหมุนเวียน การหน่วงเวลาคำขอ และการสแกรปแบบกระจาย
- การบล็อก IP
- บล็อก IP ของศูนย์ข้อมูลที่รู้จักและที่อยู่ที่ถูกทำเครื่องหมาย ต้องใช้พร็อกซีที่อยู่อาศัยหรือมือถือเพื่อหลีกเลี่ยงอย่างมีประสิทธิภาพ
- ลายนิ้วมือเบราว์เซอร์
- ระบุบอทผ่านลักษณะเฉพาะของเบราว์เซอร์: canvas, WebGL, ฟอนต์, ปลั๊กอิน ต้องมีการปลอมแปลงหรือโปรไฟล์เบราว์เซอร์จริง
เกี่ยวกับ Coinpaprika
ค้นพบสิ่งที่ Coinpaprika นำเสนอและข้อมูลที่มีค่าที่สามารถดึงได้
ภาพรวมของ Coinpaprika
Coinpaprika คือแพลตฟอร์มวิจัยคริปโทเคอร์เรนซีที่ครอบคลุม เปิดตัวในปี 2018 เพื่อให้ข้อมูลตลาดที่เชื่อถือได้ แพลตฟอร์มนี้ติดตามสินทรัพย์ดิจิทัลหลายพันรายการในหลายร้อย exchange โดยนำเสนอข้อมูลเชิงลึกเกี่ยวกับการเคลื่อนไหวของราคา, ปริมาณการซื้อขาย และตัวชี้วัดสภาพคล่อง แพลตฟอร์มนี้ออกแบบมาสำหรับนักลงทุน, นักพัฒนา และนักวิจัยที่ต้องการมุมมองที่โปร่งใสของระบบนิเวศคริปโทฯ ทั่วโลก
ข้อมูลที่มีอยู่
เว็บไซต์ประกอบด้วยข้อมูลจำนวนมาก รวมถึงหน้าเหรียญรายตัว, การจัดอันดับความโปร่งใสของ exchange และแหล่งข้อมูลการศึกษา จุดข้อมูลมีตั้งแต่พื้นฐานอย่างราคาและมูลค่าตลาด ไปจนถึงตัวชี้วัดที่ซับซ้อนอย่าง Confidence scores และความลึกของตลาด (การวิเคราะห์ order book 1% และ 10%) โดยทำหน้าที่เป็น benchmark สำหรับอุตสาหกรรมควบคู่ไปกับเครื่องมือรวบรวมข้อมูลหลักอื่นๆ เช่น CoinMarketCap และ CoinGecko
มูลค่าสำหรับการ Scrape
การ scrape Coinpaprika มีมูลค่าสูงสำหรับการสร้างแดชบอร์ดทางการเงิน, การวิเคราะห์ตลาดเชิงประวัติศาสตร์ และการทำ competitive intelligence ข้อมูลเหล่านี้ช่วยให้ผู้ใช้สามารถตรวจสอบโอกาสในการทำ arbitrage, ติดตามการเติบโตของภาคส่วนเฉพาะในตลาดเช่น DeFi หรือ NFTs และรวมมูลค่าคริปโทฯ แบบ real-time เข้ากับแอปพลิเคชันส่วนตัวหรืองานวิจัยทางวิชาการ โดยไม่มีข้อจำกัดของ rate limits จาก API มาตรฐาน
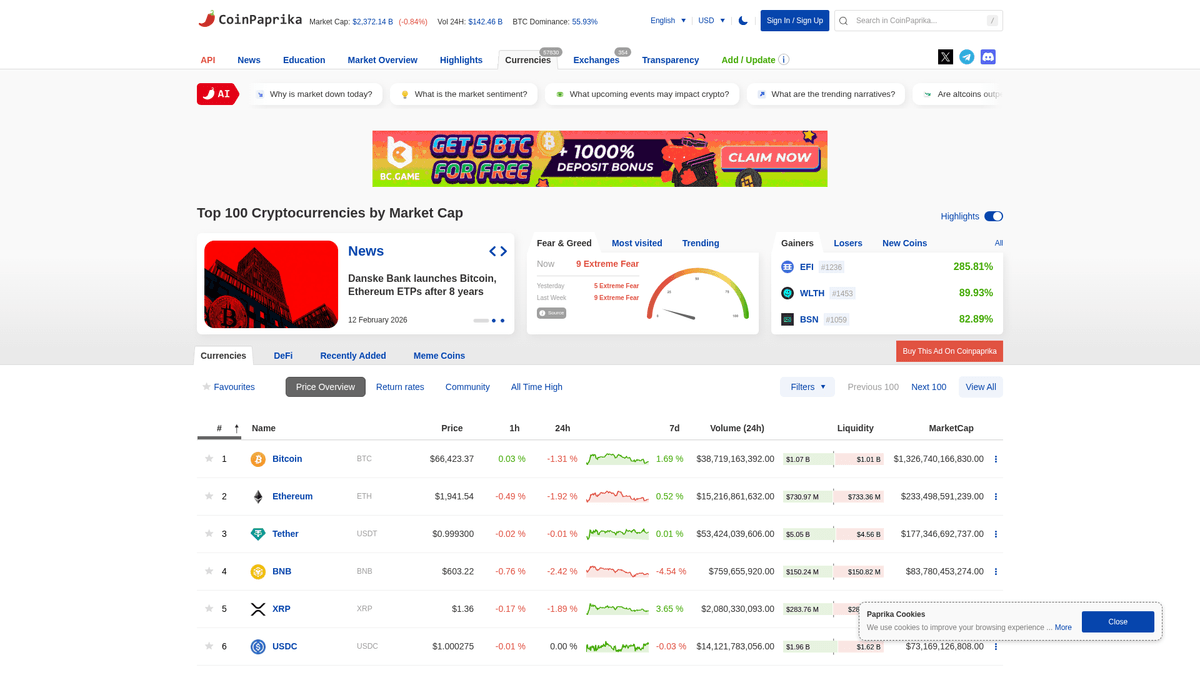
ทำไมต้อง Scrape Coinpaprika?
ค้นพบคุณค่าทางธุรกิจและกรณีการใช้งานสำหรับการดึงข้อมูลจาก Coinpaprika
ตรวจสอบราคาแบบ real-time สำหรับบอทเทรดอัลกอริทึมที่กำหนดเอง
รวบรวมข้อมูลสภาพคล่องและปริมาณการซื้อขายของแต่ละ exchange เพื่อทำ arbitrage
ติดตามคะแนนความโปร่งใสและความเชื่อมั่นของ Coinpaprika สำหรับโทเคนใหม่ๆ
ติดตามสมาชิกในทีมและกิจกรรมของนักพัฒนาจากการเชื่อมต่อกับ GitHub
วิเคราะห์รอบวัฏจักรตลาดในอดีตโดยใช้จุดข้อมูล ATH และ ATL
การสร้างลีด (Lead generation) สำหรับบริการที่เกี่ยวข้องกับคริปโทฯ และเครื่องมือ blockchain
ความท้าทายในการ Scrape
ความท้าทายทางเทคนิคที่คุณอาจพบเมื่อ Scrape Coinpaprika
การเรนเดอร์เนื้อหาแบบไดนามิกสำหรับกราฟราคาและโมดูลความลึกโดยใช้ React
ระบบป้องกันการ scrape จากด่านตรวจ JavaScript ของ Cloudflare
ตารางที่ซ้อนกันอย่างซับซ้อนสำหรับรายการ exchange และคู่เทรด
การจำกัด rate limiting ที่เข้มงวดกับ IP ที่ไม่ได้รับการยืนยันตัวตนในช่วงเวลาที่มีการใช้งานสูง
การอัปเดต CSS selectors บ่อยครั้งในส่วนของ frontend UI
สกัดข้อมูลจาก Coinpaprika ด้วย AI
ไม่ต้องเขียนโค้ด สกัดข้อมูลภายในไม่กี่นาทีด้วยระบบอัตโนมัติที่ขับเคลื่อนด้วย AI
วิธีการทำงาน
อธิบายสิ่งที่คุณต้องการ
บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก Coinpaprika แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
AI สกัดข้อมูล
ปัญญาประดิษฐ์ของเรานำทาง Coinpaprika จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
รับข้อมูลของคุณ
รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
ทำไมต้องใช้ AI ในการสกัดข้อมูล
AI ทำให้การสกัดข้อมูลจาก Coinpaprika เป็นเรื่องง่ายโดยไม่ต้องเขียนโค้ด แพลตฟอร์มที่ขับเคลื่อนด้วยปัญญาประดิษฐ์ของเราเข้าใจว่าคุณต้องการข้อมูลอะไร — แค่อธิบายเป็นภาษาธรรมชาติ แล้ว AI จะสกัดให้โดยอัตโนมัติ
How to scrape with AI:
- อธิบายสิ่งที่คุณต้องการ: บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก Coinpaprika แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
- AI สกัดข้อมูล: ปัญญาประดิษฐ์ของเรานำทาง Coinpaprika จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
- รับข้อมูลของคุณ: รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
Why use AI for scraping:
- ไม่ต้องเขียนโค้ดเพื่อสร้างเครื่องมือ scrape คริปโทฯ ที่ซับซ้อนตั้งแต่เริ่มต้น
- จัดการมาตรการป้องกันบอทอย่าง Cloudflare WAF ได้ในตัว
- ตั้งเวลาการ scrape เพื่อบันทึกข้อมูลตลาดในแต่ละช่วงเวลาที่กำหนด
- ส่งออกข้อมูลไปยัง CSV, Google Sheets หรือ custom Webhook API ได้โดยตรง
No-code web scrapers สำหรับ Coinpaprika
ทางเลือกแบบ point-and-click สำหรับการ scraping ด้วย AI
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape Coinpaprika โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
ความท้าทายทั่วไป
เส้นโค้งการเรียนรู้
การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
Selectors เสีย
การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
ปัญหาเนื้อหาไดนามิก
เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
ข้อจำกัด CAPTCHA
เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
การบล็อก IP
การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
No-code web scrapers สำหรับ Coinpaprika
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape Coinpaprika โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
- ติดตั้งส่วนขยายเบราว์เซอร์หรือสมัครใช้งานแพลตฟอร์ม
- นำทางไปยังเว็บไซต์เป้าหมายและเปิดเครื่องมือ
- เลือกองค์ประกอบข้อมูลที่ต้องการดึงด้วยการชี้และคลิก
- กำหนดค่า CSS selectors สำหรับแต่ละฟิลด์ข้อมูล
- ตั้งค่ากฎการแบ่งหน้าเพื่อ scrape หลายหน้า
- จัดการ CAPTCHA (มักต้องแก้ไขด้วยตนเอง)
- กำหนดค่าการตั้งเวลาสำหรับการรันอัตโนมัติ
- ส่งออกข้อมูลเป็น CSV, JSON หรือเชื่อมต่อผ่าน API
ความท้าทายทั่วไป
- เส้นโค้งการเรียนรู้: การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
- Selectors เสีย: การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
- ปัญหาเนื้อหาไดนามิก: เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
- ข้อจำกัด CAPTCHA: เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
- การบล็อก IP: การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
ตัวอย่างโค้ด
import requests
from bs4 import BeautifulSoup
# URL of the specific coin page
url = 'https://coinpaprika.com/coin/btc-bitcoin/'
# Define headers to mimic a real browser request
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
try:
# Send request to the website
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Extract asset name and price
coin_name = soup.find('h1').text.strip() if soup.find('h1') else 'N/A'
price = soup.find('span', {'class': 'cp-price-value'}).text.strip() if soup.find('span', {'class': 'cp-price-value'}) else 'N/A'
print(f'Asset: {coin_name}')
print(f'Current Price: {price}')
except Exception as e:
print(f'An error occurred: {e}')เมื่อไหร่ควรใช้
เหมาะที่สุดสำหรับหน้า HTML แบบ static ที่มี JavaScript น้อย เหมาะสำหรับบล็อก ไซต์ข่าว และหน้าสินค้า e-commerce ธรรมดา
ข้อดี
- ●ประมวลผลเร็วที่สุด (ไม่มี overhead ของเบราว์เซอร์)
- ●ใช้ทรัพยากรน้อยที่สุด
- ●ง่ายต่อการทำงานแบบขนานด้วย asyncio
- ●เหมาะมากสำหรับ API และหน้า static
ข้อจำกัด
- ●ไม่สามารถรัน JavaScript ได้
- ●ล้มเหลวใน SPA และเนื้อหาไดนามิก
- ●อาจมีปัญหากับระบบ anti-bot ที่ซับซ้อน
วิธีสเครปข้อมูล Coinpaprika ด้วยโค้ด
Python + Requests
import requests
from bs4 import BeautifulSoup
# URL of the specific coin page
url = 'https://coinpaprika.com/coin/btc-bitcoin/'
# Define headers to mimic a real browser request
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
try:
# Send request to the website
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Extract asset name and price
coin_name = soup.find('h1').text.strip() if soup.find('h1') else 'N/A'
price = soup.find('span', {'class': 'cp-price-value'}).text.strip() if soup.find('span', {'class': 'cp-price-value'}) else 'N/A'
print(f'Asset: {coin_name}')
print(f'Current Price: {price}')
except Exception as e:
print(f'An error occurred: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_coinpaprika():
with sync_playwright() as p:
# Launch a headless browser
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Navigate to the coin page
page.goto('https://coinpaprika.com/coin/btc-bitcoin/')
# Wait for the price element to be rendered by JS
page.wait_for_selector('.cp-price-value')
data = {
'title': page.title(),
'price': page.inner_text('.cp-price-value'),
'market_cap': page.inner_text('text=Market Cap >> xpath=..')
}
print(data)
browser.close()
if __name__ == '__main__':
scrape_coinpaprika()Python + Scrapy
import scrapy
class CoinpaprikaSpider(scrapy.Spider):
name = 'coinpaprika'
start_urls = ['https://coinpaprika.com/all-coins/']
def parse(self, response):
# Iterate through coin table rows
for row in response.css('table.cp-table tbody tr'):
yield {
'rank': row.css('td.rank::text').get(),
'name': row.css('td.name a::text').get().strip(),
'price': row.css('td.price span::text').get(),
'market_cap': row.css('td.market-cap::text').get()
}
# Handle simple numbered pagination
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
try {
// Navigate and wait for network activity to settle
await page.goto('https://coinpaprika.com/coin/btc-bitcoin/', { waitUntil: 'networkidle2' });
const coinData = await page.evaluate(() => {
return {
name: document.querySelector('h1')?.innerText.trim(),
price: document.querySelector('.cp-price-value')?.innerText.trim(),
volume24h: document.querySelector('text/Volume (24h)')?.parentElement?.innerText
};
});
console.log(coinData);
} catch (error) {
console.error('Error scraping:', error);
} finally {
await browser.close();
}
})();คุณสามารถทำอะไรกับข้อมูล Coinpaprika
สำรวจการใช้งานจริงและข้อมูลเชิงลึกจากข้อมูล Coinpaprika
การตรวจสอบการทำกำไรจากส่วนต่างราคา (Crypto Arbitrage)
ระบุความแตกต่างของราคาสำหรับสินทรัพย์เดียวกันใน exchange ต่างๆ เพื่อค้นหาโอกาสในการทำกำไร
วิธีการนำไปใช้:
- 1Scrape คู่เทรดทั้งหมดของเหรียญที่ต้องการจากหน้าตลาด
- 2เปรียบเทียบฟิลด์ราคาในทุก exchange ที่ระบุแบบ real-time
- 3กรองผลลัพธ์ด้วย Confidence score เพื่อให้มั่นใจว่าสภาพคล่องได้รับการตรวจสอบแล้ว
- 4คำนวณกำไรที่อาจเกิดขึ้นหลังจากหักค่าธรรมเนียมการทำธุรกรรม
ใช้ Automatio เพื่อดึงข้อมูลจาก Coinpaprika และสร้างแอปพลิเคชันเหล่านี้โดยไม่ต้องเขียนโค้ด
คุณสามารถทำอะไรกับข้อมูล Coinpaprika
- การตรวจสอบการทำกำไรจากส่วนต่างราคา (Crypto Arbitrage)
ระบุความแตกต่างของราคาสำหรับสินทรัพย์เดียวกันใน exchange ต่างๆ เพื่อค้นหาโอกาสในการทำกำไร
- Scrape คู่เทรดทั้งหมดของเหรียญที่ต้องการจากหน้าตลาด
- เปรียบเทียบฟิลด์ราคาในทุก exchange ที่ระบุแบบ real-time
- กรองผลลัพธ์ด้วย Confidence score เพื่อให้มั่นใจว่าสภาพคล่องได้รับการตรวจสอบแล้ว
- คำนวณกำไรที่อาจเกิดขึ้นหลังจากหักค่าธรรมเนียมการทำธุรกรรม
- การประเมินมูลค่าพอร์ตโฟลิโออัตโนมัติ
สร้างแดชบอร์ดส่วนตัวที่อัปเดตมูลค่ารวมของการถือครองคริปโทฯ ของผู้ใช้โดยอัตโนมัติ
- ตั้งค่าตารางเวลา scraper สำหรับเหรียญเฉพาะในพอร์ตโฟลิโอ
- ดึงข้อมูลราคาแบบ real-time ทุกๆ 5 ถึง 15 นาที
- คูณราคาที่ scrape ได้กับยอดคงเหลือคงที่ของผู้ใช้ในสเปรดชีต
- แสดงผลประสิทธิภาพของสินทรัพย์แต่ละรายการและผลกำไร/ขาดทุนรวมเมื่อเวลาผ่านไป
- การวิเคราะห์ความเชื่อมั่นของตลาด (Market Sentiment Analysis)
วิเคราะห์ว่าการรายงานข่าวและการอัปเดตโปรเจกต์มีความสัมพันธ์กับการเคลื่อนไหวของราคาเพื่อทำนายแนวโน้มตลาดหรือไม่
- Scrape ส่วนข่าว (News) บน Coinpaprika สำหรับหมวดหมู่เหรียญที่ต้องการ
- ดึงหัวข้อข่าว, คำอธิบาย และเวลาที่เผยแพร่
- ทำการวิเคราะห์ sentiment ด้วย NLP เพื่อระบุโทนของข่าวว่าเป็นบวก (bullish) หรือลบ (bearish)
- เปรียบเทียบคะแนน sentiment กับการเคลื่อนไหวของราคาที่ scrape มาจากกราฟ
- การวิจัยการทดสอบย้อนหลัง (Historical Backtesting)
รวบรวมข้อมูลย้อนหลังเชิงลึกเพื่อทดสอบและปรับปรุงกลยุทธ์การเทรดก่อนที่จะเสี่ยงใช้เงินทุนจริง
- Scrape กราฟราคาประวัติศาสตร์สำหรับค่าเปิด, สูงสุด, ต่ำสุด และราคาปิดรายวัน
- รวบรวมข้อมูลปริมาณการซื้อขาย 24 ชั่วโมงเพื่อระบุโซนการซื้อขายที่ได้รับความสนใจสูง
- จัดรูปแบบข้อมูลให้เป็นโครงสร้าง OHLC มาตรฐานสำหรับตัวชี้วัดทางเทคนิค
- นำข้อมูลไปรันในซอฟต์แวร์ backtesting เพื่อวัดประสิทธิภาพของกลยุทธ์
- การตรวจสอบความน่าเชื่อถือของโปรเจกต์
ตรวจสอบ Confidence และความโปร่งใสของโปรเจกต์คริปโทฯ เพื่อประเมินความเสี่ยงในการลงทุน
- Scrape ตัวชี้วัดความโปร่งใสสำหรับ exchange หรือเหรียญที่ระบุ
- ดึงข้อมูลในส่วนทีมงาน (Team) เพื่อตรวจสอบประวัติของนักพัฒนาบน GitHub
- เฝ้าติดตามการเปลี่ยนแปลงของอุปทานอย่างกะทันหันหรือปริมาณการซื้อขายที่ผิดปกติ
- ทำเครื่องหมายโปรเจกต์ที่มีคะแนนความเชื่อมั่นต่ำหรือไม่มี whitepaper เพื่อตรวจสอบ
เพิ่มพลังให้เวิร์กโฟลว์ของคุณด้วย ระบบอัตโนมัติ AI
Automatio รวมพลังของ AI agents การอัตโนมัติเว็บ และการผสานรวมอัจฉริยะเพื่อช่วยให้คุณทำงานได้มากขึ้นในเวลาน้อยลง
เคล็ดลับมืออาชีพสำหรับการ Scrape Coinpaprika
คำแนะนำจากผู้เชี่ยวชาญสำหรับการดึงข้อมูลจาก Coinpaprika อย่างประสบความสำเร็จ
ใช้ rotating residential proxies คุณภาพสูงเพื่อเลี่ยง Cloudflare และหลีกเลี่ยงการแบน IP
กำหนดช่วงเวลา random sleep ระหว่าง requests เพื่อเลียนแบบพฤติกรรมการท่องเว็บตามธรรมชาติของมนุษย์
กำหนดเป้าหมายไปที่ internal API endpoints (เช่น subdomains graphsv2) เพื่อดึงข้อมูลที่มีโครงสร้างได้รวดเร็วยิ่งขึ้น
เน้นไปที่ CSS selectors ที่มี 'cp-' เนื่องจากเป็นส่วนหลักของ UI framework เฉพาะของทางเว็บไซต์
จัดเก็บข้อมูลที่ scrape ได้ใน time-series database เช่น InfluxDB สำหรับการวิเคราะห์ข้อมูลย้อนหลังแบบมืออาชีพ
ตั้งค่า User-Agent string มาตรฐานให้ตรงกับ Chrome หรือ Firefox browser เวอร์ชันล่าสุด
คำรับรอง
ผู้ใช้ของเราพูดอย่างไร
เข้าร่วมกับผู้ใช้ที่พึงพอใจนับพันที่ได้เปลี่ยนแปลงเวิร์กโฟลว์ของพวกเขา
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
ที่เกี่ยวข้อง Web Scraping
How to Scrape Moon.ly | Step-by-Step NFT Data Extraction Guide
How to Scrape Yahoo Finance: Extract Stock Market Data
How to Scrape Rocket Mortgage: A Comprehensive Guide
How to Scrape Open Collective: Financial and Contributor Data Guide
How to Scrape jup.ag: Jupiter DEX Web Scraper Guide
How to Scrape Indiegogo: The Ultimate Crowdfunding Data Extraction Guide
How to Scrape ICO Drops: Comprehensive Crypto Data Guide
How to Scrape Crypto.com: Comprehensive Market Data Guide
คำถามที่พบบ่อยเกี่ยวกับ Coinpaprika
ค้นหาคำตอบสำหรับคำถามทั่วไปเกี่ยวกับ Coinpaprika