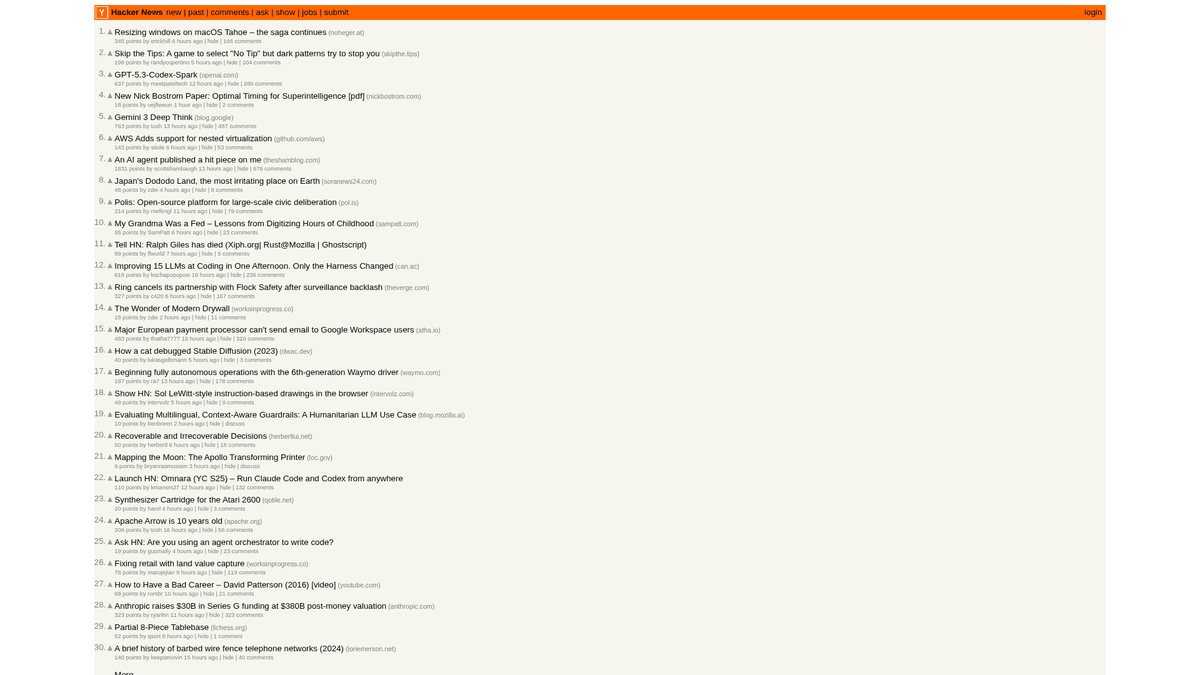
วิธีดึงข้อมูลจาก Hacker News (news.ycombinator.com)
เรียนรู้วิธีดึงข้อมูลจาก Hacker News เพื่อรวบรวมบทความเทคโนโลยีชั้นนำ รายการรับสมัครงาน และการพูดคุยในชุมชน เหมาะสำหรับการทำวิจัยตลาดและการวิเคราะห์เทรนด์
ตรวจพบการป้องกันบอท
- การจำกัดอัตรา
- จำกัดคำขอต่อ IP/เซสชันตามเวลา สามารถหลีกเลี่ยงได้ด้วยพร็อกซีหมุนเวียน การหน่วงเวลาคำขอ และการสแกรปแบบกระจาย
- การบล็อก IP
- บล็อก IP ของศูนย์ข้อมูลที่รู้จักและที่อยู่ที่ถูกทำเครื่องหมาย ต้องใช้พร็อกซีที่อยู่อาศัยหรือมือถือเพื่อหลีกเลี่ยงอย่างมีประสิทธิภาพ
- User-Agent Filtering
เกี่ยวกับ Hacker News
ค้นพบสิ่งที่ Hacker News นำเสนอและข้อมูลที่มีค่าที่สามารถดึงได้
ศูนย์กลางทางเทคโนโลยี
Hacker News เป็นเว็บไซต์ข่าวสังคมออนไลน์ที่เน้นด้านวิทยาการคอมพิวเตอร์และผู้ประกอบการ ดำเนินการโดยตัวเร่งการเติบโตของสตาร์ทอัพอย่าง Y Combinator โดยทำหน้าที่เป็นแพลตฟอร์มที่ขับเคลื่อนโดยชุมชนซึ่งผู้ใช้จะส่งลิงก์บทความทางเทคนิค ข่าวสารสตาร์ทอัพ และการพูดคุยเชิงลึก
ความหลากหลายของข้อมูล
แพลตฟอร์มนี้ประกอบด้วยข้อมูลเรียลไทม์มากมาย รวมถึงเรื่องราวทางเทคโนโลยีที่ได้รับการ Upvote, การเปิดตัวสตาร์ทอัพใน "Show HN", คำถามจากชุมชนใน "Ask HN" และบอร์ดรับสมัครงานเฉพาะทาง เว็บไซต์นี้ได้รับการยอมรับอย่างกว้างขวางว่าเป็นชีพจรของระบบนิเวศ Silicon Valley และชุมชนนักพัฒนาระดับโลก
มูลค่าเชิงกลยุทธ์
การดึงข้อมูลนี้ช่วยให้ธุรกิจและนักวิจัยสามารถติดตาม เทคโนโลยีเกิดใหม่, ติดตามการกล่าวถึงคู่แข่ง และระบุผู้นำทางความคิดที่มีอิทธิพล เนื่องจากเลย์เอาต์ของเว็บไซต์มีความเสถียรและเรียบง่าย จึงเป็นหนึ่งในแหล่งข้อมูลที่น่าเชื่อถือที่สุดสำหรับการรวบรวมข่าวสารทางเทคนิคแบบอัตโนมัติ
ทำไมต้อง Scrape Hacker News?
ค้นพบคุณค่าทางธุรกิจและกรณีการใช้งานสำหรับการดึงข้อมูลจาก Hacker News
ระบุภาษาโปรแกรมและเครื่องมือสำหรับนักพัฒนาที่กำลังมาแรงได้ตั้งแต่เนิ่นๆ
ติดตามระบบนิเวศสตาร์ทอัพสำหรับการเปิดตัวใหม่และข่าวสารการระดมทุน
การหาโอกาสในการสรรหาบุคลากรทางเทคนิคโดยการติดตาม Thread 'Who is Hiring'
วิเคราะห์ความรู้สึกที่มีต่อการเปิดตัวซอฟต์แวร์และการประกาศของบริษัทต่างๆ
สร้างระบบรวบรวมข่าวสารทางเทคนิคคุณภาพสูงสำหรับกลุ่มเป้าหมายเฉพาะ
การวิจัยเชิงวิชาการเกี่ยวกับการแพร่กระจายของข้อมูลในชุมชนทางเทคนิค
ความท้าทายในการ Scrape
ความท้าทายทางเทคนิคที่คุณอาจพบเมื่อ Scrape Hacker News
การทำ parsing โครงสร้างตาราง HTML แบบซ้อนกันที่ใช้ในการจัดเลย์เอาต์
การจัดการกับข้อความเวลาสัมพัทธ์ เช่น '2 hours ago' สำหรับการจัดเก็บในฐานข้อมูล
การจัดการกับข้อจำกัดอัตรา (rate limits) ฝั่งเซิร์ฟเวอร์ที่อาจทำให้โดนแบน IP ชั่วคราว
การสกัดลำดับขั้นของความคิดเห็นที่ลึกและกระจายอยู่ในหลายหน้า
สกัดข้อมูลจาก Hacker News ด้วย AI
ไม่ต้องเขียนโค้ด สกัดข้อมูลภายในไม่กี่นาทีด้วยระบบอัตโนมัติที่ขับเคลื่อนด้วย AI
วิธีการทำงาน
อธิบายสิ่งที่คุณต้องการ
บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก Hacker News แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
AI สกัดข้อมูล
ปัญญาประดิษฐ์ของเรานำทาง Hacker News จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
รับข้อมูลของคุณ
รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
ทำไมต้องใช้ AI ในการสกัดข้อมูล
AI ทำให้การสกัดข้อมูลจาก Hacker News เป็นเรื่องง่ายโดยไม่ต้องเขียนโค้ด แพลตฟอร์มที่ขับเคลื่อนด้วยปัญญาประดิษฐ์ของเราเข้าใจว่าคุณต้องการข้อมูลอะไร — แค่อธิบายเป็นภาษาธรรมชาติ แล้ว AI จะสกัดให้โดยอัตโนมัติ
How to scrape with AI:
- อธิบายสิ่งที่คุณต้องการ: บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก Hacker News แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
- AI สกัดข้อมูล: ปัญญาประดิษฐ์ของเรานำทาง Hacker News จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
- รับข้อมูลของคุณ: รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
Why use AI for scraping:
- เลือกบทความแบบ point-and-click โดยไม่ต้องเขียน CSS selectors ที่ซับซ้อน
- จัดการปุ่ม 'More' อัตโนมัติเพื่อการแบ่งหน้า (pagination) ที่ราบรื่น
- มีระบบรันบน cloud ในตัวเพื่อป้องกันไม่ให้ IP ท้องถิ่นของคุณถูกจำกัดอัตรา (rate-limited)
- กำหนดเวลาดึงข้อมูลเพื่อบันทึกหน้าแรกทุกชั่วโมงโดยอัตโนมัติ
- ส่งออกข้อมูลไปยัง Google Sheets หรือ Webhooks ได้โดยตรงเพื่อการแจ้งเตือนแบบเรียลไทม์
No-code web scrapers สำหรับ Hacker News
ทางเลือกแบบ point-and-click สำหรับการ scraping ด้วย AI
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape Hacker News โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
ความท้าทายทั่วไป
เส้นโค้งการเรียนรู้
การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
Selectors เสีย
การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
ปัญหาเนื้อหาไดนามิก
เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
ข้อจำกัด CAPTCHA
เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
การบล็อก IP
การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
No-code web scrapers สำหรับ Hacker News
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape Hacker News โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
- ติดตั้งส่วนขยายเบราว์เซอร์หรือสมัครใช้งานแพลตฟอร์ม
- นำทางไปยังเว็บไซต์เป้าหมายและเปิดเครื่องมือ
- เลือกองค์ประกอบข้อมูลที่ต้องการดึงด้วยการชี้และคลิก
- กำหนดค่า CSS selectors สำหรับแต่ละฟิลด์ข้อมูล
- ตั้งค่ากฎการแบ่งหน้าเพื่อ scrape หลายหน้า
- จัดการ CAPTCHA (มักต้องแก้ไขด้วยตนเอง)
- กำหนดค่าการตั้งเวลาสำหรับการรันอัตโนมัติ
- ส่งออกข้อมูลเป็น CSV, JSON หรือเชื่อมต่อผ่าน API
ความท้าทายทั่วไป
- เส้นโค้งการเรียนรู้: การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
- Selectors เสีย: การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
- ปัญหาเนื้อหาไดนามิก: เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
- ข้อจำกัด CAPTCHA: เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
- การบล็อก IP: การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
ตัวอย่างโค้ด
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# บทความจะอยู่ในแถวที่มี class 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Title: {title}
Link: {link}
---')
except Exception as e:
print(f'Scraping failed: {e}')เมื่อไหร่ควรใช้
เหมาะที่สุดสำหรับหน้า HTML แบบ static ที่มี JavaScript น้อย เหมาะสำหรับบล็อก ไซต์ข่าว และหน้าสินค้า e-commerce ธรรมดา
ข้อดี
- ●ประมวลผลเร็วที่สุด (ไม่มี overhead ของเบราว์เซอร์)
- ●ใช้ทรัพยากรน้อยที่สุด
- ●ง่ายต่อการทำงานแบบขนานด้วย asyncio
- ●เหมาะมากสำหรับ API และหน้า static
ข้อจำกัด
- ●ไม่สามารถรัน JavaScript ได้
- ●ล้มเหลวใน SPA และเนื้อหาไดนามิก
- ●อาจมีปัญหากับระบบ anti-bot ที่ซับซ้อน
วิธีสเครปข้อมูล Hacker News ด้วยโค้ด
Python + Requests
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# บทความจะอยู่ในแถวที่มี class 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Title: {title}
Link: {link}
---')
except Exception as e:
print(f'Scraping failed: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://news.ycombinator.com/')
# รอให้ตารางโหลดเสร็จ
page.wait_for_selector('.athing')
# สกัดหัวข้อบทความและลิงก์ทั้งหมด
items = page.query_selector_all('.athing')
for item in items:
title_link = item.query_selector('.titleline > a')
if title_link:
print(title_link.inner_text(), title_link.get_attribute('href'))
browser.close()Python + Scrapy
import scrapy
class HackerNewsSpider(scrapy.Spider):
name = 'hn_spider'
start_urls = ['https://news.ycombinator.com/']
def parse(self, response):
for post in response.css('.athing'):
yield {
'id': post.attrib.get('id'),
'title': post.css('.titleline > a::text').get(),
'link': post.css('.titleline > a::attr(href)').get(),
}
# ติดตามลิงก์ 'More' สำหรับการแบ่งหน้า (pagination)
next_page = response.css('a.morelink::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com/');
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.athing'));
return items.map(item => ({
title: item.querySelector('.titleline > a').innerText,
url: item.querySelector('.titleline > a').href
}));
});
console.log(results);
await browser.close();
})();คุณสามารถทำอะไรกับข้อมูล Hacker News
สำรวจการใช้งานจริงและข้อมูลเชิงลึกจากข้อมูล Hacker News
การค้นหาเทรนด์สตาร์ทอัพ
ระบุว่าอุตสาหกรรมหรือประเภทผลิตภัณฑ์ใดที่กำลังถูกเปิดตัวและพูดถึงบ่อยที่สุด
วิธีการนำไปใช้:
- 1ดึงข้อมูลจากหมวดหมู่ 'Show HN' เป็นประจำทุกสัปดาห์
- 2ทำความสะอาดและจัดหมวดหมู่คำอธิบายสตาร์ทอัพโดยใช้ NLP
- 3จัดอันดับเทรนด์ตามจำนวน Upvote ของชุมชนและความรู้สึก (sentiment) ในความคิดเห็น
ใช้ Automatio เพื่อดึงข้อมูลจาก Hacker News และสร้างแอปพลิเคชันเหล่านี้โดยไม่ต้องเขียนโค้ด
คุณสามารถทำอะไรกับข้อมูล Hacker News
- การค้นหาเทรนด์สตาร์ทอัพ
ระบุว่าอุตสาหกรรมหรือประเภทผลิตภัณฑ์ใดที่กำลังถูกเปิดตัวและพูดถึงบ่อยที่สุด
- ดึงข้อมูลจากหมวดหมู่ 'Show HN' เป็นประจำทุกสัปดาห์
- ทำความสะอาดและจัดหมวดหมู่คำอธิบายสตาร์ทอัพโดยใช้ NLP
- จัดอันดับเทรนด์ตามจำนวน Upvote ของชุมชนและความรู้สึก (sentiment) ในความคิดเห็น
- การสรรหาบุคลากรสายเทค
ดึงข้อมูลรายการรับสมัครงานและรายละเอียดบริษัทจาก Thread รับสมัครงานรายเดือน
- ตรวจสอบ ID ของ Thread รายเดือน 'Who is hiring'
- ดึงข้อมูลความคิดเห็นระดับบนสุดทั้งหมดซึ่งมีรายละเอียดงาน
- Parse ข้อความเพื่อหา tech stack เฉพาะ เช่น Rust, AI หรือ React
- ข้อมูลเชิงลึกด้านการแข่งขัน
ติดตามการกล่าวถึงคู่แข่งในความคิดเห็นเพื่อทำความเข้าใจการรับรู้ของสาธารณะและข้อร้องเรียนต่างๆ
- ตั้งค่าระบบดึงข้อมูลตาม keyword สำหรับชื่อแบรนด์เฉพาะ
- สกัดความคิดเห็นของผู้ใช้และเวลาที่โพสต์เพื่อวิเคราะห์ความรู้สึก
- จัดทำรายงานรายสัปดาห์เกี่ยวกับความแข็งแกร่งของแบรนด์เทียบกับคู่แข่ง
- การคัดกรองเนื้อหาอัตโนมัติ
สร้างจดหมายข่าวทางเทคนิคที่มีข้อมูลคุณภาพสูงซึ่งรวมเฉพาะเรื่องราวที่เกี่ยวข้องที่สุดเท่านั้น
- ดึงข้อมูลหน้าแรกทุกๆ 6 ชั่วโมง
- กรองโพสต์ที่มีคะแนนเกิน 200 แต้ม
- ส่งลิงก์เหล่านี้ไปยัง Telegram bot หรืออีเมลโดยอัตโนมัติ
- การหาโอกาสทางธุรกิจสำหรับ Venture Capital
ค้นหาสตาร์ทอัพในระยะเริ่มต้นที่ได้รับการตอบรับอย่างมากจากชุมชน
- ติดตามโพสต์ 'Show HN' ที่ขึ้นหน้าแรก
- ตรวจสอบอัตราการเติบโตของ Upvote ในช่วง 4 ชั่วโมงแรก
- แจ้งเตือนนักวิเคราะห์เมื่อโพสต์แสดงรูปแบบการเติบโตแบบไวรัล
เพิ่มพลังให้เวิร์กโฟลว์ของคุณด้วย ระบบอัตโนมัติ AI
Automatio รวมพลังของ AI agents การอัตโนมัติเว็บ และการผสานรวมอัจฉริยะเพื่อช่วยให้คุณทำงานได้มากขึ้นในเวลาน้อยลง
เคล็ดลับมืออาชีพสำหรับการ Scrape Hacker News
คำแนะนำจากผู้เชี่ยวชาญสำหรับการดึงข้อมูลจาก Hacker News อย่างประสบความสำเร็จ
ใช้ Firebase API อย่างเป็นทางการสำหรับการรวบรวมข้อมูลย้อนหลังจำนวนมหาศาล เพื่อหลีกเลี่ยงความซับซ้อนในการทำ HTML parsing
ตั้งค่า User-Agent แบบกำหนดเองเสมอเพื่อระบุบอทของคุณอย่างรับผิดชอบและหลีกเลี่ยงการถูกบล็อกทันที
กำหนดช่วงเวลาหยุดพัก (sleep interval) แบบสุ่ม 3-7 วินาทีระหว่างคำขอ เพื่อเลียนแบบพฤติกรรมการท่องเว็บของมนุษย์
กำหนดเป้าหมายไปที่ subdirectories เฉพาะ เช่น /newest สำหรับเรื่องราวใหม่ หรือ /ask สำหรับการพูดคุยในชุมชน
จัดเก็บ 'Item ID' เป็น primary key เพื่อหลีกเลี่ยงข้อมูลซ้ำเมื่อดึงข้อมูลหน้าแรกบ่อยๆ
ดึงข้อมูลในช่วงเวลาที่มีผู้ใช้งานน้อย (เช่น เวลากลางคืนตามโซน UTC) เพื่อความเร็วในการตอบสนองที่สูงขึ้นและลดความเสี่ยงในการถูกจำกัด rate-limiting
คำรับรอง
ผู้ใช้ของเราพูดอย่างไร
เข้าร่วมกับผู้ใช้ที่พึงพอใจนับพันที่ได้เปลี่ยนแปลงเวิร์กโฟลว์ของพวกเขา
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
ที่เกี่ยวข้อง Web Scraping




คำถามที่พบบ่อยเกี่ยวกับ Hacker News
ค้นหาคำตอบสำหรับคำถามทั่วไปเกี่ยวกับ Hacker News