วิธีการ Scrape Seeking Alpha: ข้อมูลทางการเงินและบทถอดเสียง (Transcripts)
เรียนรู้วิธีการ Scrape Seeking Alpha เพื่อดึงข่าวหุ้น, การจัดอันดับของนักวิเคราะห์ และบทถอดเสียงผลประกอบการ เรียนรู้วิธีข้าม Cloudflare...
ตรวจพบการป้องกันบอท
- Cloudflare
- WAF และการจัดการบอทระดับองค์กร ใช้ JavaScript challenges, CAPTCHAs และการวิเคราะห์พฤติกรรม ต้องมีระบบอัตโนมัติของเบราว์เซอร์พร้อมการตั้งค่าซ่อนตัว
- DataDome
- การตรวจจับบอทแบบเรียลไทม์ด้วยโมเดล ML วิเคราะห์ลายนิ้วมืออุปกรณ์ สัญญาณเครือข่าย และรูปแบบพฤติกรรม พบบ่อยในเว็บไซต์อีคอมเมิร์ซ
- Google reCAPTCHA
- ระบบ CAPTCHA ของ Google v2 ต้องมีการโต้ตอบของผู้ใช้ v3 ทำงานเงียบๆ ด้วยคะแนนความเสี่ยง สามารถแก้ได้ด้วยบริการ CAPTCHA
- การจำกัดอัตรา
- จำกัดคำขอต่อ IP/เซสชันตามเวลา สามารถหลีกเลี่ยงได้ด้วยพร็อกซีหมุนเวียน การหน่วงเวลาคำขอ และการสแกรปแบบกระจาย
- การบล็อก IP
- บล็อก IP ของศูนย์ข้อมูลที่รู้จักและที่อยู่ที่ถูกทำเครื่องหมาย ต้องใช้พร็อกซีที่อยู่อาศัยหรือมือถือเพื่อหลีกเลี่ยงอย่างมีประสิทธิภาพ
เกี่ยวกับ Seeking Alpha
ค้นพบสิ่งที่ Seeking Alpha นำเสนอและข้อมูลที่มีค่าที่สามารถดึงได้
ศูนย์กลางชั้นนำสำหรับการวิเคราะห์ทางการเงิน
Seeking Alpha เป็นแพลตฟอร์มวิจัยทางการเงินแบบ crowd-sourced ชั้นนำที่เป็นสะพานเชื่อมสำคัญระหว่างข้อมูลตลาดดิบและข้อมูลเชิงลึกด้านการลงทุนที่นำไปใช้งานได้จริง โดยเป็นที่รวบรวมบทความวิเคราะห์ ข่าวตลาดแบบเรียลไทม์ และแหล่งเก็บข้อมูลบทถอดเสียงการประชุมผลประกอบการ (earnings transcripts) ที่ครอบคลุมที่สุดในอินเทอร์เน็ตสำหรับบริษัทมหาชนหลายพันแห่ง
ระบบนิเวศข้อมูลที่หลากหลาย
แพลตฟอร์มนำเสนอข้อมูลทั้งแบบที่มีโครงสร้างและไม่มีโครงสร้างมากมาย รวมถึงแนวคิดเรื่องหุ้น ประวัติการจ่ายเงินปันผล และคะแนน Quant ที่เป็นกรรมสิทธิ์เฉพาะ เนื้อหาเหล่านี้ได้รับการจัดการโดยทีมบรรณาธิการมืออาชีพ และสร้างขึ้นโดยนักวิเคราะห์อิสระหลายพันคน ซึ่งการมีส่วนร่วมของพวกเขาต้องเป็นไปตามมาตรฐานคุณภาพและการปฏิบัติตามกฎระเบียบที่เข้มงวดก่อนการเผยแพร่
คุณค่าเชิงกลยุทธ์สำหรับการดึงข้อมูล
การ Scrape Seeking Alpha มีความสำคัญอย่างยิ่งสำหรับนักวิเคราะห์ทางการเงินและนักเทรดเชิงปริมาณ (quantitative traders) ที่ต้องการทำ sentiment analysis, ติดตามแนวโน้มผลประกอบการย้อนหลัง และตรวจสอบข่าวสารผ่าน ticker เฉพาะ ข้อมูลเหล่านี้ให้ข้อมูลเชิงลึกที่ละเอียดเกี่ยวกับจิตวิทยาตลาดและผลการดำเนินงานของบริษัท ซึ่งสามารถนำไปใช้สร้าง financial models ที่ซับซ้อนและทำข้อมูลเชิงลึกด้านการแข่งขันได้
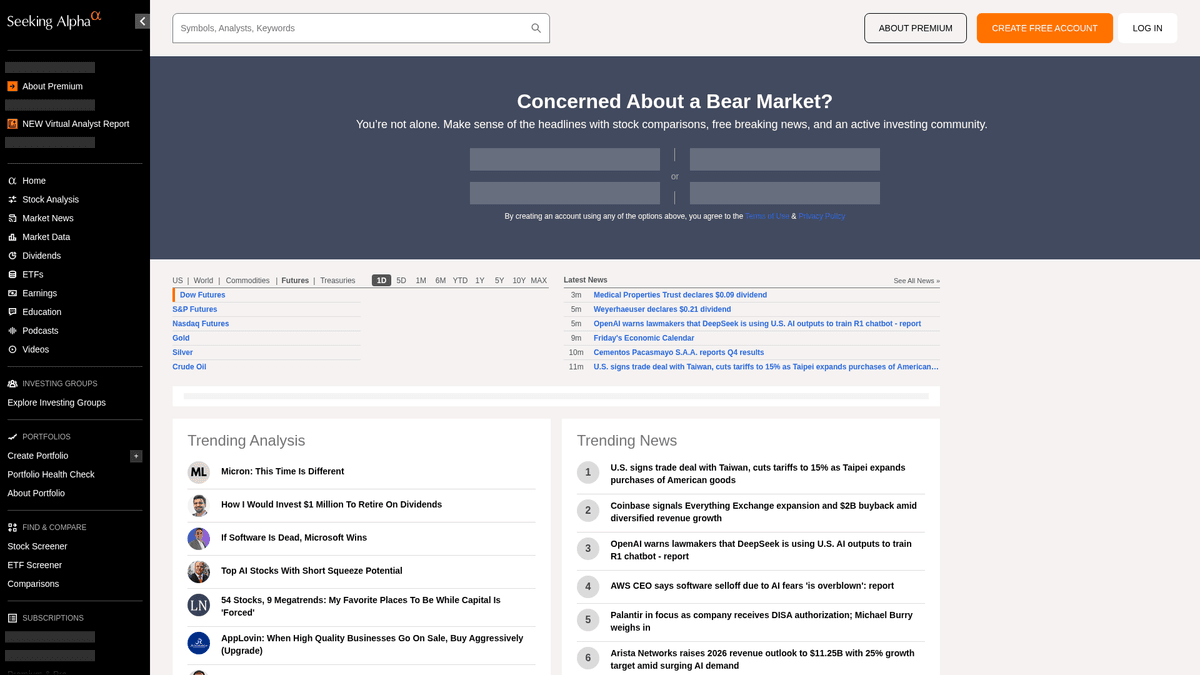
ทำไมต้อง Scrape Seeking Alpha?
ค้นพบคุณค่าทางธุรกิจและกรณีการใช้งานสำหรับการดึงข้อมูลจาก Seeking Alpha
การสร้างเครื่องมือวิเคราะห์ความรู้สึกเชิงปริมาณสำหรับ algorithmic trading
การรวบรวมบทถอดเสียงการประชุมผลประกอบการสำหรับงานวิจัยทางการเงินที่ใช้ LLM
การตรวจสอบการเปลี่ยนแปลงเงินปันผลและอัตราการจ่ายเงินปันผลสำหรับพอร์ตรายได้
การติดตามผลงานของนักวิเคราะห์และการเปลี่ยนแปลงการจัดอันดับในแต่ละภาคส่วน
การพัฒนาแดชบอร์ดข่าวสารตลาดแบบเรียลไทม์สำหรับลูกค้าสถาบัน
การวิเคราะห์การแข่งขันย้อนหลังเกี่ยวกับคำแนะนำของบริษัทเทียบกับผลลัพธ์จริง
ความท้าทายในการ Scrape
ความท้าทายทางเทคนิคที่คุณอาจพบเมื่อ Scrape Seeking Alpha
ระบบตรวจจับ anti-bot ที่เข้มงวดโดยใช้การป้องกันของ Cloudflare และ DataDome
ความจำเป็นในการเข้าสู่ระบบเพื่อเข้าถึงเนื้อหาบทถอดเสียงผลประกอบการแบบเต็ม
การโหลดข้อมูลแบบไดนามิกผ่าน AJAX/XHR ที่ต้องการการเรนเดอร์ผ่านเบราว์เซอร์เต็มรูปแบบ
การจำกัดอัตรา (rate limiting) ที่ซับซ้อนซึ่งอาจส่งผลให้ถูกแบน IP อย่างถาวรสำหรับคำขอที่มีความถี่สูง
โครงสร้าง HTML ที่ซับซ้อนพร้อมกับ CSS selectors ที่เปลี่ยนแปลงบ่อย
สกัดข้อมูลจาก Seeking Alpha ด้วย AI
ไม่ต้องเขียนโค้ด สกัดข้อมูลภายในไม่กี่นาทีด้วยระบบอัตโนมัติที่ขับเคลื่อนด้วย AI
วิธีการทำงาน
อธิบายสิ่งที่คุณต้องการ
บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก Seeking Alpha แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
AI สกัดข้อมูล
ปัญญาประดิษฐ์ของเรานำทาง Seeking Alpha จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
รับข้อมูลของคุณ
รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
ทำไมต้องใช้ AI ในการสกัดข้อมูล
AI ทำให้การสกัดข้อมูลจาก Seeking Alpha เป็นเรื่องง่ายโดยไม่ต้องเขียนโค้ด แพลตฟอร์มที่ขับเคลื่อนด้วยปัญญาประดิษฐ์ของเราเข้าใจว่าคุณต้องการข้อมูลอะไร — แค่อธิบายเป็นภาษาธรรมชาติ แล้ว AI จะสกัดให้โดยอัตโนมัติ
How to scrape with AI:
- อธิบายสิ่งที่คุณต้องการ: บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก Seeking Alpha แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
- AI สกัดข้อมูล: ปัญญาประดิษฐ์ของเรานำทาง Seeking Alpha จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
- รับข้อมูลของคุณ: รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
Why use AI for scraping:
- สภาพแวดล้อมแบบ no-code ช่วยลดความจำเป็นในการจัดการไลบรารี browser automation ที่ซับซ้อน
- ความสามารถในตัวสำหรับการจัดการไซต์ที่ใช้ JavaScript หนักและการโหลดเนื้อหาแบบไดนามิก
- การประมวลผลบนคลาวด์ช่วยให้เก็บรวบรวมข้อมูลปริมาณมากตามตารางเวลาได้โดยไม่ต้องใช้ทรัพยากรเครื่องในเครื่อง
- การจัดการรูปแบบการตรวจจับ anti-bot มาตรฐานและ browser fingerprinting โดยอัตโนมัติ
No-code web scrapers สำหรับ Seeking Alpha
ทางเลือกแบบ point-and-click สำหรับการ scraping ด้วย AI
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape Seeking Alpha โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
ความท้าทายทั่วไป
เส้นโค้งการเรียนรู้
การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
Selectors เสีย
การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
ปัญหาเนื้อหาไดนามิก
เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
ข้อจำกัด CAPTCHA
เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
การบล็อก IP
การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
No-code web scrapers สำหรับ Seeking Alpha
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape Seeking Alpha โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
- ติดตั้งส่วนขยายเบราว์เซอร์หรือสมัครใช้งานแพลตฟอร์ม
- นำทางไปยังเว็บไซต์เป้าหมายและเปิดเครื่องมือ
- เลือกองค์ประกอบข้อมูลที่ต้องการดึงด้วยการชี้และคลิก
- กำหนดค่า CSS selectors สำหรับแต่ละฟิลด์ข้อมูล
- ตั้งค่ากฎการแบ่งหน้าเพื่อ scrape หลายหน้า
- จัดการ CAPTCHA (มักต้องแก้ไขด้วยตนเอง)
- กำหนดค่าการตั้งเวลาสำหรับการรันอัตโนมัติ
- ส่งออกข้อมูลเป็น CSV, JSON หรือเชื่อมต่อผ่าน API
ความท้าทายทั่วไป
- เส้นโค้งการเรียนรู้: การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
- Selectors เสีย: การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
- ปัญหาเนื้อหาไดนามิก: เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
- ข้อจำกัด CAPTCHA: เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
- การบล็อก IP: การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
ตัวอย่างโค้ด
import requests
from bs4 import BeautifulSoup
# URL สำหรับข่าวสารตลาดล่าสุด
url = 'https://seekingalpha.com/market-news'
# headers เบราว์เซอร์มาตรฐานเพื่อเลียนแบบพฤติกรรมมนุษย์
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9',
'Referer': 'https://seekingalpha.com/'
}
def scrape_sa_news():
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# ดึงหัวข้อข่าวโดยใช้แอตทริบิวต์ data-test-id
headlines = soup.find_all('a', {'data-test-id': 'post-list-item-title'})
for item in headlines:
print(f'News Title: {item.text.strip()}')
else:
print(f'ถูกบล็อกด้วยสถานะ: {response.status_code}')
except Exception as e:
print(f'เกิดข้อผิดพลาด: {e}')
if __name__ == "__main__":
scrape_sa_news()เมื่อไหร่ควรใช้
เหมาะที่สุดสำหรับหน้า HTML แบบ static ที่มี JavaScript น้อย เหมาะสำหรับบล็อก ไซต์ข่าว และหน้าสินค้า e-commerce ธรรมดา
ข้อดี
- ●ประมวลผลเร็วที่สุด (ไม่มี overhead ของเบราว์เซอร์)
- ●ใช้ทรัพยากรน้อยที่สุด
- ●ง่ายต่อการทำงานแบบขนานด้วย asyncio
- ●เหมาะมากสำหรับ API และหน้า static
ข้อจำกัด
- ●ไม่สามารถรัน JavaScript ได้
- ●ล้มเหลวใน SPA และเนื้อหาไดนามิก
- ●อาจมีปัญหากับระบบ anti-bot ที่ซับซ้อน
วิธีสเครปข้อมูล Seeking Alpha ด้วยโค้ด
Python + Requests
import requests
from bs4 import BeautifulSoup
# URL สำหรับข่าวสารตลาดล่าสุด
url = 'https://seekingalpha.com/market-news'
# headers เบราว์เซอร์มาตรฐานเพื่อเลียนแบบพฤติกรรมมนุษย์
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9',
'Referer': 'https://seekingalpha.com/'
}
def scrape_sa_news():
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# ดึงหัวข้อข่าวโดยใช้แอตทริบิวต์ data-test-id
headlines = soup.find_all('a', {'data-test-id': 'post-list-item-title'})
for item in headlines:
print(f'News Title: {item.text.strip()}')
else:
print(f'ถูกบล็อกด้วยสถานะ: {response.status_code}')
except Exception as e:
print(f'เกิดข้อผิดพลาด: {e}')
if __name__ == "__main__":
scrape_sa_news()Python + Playwright
from playwright.sync_api import sync_playwright
def run(playwright):
# เริ่มใช้งานเบราว์เซอร์ Chromium
browser = playwright.chromium.launch(headless=True)
context = browser.new_context(
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
)
page = context.new_page()
try:
# ไปที่หน้าบทถอดเสียงของสัญลักษณ์หุ้นเฉพาะ
page.goto('https://seekingalpha.com/symbol/AAPL/transcripts')
# รอให้เนื้อหาหลักเรนเดอร์แบบไดนามิก
page.wait_for_selector('article', timeout=15000)
# ระบุตำแหน่งและดึงหัวข้อบทถอดเสียง
titles = page.locator('h3').all_inner_texts()
for title in titles:
print(f'Found Transcript: {title}')
except Exception as e:
print(f'การดึงข้อมูลล้มเหลว: {e}')
finally:
browser.close()
with sync_playwright() as playwright:
run(playwright)Python + Scrapy
import scrapy
class SeekingAlphaSpider(scrapy.Spider):
name = 'sa_spider'
allowed_domains = ['seekingalpha.com']
start_urls = ['https://seekingalpha.com/latest-articles']
custom_settings = {
'DOWNLOAD_DELAY': 8,
'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/120.0.0.0',
'ROBOTSTXT_OBEY': False,
'COOKIES_ENABLED': True
}
def parse(self, response):
for article in response.css('article'):
yield {
'title': article.css('h3 a::text').get(),
'link': response.urljoin(article.css('h3 a::attr(href)').get()),
'author': article.css('span[data-test-id="author-name"]::text').get()
}
# จัดการการเปลี่ยนหน้าแบบง่ายผ่านลิงก์ 'next'
next_page = response.css('a.next_page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// ตั้งค่า User-Agent คุณภาพสูง
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36');
try {
// ไปที่หน้าแรกของ Seeking Alpha
await page.goto('https://seekingalpha.com/', { waitUntil: 'networkidle2' });
// ประมวลผลสคริปต์ในบริบทของเบราว์เซอร์เพื่อดึงหัวข้อ
const trending = await page.evaluate(() => {
const nodes = Array.from(document.querySelectorAll('h3'));
return nodes.map(n => n.innerText.trim());
});
console.log('Trending Content:', trending);
} catch (err) {
console.error('Puppeteer พบข้อผิดพลาด:', err);
} finally {
await browser.close();
}
})();คุณสามารถทำอะไรกับข้อมูล Seeking Alpha
สำรวจการใช้งานจริงและข้อมูลเชิงลึกจากข้อมูล Seeking Alpha
การวิเคราะห์ความรู้สึกเชิงปริมาณ (Quantitative Sentiment Analysis)
บริษัททางการเงินใช้บทความของนักวิเคราะห์เพื่อกำหนดความรู้สึกของตลาดสำหรับกลุ่มหุ้นเฉพาะ
วิธีการนำไปใช้:
- 1ดึงบทความวิเคราะห์ทั้งหมดสำหรับ ticker ในอุตสาหกรรมเฉพาะ
- 2ประมวลผลเนื้อหาผ่าน NLP engine เพื่อคำนวณค่าความเป็นบวก/ลบของความรู้สึก (sentiment polarity)
- 3รวมคะแนน sentiment เข้ากับอัลกอริทึมการเทรดที่มีอยู่
- 4ตั้งค่าการแจ้งเตือนซื้อ/ขายอัตโนมัติเมื่อเกิดการเปลี่ยนแปลงของ sentiment
ใช้ Automatio เพื่อดึงข้อมูลจาก Seeking Alpha และสร้างแอปพลิเคชันเหล่านี้โดยไม่ต้องเขียนโค้ด
คุณสามารถทำอะไรกับข้อมูล Seeking Alpha
- การวิเคราะห์ความรู้สึกเชิงปริมาณ (Quantitative Sentiment Analysis)
บริษัททางการเงินใช้บทความของนักวิเคราะห์เพื่อกำหนดความรู้สึกของตลาดสำหรับกลุ่มหุ้นเฉพาะ
- ดึงบทความวิเคราะห์ทั้งหมดสำหรับ ticker ในอุตสาหกรรมเฉพาะ
- ประมวลผลเนื้อหาผ่าน NLP engine เพื่อคำนวณค่าความเป็นบวก/ลบของความรู้สึก (sentiment polarity)
- รวมคะแนน sentiment เข้ากับอัลกอริทึมการเทรดที่มีอยู่
- ตั้งค่าการแจ้งเตือนซื้อ/ขายอัตโนมัติเมื่อเกิดการเปลี่ยนแปลงของ sentiment
- การดึงข้อมูลเชิงลึกจากผลประกอบการ
ดึงข้อมูลคำแนะนำที่สำคัญของบริษัทโดยตรงจากบทถอดเสียงผลประกอบการเพื่อการรายงานที่รวดเร็ว
- ตั้งค่าระบบ Scrape อัตโนมัติรายวันในส่วนบทถอดเสียงผลประกอบการ (Earnings Transcripts)
- ค้นหาคีย์เวิร์ดทางการเงินเฉพาะ เช่น 'EBITDA' หรือ 'Outlook'
- คัดแยกประโยคที่มีตัวชี้วัดคำแนะนำจากฝ่ายบริหาร (management guidance)
- ส่งออกข้อมูลที่พบไปยังไฟล์ CSV ที่มีโครงสร้างเพื่อให้นักลงทุนพิจารณา
- การเปรียบเทียบอัตราผลตอบแทนจากเงินปันผล
เปรียบเทียบผลการดำเนินงานด้านเงินปันผลของหุ้นหลายพันตัวเพื่อหาโอกาสในการรับผลตอบแทน
- Scrape ประวัติการปันผลและอัตราการจ่ายปันผล (payout ratios) สำหรับรายการหุ้นที่กำหนด
- คำนวณอัตราผลตอบแทนเฉลี่ยเทียบกับแนวโน้มในอดีตโดยใช้ข้อมูลที่ Scrape มา
- ระบุหุ้นที่มีการเพิ่มการจ่ายเงินปันผลเมื่อเร็วๆ นี้
- อัปเดตแดชบอร์ดส่วนตัวด้วยการเปรียบเทียบอัตราผลตอบแทนแบบเรียลไทม์
- การติดตามผลงานของนักวิเคราะห์
ระบุนักเขียนที่มีความแม่นยำสูงเพื่อติดตามแนวคิดการลงทุนที่ดีกว่า
- Scrape คะแนนย้อนหลังและบทความจากนักเขียนที่ได้รับการจัดอันดับสูงสุด
- ตรวจสอบวันที่เผยแพร่บทความกับผลการดำเนินงานของราคาหุ้น
- จัดอันดับนักเขียนตามความแม่นยำของคำแนะนำ 'ซื้อ' หรือ 'ขาย'
- ส่งการแจ้งเตือนอัตโนมัติเมื่อนักเขียนอันดับสูงโพสต์แนวคิดใหม่ๆ
เพิ่มพลังให้เวิร์กโฟลว์ของคุณด้วย ระบบอัตโนมัติ AI
Automatio รวมพลังของ AI agents การอัตโนมัติเว็บ และการผสานรวมอัจฉริยะเพื่อช่วยให้คุณทำงานได้มากขึ้นในเวลาน้อยลง
เคล็ดลับมืออาชีพสำหรับการ Scrape Seeking Alpha
คำแนะนำจากผู้เชี่ยวชาญสำหรับการดึงข้อมูลจาก Seeking Alpha อย่างประสบความสำเร็จ
ใช้ residential proxies ระดับพรีเมียมเพื่อข้ามการป้องกันของ Cloudflare/DataDome อย่างมีประสิทธิภาพ
หมุนเวียน (Rotate) User-Agent strings และรักษา browser fingerprints ให้คงที่ภายในเซสชันเดียวกัน
กำหนดเวลารอแบบสุ่มระหว่าง 10 ถึง 30 วินาที เพื่อเลียนแบบพฤติกรรมการใช้งานของมนุษย์
ทำการ Scrape ในช่วงตลาดปิดหรือวันหยุดสุดสัปดาห์เพื่อลดโอกาสที่จะถูกจำกัดอัตราการเข้าถึง (rate limits) ในช่วงที่มีการใช้งานสูง
ตรวจสอบแท็บ 'Network' ใน DevTools เพื่อหา API endpoints ภายในที่เป็น JSON (v3/api) เพื่อให้ได้ข้อมูลที่สะอาดกว่า
เก็บ session cookies แบบถาวรหากคุณต้องการ Scrape ข้อมูลที่อยู่หลังหน้า login
คำรับรอง
ผู้ใช้ของเราพูดอย่างไร
เข้าร่วมกับผู้ใช้ที่พึงพอใจนับพันที่ได้เปลี่ยนแปลงเวิร์กโฟลว์ของพวกเขา
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
ที่เกี่ยวข้อง Web Scraping
How to Scrape Moon.ly | Step-by-Step NFT Data Extraction Guide
How to Scrape Yahoo Finance: Extract Stock Market Data
How to Scrape Rocket Mortgage: A Comprehensive Guide
How to Scrape Open Collective: Financial and Contributor Data Guide
How to Scrape jup.ag: Jupiter DEX Web Scraper Guide
How to Scrape Indiegogo: The Ultimate Crowdfunding Data Extraction Guide
How to Scrape ICO Drops: Comprehensive Crypto Data Guide
How to Scrape Crypto.com: Comprehensive Market Data Guide
คำถามที่พบบ่อยเกี่ยวกับ Seeking Alpha
ค้นหาคำตอบสำหรับคำถามทั่วไปเกี่ยวกับ Seeking Alpha