วิธีขูดข้อมูลจาก Web Designer News
เรียนรู้วิธีขูดข้อมูลจาก Web Designer News เพื่อดึงเรื่องราวการออกแบบที่กำลังมาแรง, URL แหล่งที่มา และการระบุเวลา...
เกี่ยวกับ Web Designer News
ค้นพบสิ่งที่ Web Designer News นำเสนอและข้อมูลที่มีค่าที่สามารถดึงได้
ภาพรวมของ Web Designer News
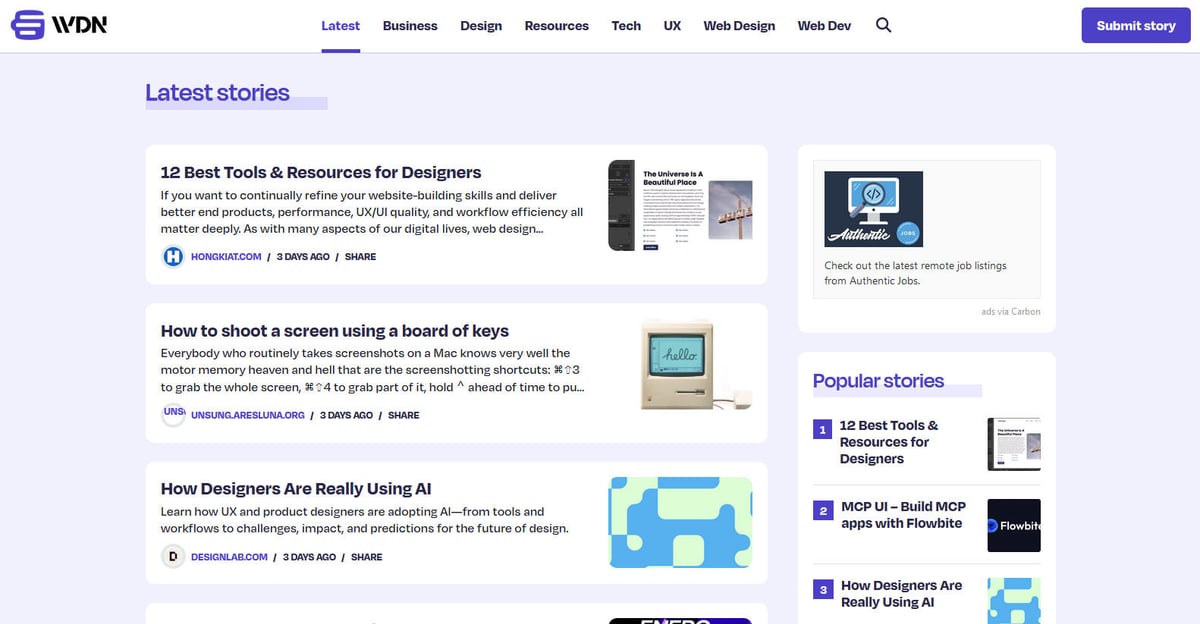
Web Designer News เป็นแพลตฟอร์มรวบรวมข่าวสารชั้นนำที่ขับเคลื่อนโดยชุมชน ซึ่งได้รับการคัดสรรมาเป็นพิเศษสำหรับระบบนิเวศการออกแบบและพัฒนาเว็บ นับตั้งแต่ก่อตั้ง แพลตฟอร์มนี้ทำหน้าที่เป็นศูนย์กลางที่ผู้เชี่ยวชาญสามารถค้นพบข่าวสาร บทช่วยสอน เครื่องมือ และทรัพยากรที่เกี่ยวข้องมากที่สุดจากทั่วอินเทอร์เน็ต ครอบคลุมหัวข้อที่หลากหลาย เช่น UX design, กลยุทธ์ทางธุรกิจ, การอัปเดตเทคโนโลยี และกราฟิกดีไซน์ โดยนำเสนอในรูปแบบฟีดที่เรียบง่ายและเรียงตามลำดับเวลา
สถาปัตยกรรมเว็บไซต์และศักยภาพของข้อมูล
สถาปัตยกรรมของเว็บไซต์สร้างขึ้นบน WordPress โดยมีโครงสร้างเลย์เอาต์ที่เป็นระเบียบสูงซึ่งจัดระเบียบเนื้อหาออกเป็นหมวดหมู่เฉพาะ เช่น 'Web Design', 'Web Dev', 'UX' และ 'Resources' เนื่องจากการรวบรวมข้อมูลจากบล็อกและวารสารส่วนตัวหลายพันแห่งมาไว้ในอินเทอร์เฟซเดียวที่ค้นหาได้ จึงทำหน้าที่เป็นตัวกรองข้อมูลอัจฉริยะคุณภาพสูงสำหรับอุตสาหกรรม โครงสร้างนี้ทำให้เป็นเป้าหมายที่เหมาะสำหรับการขูดข้อมูล เนื่องจากช่วยให้เข้าถึงกระแสข้อมูลอุตสาหกรรมที่มีมูลค่าสูงและผ่านการตรวจสอบมาแล้ว โดยไม่จำเป็นต้องไปขูดข้อมูลจากโดเมนแยกย่อยหลายร้อยแห่ง
ทำไมต้อง Scrape Web Designer News?
ค้นพบคุณค่าทางธุรกิจและกรณีการใช้งานสำหรับการดึงข้อมูลจาก Web Designer News
ระบุเทรนด์และเครื่องมือการออกแบบที่เกิดขึ้นใหม่แบบเรียลไทม์
รวบรวมข่าวสารอุตสาหกรรมโดยอัตโนมัติสำหรับจดหมายข่าวและฟีดโซเชียลมีเดีย
ทำการวิเคราะห์คู่แข่งโดยการตรวจสอบเนื้อหาที่โดดเด่นจากคู่แข่ง
สร้างชุดข้อมูลคุณภาพสูงสำหรับการฝึกฝนการประมวลผลภาษาธรรมชาติ (NLP)
สร้างคลังทรัพยากรการออกแบบส่วนกลางสำหรับฐานความรู้ภายในทีม
ความท้าทายในการ Scrape
ความท้าทายทางเทคนิคที่คุณอาจพบเมื่อ Scrape Web Designer News
การจัดการกับการเปลี่ยนเส้นทางทางเทคนิคผ่านระบบลิงก์ 'go' ภายในของไซต์
ความไม่สม่ำเสมอของรูปภาพตัวอย่างในโพสต์เก่าๆ ที่ถูกเก็บถาวร
การจำกัดอัตรา (rate limiting) ฝั่งเซิร์ฟเวอร์สำหรับคำขอที่มีความถี่สูงผ่านการป้องกันของ Nginx
สกัดข้อมูลจาก Web Designer News ด้วย AI
ไม่ต้องเขียนโค้ด สกัดข้อมูลภายในไม่กี่นาทีด้วยระบบอัตโนมัติที่ขับเคลื่อนด้วย AI
วิธีการทำงาน
อธิบายสิ่งที่คุณต้องการ
บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก Web Designer News แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
AI สกัดข้อมูล
ปัญญาประดิษฐ์ของเรานำทาง Web Designer News จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
รับข้อมูลของคุณ
รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
ทำไมต้องใช้ AI ในการสกัดข้อมูล
AI ทำให้การสกัดข้อมูลจาก Web Designer News เป็นเรื่องง่ายโดยไม่ต้องเขียนโค้ด แพลตฟอร์มที่ขับเคลื่อนด้วยปัญญาประดิษฐ์ของเราเข้าใจว่าคุณต้องการข้อมูลอะไร — แค่อธิบายเป็นภาษาธรรมชาติ แล้ว AI จะสกัดให้โดยอัตโนมัติ
How to scrape with AI:
- อธิบายสิ่งที่คุณต้องการ: บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก Web Designer News แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
- AI สกัดข้อมูล: ปัญญาประดิษฐ์ของเรานำทาง Web Designer News จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
- รับข้อมูลของคุณ: รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
Why use AI for scraping:
- เวิร์กโฟลว์แบบ no-code โดยสมบูรณ์สำหรับนักออกแบบและนักการตลาดที่ไม่ต้องการเขียนโค้ด
- การตั้งกำหนดการบนคลาวด์ช่วยให้ดึงข้อมูลข่าวรายวันได้โดยไม่ต้องลงมือเอง
- มีระบบจัดการการเปลี่ยนหน้า (pagination) และการตรวจจับองค์ประกอบที่มีโครงสร้างในตัว
- เชื่อมต่อโดยตรงกับ Google Sheets เพื่อการกระจายข้อมูลในทันที
No-code web scrapers สำหรับ Web Designer News
ทางเลือกแบบ point-and-click สำหรับการ scraping ด้วย AI
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape Web Designer News โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
ความท้าทายทั่วไป
เส้นโค้งการเรียนรู้
การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
Selectors เสีย
การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
ปัญหาเนื้อหาไดนามิก
เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
ข้อจำกัด CAPTCHA
เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
การบล็อก IP
การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
No-code web scrapers สำหรับ Web Designer News
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape Web Designer News โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
- ติดตั้งส่วนขยายเบราว์เซอร์หรือสมัครใช้งานแพลตฟอร์ม
- นำทางไปยังเว็บไซต์เป้าหมายและเปิดเครื่องมือ
- เลือกองค์ประกอบข้อมูลที่ต้องการดึงด้วยการชี้และคลิก
- กำหนดค่า CSS selectors สำหรับแต่ละฟิลด์ข้อมูล
- ตั้งค่ากฎการแบ่งหน้าเพื่อ scrape หลายหน้า
- จัดการ CAPTCHA (มักต้องแก้ไขด้วยตนเอง)
- กำหนดค่าการตั้งเวลาสำหรับการรันอัตโนมัติ
- ส่งออกข้อมูลเป็น CSV, JSON หรือเชื่อมต่อผ่าน API
ความท้าทายทั่วไป
- เส้นโค้งการเรียนรู้: การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
- Selectors เสีย: การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
- ปัญหาเนื้อหาไดนามิก: เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
- ข้อจำกัด CAPTCHA: เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
- การบล็อก IP: การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
ตัวอย่างโค้ด
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# ส่งคำขอไปยังหน้าหลัก
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# ระบุตำแหน่งที่เก็บโพสต์
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# ตรวจสอบว่ามีชื่อเว็บไซต์ต้นทางหรือไม่
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Title: {title} | Source: {source} | Link: {link}')
except Exception as e:
print(f'An error occurred: {e}')เมื่อไหร่ควรใช้
เหมาะที่สุดสำหรับหน้า HTML แบบ static ที่มี JavaScript น้อย เหมาะสำหรับบล็อก ไซต์ข่าว และหน้าสินค้า e-commerce ธรรมดา
ข้อดี
- ●ประมวลผลเร็วที่สุด (ไม่มี overhead ของเบราว์เซอร์)
- ●ใช้ทรัพยากรน้อยที่สุด
- ●ง่ายต่อการทำงานแบบขนานด้วย asyncio
- ●เหมาะมากสำหรับ API และหน้า static
ข้อจำกัด
- ●ไม่สามารถรัน JavaScript ได้
- ●ล้มเหลวใน SPA และเนื้อหาไดนามิก
- ●อาจมีปัญหากับระบบ anti-bot ที่ซับซ้อน
วิธีสเครปข้อมูล Web Designer News ด้วยโค้ด
Python + Requests
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# ส่งคำขอไปยังหน้าหลัก
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# ระบุตำแหน่งที่เก็บโพสต์
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# ตรวจสอบว่ามีชื่อเว็บไซต์ต้นทางหรือไม่
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Title: {title} | Source: {source} | Link: {link}')
except Exception as e:
print(f'An error occurred: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_wdn():
with sync_playwright() as p:
# เริ่มต้น headless browser
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://webdesignernews.com/')
# รอให้องค์ประกอบโพสต์โหลด
page.wait_for_selector('.single-post')
posts = page.query_selector_all('.single-post')
for post in posts:
title_el = post.query_selector('h3 a')
if title_el:
title = title_el.inner_text()
link = title_el.get_attribute('href')
print(f'Scraped: {title} - {link}')
browser.close()
scrape_wdn()Python + Scrapy
import scrapy
class WdnSpider(scrapy.Spider):
name = 'wdn_spider'
start_urls = ['https://webdesignernews.com/']
def parse(self, response):
# ดึงข้อมูลแต่ละโพสต์ในฟีด
for post in response.css('.single-post'):
yield {
'title': post.css('h3 a::text').get(),
'source': post.css('.site_name::text').get(),
'link': post.css('h3 a::attr(href)').get()
}
# จัดการการเปลี่ยนหน้าโดยค้นหาลิงก์ 'Next'
next_page = response.css('a.next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://webdesignernews.com/', { waitUntil: 'domcontentloaded' });
// ประเมินหน้าเว็บเพื่อดึงฟิลด์ข้อมูล
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.single-post'));
return items.map(item => ({
title: item.querySelector('h3 a') ? item.querySelector('h3 a').innerText : null,
source: item.querySelector('.site_name') ? item.querySelector('.site_name').innerText : null,
link: item.querySelector('h3 a') ? item.querySelector('h3 a').href : null
}));
});
console.log(results);
await browser.close();
})();คุณสามารถทำอะไรกับข้อมูล Web Designer News
สำรวจการใช้งานจริงและข้อมูลเชิงลึกจากข้อมูล Web Designer News
ฟีดข่าวการออกแบบอัตโนมัติ
สร้างช่องทางข่าวที่คัดสรรมาแบบสดใหม่สำหรับทีมออกแบบมืออาชีพผ่าน Slack หรือ Discord
วิธีการนำไปใช้:
- 1ขูดเรื่องราวที่ได้รับความนิยมสูงสุดทุกๆ 4 ชั่วโมง
- 2กรองผลลัพธ์ตามแท็กหมวดหมู่ที่เกี่ยวข้อง เช่น 'UX' หรือ 'Web Dev'
- 3ส่งหัวข้อและบทสรุปที่ดึงออกมาไปยัง messaging webhook
- 4จัดเก็บข้อมูลเพื่อติดตามความนิยมของเครื่องมือในอุตสาหกรรมในระยะยาว
ใช้ Automatio เพื่อดึงข้อมูลจาก Web Designer News และสร้างแอปพลิเคชันเหล่านี้โดยไม่ต้องเขียนโค้ด
คุณสามารถทำอะไรกับข้อมูล Web Designer News
- ฟีดข่าวการออกแบบอัตโนมัติ
สร้างช่องทางข่าวที่คัดสรรมาแบบสดใหม่สำหรับทีมออกแบบมืออาชีพผ่าน Slack หรือ Discord
- ขูดเรื่องราวที่ได้รับความนิยมสูงสุดทุกๆ 4 ชั่วโมง
- กรองผลลัพธ์ตามแท็กหมวดหมู่ที่เกี่ยวข้อง เช่น 'UX' หรือ 'Web Dev'
- ส่งหัวข้อและบทสรุปที่ดึงออกมาไปยัง messaging webhook
- จัดเก็บข้อมูลเพื่อติดตามความนิยมของเครื่องมือในอุตสาหกรรมในระยะยาว
- ตัวติดตามเทรนด์เครื่องมือออกแบบ
ระบุว่าซอฟต์แวร์หรือไลบรารีการออกแบบใดที่กำลังได้รับความสนใจจากชุมชนมากที่สุด
- ดึงหัวข้อข่าวและบทคัดย่อจากพื้นที่จัดเก็บหมวดหมู่ 'Resources'
- ทำการวิเคราะห์ความถี่ของคำสำคัญเฉพาะ (เช่น 'Figma', 'React')
- เปรียบเทียบการเติบโตของการกล่าวถึงแบบเดือนต่อเดือนเพื่อระบุแนวโน้มใหม่
- ส่งออกรายงานภาพสำหรับทีมการตลาดหรือทีมกลยุทธ์ผลิตภัณฑ์
- การตรวจสอบ Backlink ของคู่แข่ง
ระบุว่าบล็อกหรือเอเจนซี่ใดที่ประสบความสำเร็จในการวางเนื้อหาบนศูนย์กลางข่าวสารหลัก
- ขูดข้อมูลฟิลด์ 'Source Website Name' สำหรับรายการประวัติทั้งหมด
- รวบรวมจำนวนการถูกกล่าวถึงต่อโดเมนภายนอกเพื่อดูว่าใครได้รับเลือกบ่อยที่สุด
- วิเคราะห์ประเภทของเนื้อหาที่ได้รับการยอมรับเพื่อการเข้าถึง (outreach) ที่ดียิ่งขึ้น
- ระบุพันธมิตรที่มีศักยภาพในการร่วมงานในแวดวงการออกแบบ
- ชุดข้อมูลสำหรับเทรน Machine Learning
ใช้ข้อมูลสรุปและข้อความที่คัดสรรมาเพื่อฝึกฝน model การสรุปเนื้อหาทางเทคนิค
- ขูดหัวข้อเรื่องมากกว่า 10,000 รายการพร้อมบทสรุปย่อที่เกี่ยวข้อง
- ทำความสะอาดข้อมูลข้อความเพื่อลบพารามิเตอร์การติดตามภายในและ HTML
- ใช้หัวข้อข่าวเป็นเป้าหมาย (target) และบทสรุปเป็นข้อมูลนำเข้า (input) สำหรับการ fine-tuning
- ทดสอบประสิทธิภาพของ model กับบทความการออกแบบใหม่ๆ ที่ยังไม่อยู่ในขอบเขตข้อมูลเดิม
เพิ่มพลังให้เวิร์กโฟลว์ของคุณด้วย ระบบอัตโนมัติ AI
Automatio รวมพลังของ AI agents การอัตโนมัติเว็บ และการผสานรวมอัจฉริยะเพื่อช่วยให้คุณทำงานได้มากขึ้นในเวลาน้อยลง
เคล็ดลับมืออาชีพสำหรับการ Scrape Web Designer News
คำแนะนำจากผู้เชี่ยวชาญสำหรับการดึงข้อมูลจาก Web Designer News อย่างประสบความสำเร็จ
เล็งเป้าหมายไปที่ WordPress REST API endpoint (/wp-json/wp/v2/posts) เพื่อข้อมูลที่มีโครงสร้างซึ่งทำงานได้เร็วกว่าและเชื่อถือได้มากกว่าการใช้ HTML parsing
ตรวจสอบ RSS feed ของเว็บไซต์ที่ webdesignernews.com/feed/ เพื่อจับเรื่องราวใหม่ๆ ทันทีที่ถูกเผยแพร่
ตั้งกำหนดการงานขูดข้อมูลของคุณไว้ที่เวลา 9
00 AM EST เพื่อให้ตรงกับช่วงเวลาที่มีเนื้อหาจากชุมชนส่งเข้ามาสูงสุดในแต่ละวัน
สลับ User-Agent strings และตั้งค่าการหน่วงเวลา 2 วินาทีระหว่างคำขอ เพื่อหลีกเลี่ยงการถูกจำกัดอัตรา (rate limits) จาก Nginx
จัดการลิงก์ภายใน '/go/' เสมอโดยการทำตาม redirects เพื่อดึงข้อมูล URL แหล่งที่มาหลัก (canonical source URL) สุดท้ายออกมา
ทำความสะอาดข้อมูลข้อความย่อ (excerpt) โดยการลบแท็ก HTML และจุดไข่ปลาที่อยู่ท้ายประโยคออก เพื่อผลลัพธ์การวิเคราะห์ข้อมูลที่ดีขึ้น
คำรับรอง
ผู้ใช้ของเราพูดอย่างไร
เข้าร่วมกับผู้ใช้ที่พึงพอใจนับพันที่ได้เปลี่ยนแปลงเวิร์กโฟลว์ของพวกเขา
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
ที่เกี่ยวข้อง Web Scraping




คำถามที่พบบ่อยเกี่ยวกับ Web Designer News
ค้นหาคำตอบสำหรับคำถามทั่วไปเกี่ยวกับ Web Designer News