Sådan scraper du Who.is for domæne- og IP-intelligence
Lær hvordan du scraper Who.is for at udtrække detaljer om domæneejerskab, registreringsdatoer og kontaktoplysninger. Få værdifulde B2B-leads og...
Anti-bot beskyttelse opdaget
- Cloudflare
- Enterprise WAF og bot-håndtering. Bruger JavaScript-udfordringer, CAPTCHAs og adfærdsanalyse. Kræver browserautomatisering med stealth-indstillinger.
- Hastighedsbegrænsning
- Begrænser forespørgsler pr. IP/session over tid. Kan omgås med roterende proxyer, forespørgselsforsinkelser og distribueret scraping.
- IP-blokering
- Blokerer kendte datacenter-IP'er og markerede adresser. Kræver bolig- eller mobilproxyer for effektiv omgåelse.
- Google reCAPTCHA
- Googles CAPTCHA-system. v2 kræver brugerinteraktion, v3 kører lydløst med risikovurdering. Kan løses med CAPTCHA-tjenester.
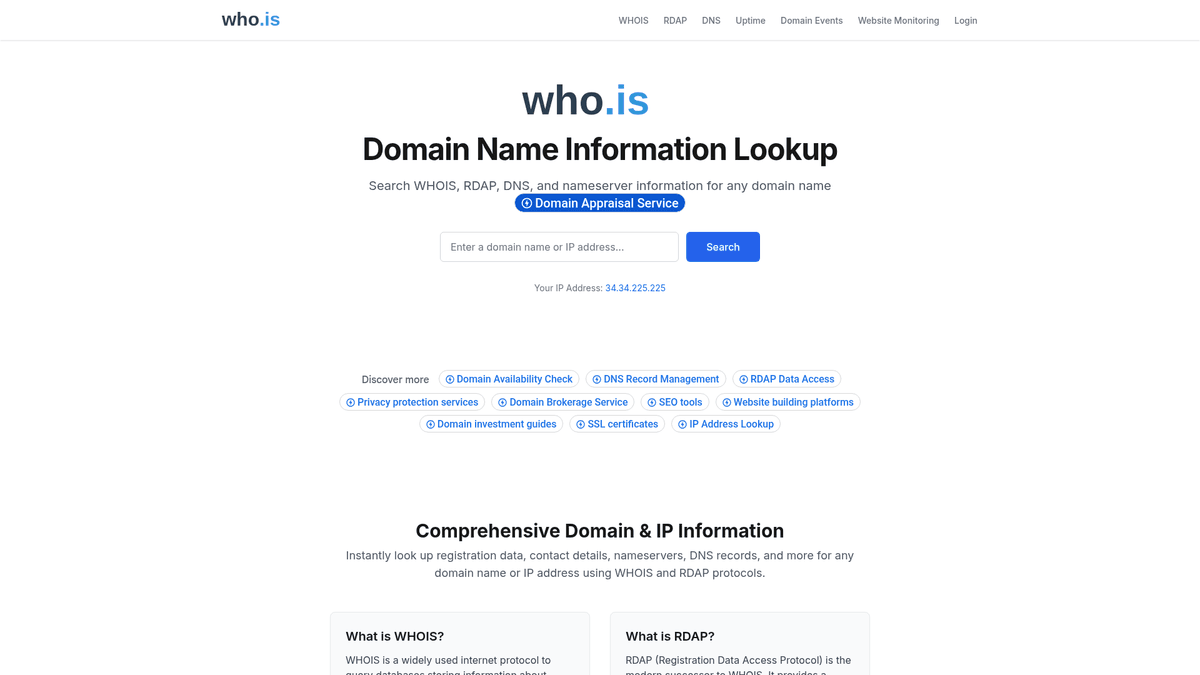
Om Who.is
Opdag hvad Who.is tilbyder og hvilke værdifulde data der kan udtrækkes.
Omfattende tjeneste til domæneopslag
Who.is er et førende webbaseret værktøj til udførelse af WHOIS- og RDAP-opslag for at hente offentlig registreringsinformation for domænenavne og IP-adresser. Det fungerer som et centralt knudepunkt for adgang til optegnelser vedligeholdt af domæneregistratorer og registre verden over og tilbyder kritisk indsigt i registreringsdatoer, udløbstidslinjer og konfigurationer af navneservere. Platformen anvendes i vid udstrækning af IT-professionelle og forskere til at undersøge netværksinfrastruktur og identificere enhederne bag internetressourcer.
Rigt datarepository
Hjemmesiden viser strukturerede og ustrukturerede data vedrørende administrative, tekniske og registrant-kontakter tilknyttet et domæne. Selvom mange personlige kontaktoplysninger nu er skjulte for at overholde GDPR og andre privatlivsprotokoller, leverer siden stadig vigtige oplysninger såsom registratornavn, domænestatus og forskellige DNS-records. Den tilbyder også værktøjer til sporing af IP-adresser og overvågning af hjemmesiders oppetid, hvilket gør den til en omfattende ressource for web-intelligence.
Forretningsværdi af WHOIS-scraping
Scraping af Who.is-data er yderst værdifuldt for cybersikkerhedsforskere, analytikere inden for konkurrence-intelligence og marketingfolk. Det gør det muligt at identificere nystiftede virksomheder, spore bevægelser i domæneporteføljer og undersøge infrastruktur brugt af potentielle trusselsaktører. Ved at automatisere udtrækket af disse data kan organisationer være på forkant med markedstendenser, beskytte deres brand-aktiver og generere højkvalitets B2B-leads effektivt.
Hvorfor Skrabe Who.is?
Opdag forretningsværdien og brugsscenarier for dataudtrækning fra Who.is.
B2B leadgenerering ved at identificere ejere af nystiftede domæner
Cybersikkerheds-trusselsintelligence og kortlægning af domæneinfrastruktur
Overvågning af domæneudløbsdatoer for opkøbsmuligheder
Håndhævelse af intellektuel ejendomsret og identifikation af varemærkekrænkere
Markedsundersøgelser og sporing af domæneregistreringstendenser i specifikke sektorer
Skrabningsudfordringer
Tekniske udfordringer du kan støde på når du skraber Who.is.
Aggressiv Cloudflare bot-beskyttelse og browser-udfordringer
Strenge rate limits på antallet af opslag tilladt per IP-adresse
Omfattende dataskjulning på grund af GDPR og WHOIS-privatlivstjenester
Dynamisk indlæsning af indhold for visse opslagsresultater, der kræver rendering
Komplekse krav til parsing af ustrukturerede rå WHOIS-tekstblokke
Skrab Who.is med AI
Ingen kode nødvendig. Udtræk data på minutter med AI-drevet automatisering.
Sådan fungerer det
Beskriv hvad du har brug for
Fortæl AI'en hvilke data du vil udtrække fra Who.is. Skriv det bare på almindeligt sprog — ingen kode eller selektorer nødvendige.
AI udtrækker dataene
Vores kunstige intelligens navigerer Who.is, håndterer dynamisk indhold og udtrækker præcis det du bad om.
Få dine data
Modtag rene, strukturerede data klar til eksport som CSV, JSON eller send direkte til dine apps og workflows.
Hvorfor bruge AI til skrabning
AI gør det nemt at skrabe Who.is uden at skrive kode. Vores AI-drevne platform bruger kunstig intelligens til at forstå hvilke data du ønsker — beskriv det på almindeligt sprog, og AI udtrækker dem automatisk.
How to scrape with AI:
- Beskriv hvad du har brug for: Fortæl AI'en hvilke data du vil udtrække fra Who.is. Skriv det bare på almindeligt sprog — ingen kode eller selektorer nødvendige.
- AI udtrækker dataene: Vores kunstige intelligens navigerer Who.is, håndterer dynamisk indhold og udtrækker præcis det du bad om.
- Få dine data: Modtag rene, strukturerede data klar til eksport som CSV, JSON eller send direkte til dine apps og workflows.
Why use AI for scraping:
- No-code brugerflade gør det muligt at bygge Who.is-scrapere på få minutter uden scripts
- Håndterer automatisk Cloudflare-udfordringer og forhindringer med JavaScript-rendering
- Cloud-eksekvering undgår fuldstændig lokal IP-blokering og problemer med rate limits
- Indbygget planlægning til løbende overvågning af ændringer i domænestatus
- Sømløs dataeksport til Google Sheets eller CRM-systemer til lead-håndtering
No-code webscrapere til Who.is
Point-and-click alternativer til AI-drevet scraping
Flere no-code værktøjer som Browse.ai, Octoparse, Axiom og ParseHub kan hjælpe dig med at scrape Who.is uden at skrive kode. Disse værktøjer bruger typisk visuelle interfaces til at vælge data, selvom de kan have problemer med komplekst dynamisk indhold eller anti-bot foranstaltninger.
Typisk workflow med no-code værktøjer
Almindelige udfordringer
Indlæringskurve
At forstå selektorer og ekstraktionslogik tager tid
Selektorer går i stykker
Webstedsændringer kan ødelægge hele din arbejdsgang
Problemer med dynamisk indhold
JavaScript-tunge sider kræver komplekse løsninger
CAPTCHA-begrænsninger
De fleste værktøjer kræver manuel indgriben for CAPTCHAs
IP-blokering
Aggressiv scraping kan føre til blokering af din IP
No-code webscrapere til Who.is
Flere no-code værktøjer som Browse.ai, Octoparse, Axiom og ParseHub kan hjælpe dig med at scrape Who.is uden at skrive kode. Disse værktøjer bruger typisk visuelle interfaces til at vælge data, selvom de kan have problemer med komplekst dynamisk indhold eller anti-bot foranstaltninger.
Typisk workflow med no-code værktøjer
- Installer browserudvidelse eller tilmeld dig platformen
- Naviger til målwebstedet og åbn værktøjet
- Vælg dataelementer med point-and-click
- Konfigurer CSS-selektorer for hvert datafelt
- Opsæt pagineringsregler til at scrape flere sider
- Håndter CAPTCHAs (kræver ofte manuel løsning)
- Konfigurer planlægning for automatiske kørsler
- Eksporter data til CSV, JSON eller forbind via API
Almindelige udfordringer
- Indlæringskurve: At forstå selektorer og ekstraktionslogik tager tid
- Selektorer går i stykker: Webstedsændringer kan ødelægge hele din arbejdsgang
- Problemer med dynamisk indhold: JavaScript-tunge sider kræver komplekse løsninger
- CAPTCHA-begrænsninger: De fleste værktøjer kræver manuel indgriben for CAPTCHAs
- IP-blokering: Aggressiv scraping kan føre til blokering af din IP
Kodeeksempler
import requests
from bs4 import BeautifulSoup
# Who.is bruger Cloudflare, så overskrifter (headers) af høj kvalitet er kritiske
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9'
}
url = 'https://who.is/whois/example.com'
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# WHOIS-data er typisk inde i pre-tags eller specifikke div-klasser
whois_block = soup.find('pre')
if whois_block:
print(f'WHOIS Data: {whois_block.get_text().strip()}')
else:
print('Datablok ikke fundet eller blokeret af anti-bot.')
except requests.exceptions.RequestException as e:
print(f'Anmodning fejlede: {e}')Hvornår skal det bruges
Bedst til statiske HTML-sider med minimal JavaScript. Ideel til blogs, nyhedssider og simple e-handelsprodukt sider.
Fordele
- ●Hurtigste udførelse (ingen browser overhead)
- ●Laveste ressourceforbrug
- ●Let at parallelisere med asyncio
- ●Fremragende til API'er og statiske sider
Begrænsninger
- ●Kan ikke køre JavaScript
- ●Fejler på SPA'er og dynamisk indhold
- ●Kan have problemer med komplekse anti-bot systemer
Sådan scraper du Who.is med kode
Python + Requests
import requests
from bs4 import BeautifulSoup
# Who.is bruger Cloudflare, så overskrifter (headers) af høj kvalitet er kritiske
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9'
}
url = 'https://who.is/whois/example.com'
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# WHOIS-data er typisk inde i pre-tags eller specifikke div-klasser
whois_block = soup.find('pre')
if whois_block:
print(f'WHOIS Data: {whois_block.get_text().strip()}')
else:
print('Datablok ikke fundet eller blokeret af anti-bot.')
except requests.exceptions.RequestException as e:
print(f'Anmodning fejlede: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_whois(domain):
with sync_playwright() as p:
# Headless mode bør bruges med stealth-plugins hvis muligt
browser = p.chromium.launch(headless=True)
context = browser.new_context(user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/110.0.0.0 Safari/537.36')
page = context.new_page()
# Naviger til opslagssiden
page.goto(f'https://who.is/whois/{domain}')
# Vent på at resultat-containeren renderes
page.wait_for_selector('.query-results', timeout=10000)
# Ekstraher den indre tekst fra resultaterne
results = page.inner_text('.query-results')
print(f'Resultater for {domain}:
{results}')
browser.close()
scrape_whois('google.com')Python + Scrapy
import scrapy
class WhoisSpider(scrapy.Spider):
name = 'whois_spider'
def start_requests(self):
# Domæner der skal slås op
domains = ['example.com', 'test.org']
for domain in domains:
yield scrapy.Request(
url=f'https://who.is/whois/{domain}',
callback=self.parse,
meta={'proxy': 'http://your-residential-proxy:port'}
)
def parse(self, response):
# Ekstraherer domænenavn og den rå WHOIS-tekst
yield {
'domain': response.css('h1::text').get(),
'raw_data': response.css('.query-results pre::text').get(),
'registrar': response.xpath("//div[contains(text(), 'Registrar')]/following-sibling::div/text()").get()
}Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Indstil en realistisk user agent
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36');
await page.goto('https://who.is/whois/example.com');
// Vent på den præformaterede tekstblok, der indeholder WHOIS-data
try {
await page.waitForSelector('pre', { timeout: 5000 });
const whoisData = await page.evaluate(() => {
const pre = document.querySelector('pre');
return pre ? pre.innerText : 'Data ikke fundet';
});
console.log(whoisData);
} catch (err) {
console.log('Timeout eller blokering detekteret:', err.message);
}
await browser.close();
})();Hvad Du Kan Gøre Med Who.is-Data
Udforsk praktiske anvendelser og indsigter fra Who.is-data.
B2B Opsøgende Salg
Salgsteams kan identificere beslutningstagere bag nystiftede domæner for at tilbyde tjenester som webdesign eller hosting.
Sådan implementeres:
- 1Overvåg daglige lister over nye domæneregistreringer.
- 2Ekstraher registrantnavne og organisationsoplysninger fra Who.is.
- 3Filtrer leads efter brancherelaterede nøgleord fundet i domænenavnene.
- 4Importer kontakter med høj købshensigt til en automatiseret e-mail-marketingplatform.
Brug Automatio til at udtrække data fra Who.is og bygge disse applikationer uden at skrive kode.
Hvad Du Kan Gøre Med Who.is-Data
- B2B Opsøgende Salg
Salgsteams kan identificere beslutningstagere bag nystiftede domæner for at tilbyde tjenester som webdesign eller hosting.
- Overvåg daglige lister over nye domæneregistreringer.
- Ekstraher registrantnavne og organisationsoplysninger fra Who.is.
- Filtrer leads efter brancherelaterede nøgleord fundet i domænenavnene.
- Importer kontakter med høj købshensigt til en automatiseret e-mail-marketingplatform.
- Kortlægning af Cybersikkerhedstrusler
Sikkerhedsanalytikere bruger WHOIS-data til at kortlægge infrastruktur brugt af ondsindede aktører eller phishing-kampagner.
- Indtast et kendt ondsindet domæne i scraperen.
- Ekstraher tilknyttede navneservere og registrant-organisations-ID'er.
- Søg efter andre domæner, der deler de samme infrastruktur-identifikatorer.
- Bloker de identificerede netværksområder i virksomhedens firewalls.
- Overvågning af Domæneopkøb
Investorer kan spore domæner, de ønsker at købe, ved at overvåge deres udløbsdatoer og statusændringer.
- Saml en liste over måldomæner af høj værdi til opkøb.
- Planlæg daglige scrapes for at tjekke 'Expires'-dato og 'Domain Status'.
- Opsæt automatiske advarsler for domæner, der går ind i 'Redemption Period'.
- Afgiv professionelle backorders, så snart domænet frigives til markedet.
- Brandbeskyttelsesanalyse
Virksomheder kan overvåge for typosquatting eller svindelhjemmesider, der bruger deres varemærker for at beskytte kunderne.
- Udfør automatiserede søgninger efter variationer og almindelige stavefejl af brand-navnet.
- Ekstraher registrant- og registratorinfo for eventuelle mistænkelige matchende domæner.
- Analyser navneservere for at bestemme hosting-udbyderen af den svindleri-mistænkte side.
- Indsend juridiske anmodninger om nedtagning (takedown) til de identificerede registratorer og hostingfirmaer.
Supercharg din arbejdsgang med AI-automatisering
Automatio kombinerer kraften fra AI-agenter, webautomatisering og smarte integrationer for at hjælpe dig med at udrette mere på kortere tid.
Professionelle Tips til Skrabning af Who.is
Ekspertråd til succesfuld dataudtrækning fra Who.is.
Roter bolig-proxies (residential proxies) af høj kvalitet for at omgå Cloudflares IP-baserede blokering og rate limits.
Brug en headless browser som Playwright eller Puppeteer til at håndtere den dynamiske rendering af resultater og JS-udfordringer.
Indfør tilfældige venteintervaller (jitter) mellem opslag for at simulere naturlig menneskelig adfærd.
Brug regulære udtryk (regex) til at parse de rå tekstblokke til struktureret JSON-data for bedre anvendelighed.
Overvåg feltet 'Expires' specifikt for at udløse advarsler for værdifulde domæner, der går ind i indløsningsfasen (redemption phase).
Tjek RDAP-sektionen, hvis WHOIS er skjult (redacted), da den undertiden giver mere strukturerede forbindelsesdata.
Anmeldelser
Hvad vores brugere siger
Slut dig til tusindvis af tilfredse brugere, der har transformeret deres arbejdsgang
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relateret Web Scraping

How to Scrape The AA (theaa.com): A Technical Guide for Car & Insurance Data

How to Scrape CSS Author: A Comprehensive Web Scraping Guide

How to Scrape Bilregistret.ai: Swedish Vehicle Data Extraction Guide

How to Scrape Biluppgifter.se: Vehicle Data Extraction Guide

How to Scrape Car.info | Vehicle Data & Valuation Extraction Guide

How to Scrape GoAbroad Study Abroad Programs

How to Scrape ResearchGate: Publication and Researcher Data

How to Scrape Statista: The Ultimate Guide to Market Data Extraction
Ofte stillede spørgsmål om Who.is
Find svar på almindelige spørgsmål om Who.is