Wie man Thrillophilia Tour-Pakete & Bewertungen scrapt
Erfahren Sie, wie Sie Thrillophilia scrapen, um Preise für Tour-Pakete, Reiseverläufe und Kundenbewertungen zu extrahieren. Hochwertige Reisedaten für...
Anti-Bot-Schutz erkannt
- Cloudflare
- Enterprise-WAF und Bot-Management. Nutzt JavaScript-Challenges, CAPTCHAs und Verhaltensanalyse. Erfordert Browser-Automatisierung mit Stealth-Einstellungen.
- Rate Limiting
- Begrenzt Anfragen pro IP/Sitzung über Zeit. Kann mit rotierenden Proxys, Anfrageverzögerungen und verteiltem Scraping umgangen werden.
- IP-Blockierung
- Blockiert bekannte Rechenzentrums-IPs und markierte Adressen. Erfordert Residential- oder Mobile-Proxys zur effektiven Umgehung.
- Browser-Fingerprinting
- Identifiziert Bots anhand von Browser-Eigenschaften: Canvas, WebGL, Schriftarten, Plugins. Erfordert Spoofing oder echte Browser-Profile.
Über Thrillophilia
Entdecken Sie, was Thrillophilia bietet und welche wertvollen Daten extrahiert werden können.
Die führende Plattform für Reiseerlebnisse
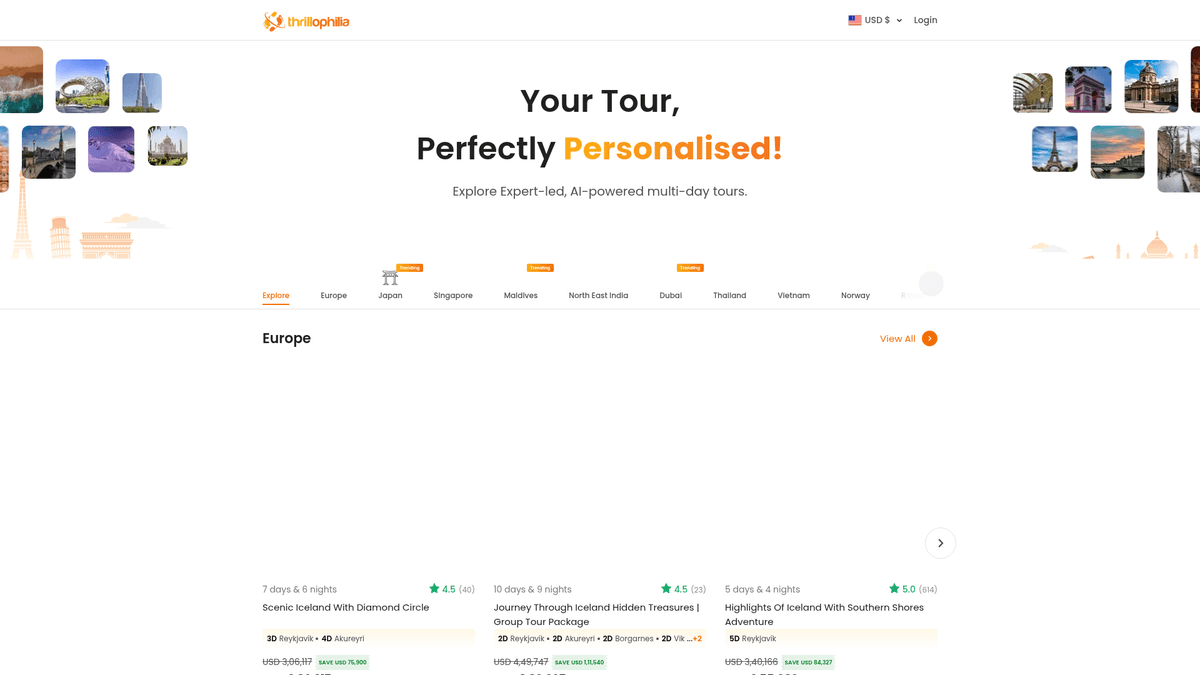
Thrillophilia ist eine bedeutende Reise- und Abenteuerplattform mit Sitz in Indien, die von Experten geführte End-to-End-Reisepakete weltweit anbietet. Sie ist spezialisiert auf kuratierte Reiseerlebnisse, die von Himalaya-Expeditionen und Kulturerbe-Touren in Rajasthan bis hin zu internationalen Reisen nach Europa, Südostasien und in den Nahen Osten reichen.
Datenreichtum und Nutzen
Die Plattform bietet detaillierte Angebote für mehrtägige Touren, Hochzeitsreisepakete und Gruppenabenteuer. Die Einträge auf Thrillophilia enthalten eine Fülle an strukturierten Daten, einschließlich spezifischer Reiseverläufe, Details zu Übernachtungen, rabattierten Preisen, Nutzerbewertungen und beschreibenden Rezensionen. Diese Informationen sind für Reisebüros und Marktforscher von hohem Wert.
Warum es für die Datenanalyse wichtig ist
Für Unternehmen im Reisesektor bietet das Scraping von Thrillophilia einen Wettbewerbsvorteil. Durch die Überwachung von Preisschwankungen und der Kundenzufriedenheit anhand von Bewertungen können Unternehmen ihre eigenen Angebote optimieren und aufkommende Reisetrends identifizieren, bevor sie zum Mainstream werden.
Warum Thrillophilia Scrapen?
Entdecken Sie den Geschäftswert und die Anwendungsfälle für die Datenextraktion von Thrillophilia.
Echtzeit-Preisanalysen
Überwachen Sie dynamische Preisschwankungen und saisonale Rabatte auf Thrillophilia, um sicherzustellen, dass Ihre eigenen Reiseangebote auf dem Markt wettbewerbsfähig bleiben.
Benchmarking von Reiseverläufen
Extrahieren Sie detaillierte Tagespläne und Inklusivleistungen, um zu analysieren, wie führende Reiseveranstalter ihre Erlebnisse strukturieren, und nutzen Sie diese Daten zur Optimierung Ihrer eigenen Produkte.
Sentiment- und Bewertungsanalyse
Sammeln Sie tausende Nutzerbewertungen, um Sentiment-Analysen durchzuführen und häufige Schwachstellen für Reisende sowie beliebte Attraktionen über verschiedene Zielgruppen hinweg zu identifizieren.
Identifizierung von Markttrends
Verfolgen Sie die Häufigkeit neuer Angebote und das Bewertungsvolumen für bestimmte Reiseziele, um aufstrebende Reise-Hotspots zu identifizieren, bevor sie zum Mainstream werden.
Tracking der Anbieter-Performance
Identifizieren und prüfen Sie lokale Dienstleister und Reiseveranstalter, die in den Angeboten erwähnt werden, um eine Datenbank mit hochwertigen potenziellen Geschäftspartnern aufzubauen.
Scraping-Herausforderungen
Technische Herausforderungen beim Scrapen von Thrillophilia.
Cloudflare Bot-Management
Thrillophilia setzt aggressive Cloudflare-Schutzmaßnahmen ein, die standardmäßige automatisierte Anfragen durch Browser-Fingerprinting und IP-Reputationsprüfungen erkennen und blockieren können.
Dynamisches Content-Rendering
Die Website ist mit Next.js erstellt, was bedeutet, dass entscheidende Daten wie Preise und Reiseverläufe oft nach dem initialen Laden der Seite via JavaScript injiziert werden, was einen Headless Browser erfordert.
Interaktive Pagination
Anstelle von traditionellen nummerierten Seiten verwenden viele Listen-Bereiche einen „Load More Products“-Button, der eine aktive Browser-Interaktion erfordert, um den vollständigen Tour-Katalog anzuzeigen.
Extraktion verschachtelter Daten
Reiseverläufe sind oft in komplexen, verschachtelten HTML-Strukturen gespeichert (Tag 1, Tag 2 usw.), was es schwierig macht, ohne fortgeschrittene Selektoren ein sauberes Daten-Mapping aufrechtzuerhalten.
Scrape Thrillophilia mit KI
Kein Code erforderlich. Extrahiere Daten in Minuten mit KI-gestützter Automatisierung.
So funktioniert's
Beschreibe, was du brauchst
Sag der KI, welche Daten du von Thrillophilia extrahieren möchtest. Tippe es einfach in natürlicher Sprache ein — kein Code oder Selektoren nötig.
KI extrahiert die Daten
Unsere künstliche Intelligenz navigiert Thrillophilia, verarbeitet dynamische Inhalte und extrahiert genau das, was du angefordert hast.
Erhalte deine Daten
Erhalte saubere, strukturierte Daten, bereit zum Export als CSV, JSON oder zum direkten Senden an deine Apps und Workflows.
Warum KI zum Scraping nutzen
KI macht es einfach, Thrillophilia zu scrapen, ohne Code zu schreiben. Unsere KI-gestützte Plattform nutzt künstliche Intelligenz, um zu verstehen, welche Daten du möchtest — beschreibe es einfach in natürlicher Sprache und die KI extrahiert sie automatisch.
How to scrape with AI:
- Beschreibe, was du brauchst: Sag der KI, welche Daten du von Thrillophilia extrahieren möchtest. Tippe es einfach in natürlicher Sprache ein — kein Code oder Selektoren nötig.
- KI extrahiert die Daten: Unsere künstliche Intelligenz navigiert Thrillophilia, verarbeitet dynamische Inhalte und extrahiert genau das, was du angefordert hast.
- Erhalte deine Daten: Erhalte saubere, strukturierte Daten, bereit zum Export als CSV, JSON oder zum direkten Senden an deine Apps und Workflows.
Why use AI for scraping:
- Automatisierter Anti-Bot-Bypass: Automatio bewältigt komplexe Herausforderungen wie Cloudflare und Browser-Fingerprinting automatisch und stellt sicher, dass Ihre Scraper ohne ständige manuelle Eingriffe laufen.
- Visuelles Pagination-Handling: Konfigurieren Sie das Tool einfach so, dass es visuell auf „Mehr laden“-Buttons klickt oder durch verschachtelte Links navigiert, wodurch komplexe Looping-Skripte überflüssig werden.
- JavaScript-fähige Extraktion: Da Automatio wie ein echter Browser agiert, wartet es, bis Next.js-Komponenten vollständig geladen sind, und erfasst jedes Mal präzise die endgültigen Preise und Details zum Reiseverlauf.
- Strukturierter Datenexport: Transformieren Sie komplexe Tour-Details automatisch in saubere, strukturierte CSV- oder JSON-Formate, die sofort für Ihre internen Datenbanken oder LLM-Modelle bereitstehen.
No-Code Web Scraper für Thrillophilia
Point-and-Click-Alternativen zum KI-gestützten Scraping
Verschiedene No-Code-Tools wie Browse.ai, Octoparse, Axiom und ParseHub können Ihnen beim Scrapen von Thrillophilia helfen. Diese Tools verwenden visuelle Oberflächen zur Elementauswahl, haben aber Kompromisse im Vergleich zu KI-gestützten Lösungen.
Typischer Workflow mit No-Code-Tools
Häufige Herausforderungen
Lernkurve
Das Verständnis von Selektoren und Extraktionslogik braucht Zeit
Selektoren brechen
Website-Änderungen können den gesamten Workflow zerstören
Probleme mit dynamischen Inhalten
JavaScript-lastige Seiten erfordern komplexe Workarounds
CAPTCHA-Einschränkungen
Die meisten Tools erfordern manuelle Eingriffe bei CAPTCHAs
IP-Sperrung
Aggressives Scraping kann zur Sperrung Ihrer IP führen
No-Code Web Scraper für Thrillophilia
Verschiedene No-Code-Tools wie Browse.ai, Octoparse, Axiom und ParseHub können Ihnen beim Scrapen von Thrillophilia helfen. Diese Tools verwenden visuelle Oberflächen zur Elementauswahl, haben aber Kompromisse im Vergleich zu KI-gestützten Lösungen.
Typischer Workflow mit No-Code-Tools
- Browser-Erweiterung installieren oder auf der Plattform registrieren
- Zur Zielwebseite navigieren und das Tool öffnen
- Per Point-and-Click die zu extrahierenden Datenelemente auswählen
- CSS-Selektoren für jedes Datenfeld konfigurieren
- Paginierungsregeln zum Scrapen mehrerer Seiten einrichten
- CAPTCHAs lösen (erfordert oft manuelle Eingabe)
- Zeitplanung für automatische Ausführungen konfigurieren
- Daten als CSV, JSON exportieren oder per API verbinden
Häufige Herausforderungen
- Lernkurve: Das Verständnis von Selektoren und Extraktionslogik braucht Zeit
- Selektoren brechen: Website-Änderungen können den gesamten Workflow zerstören
- Probleme mit dynamischen Inhalten: JavaScript-lastige Seiten erfordern komplexe Workarounds
- CAPTCHA-Einschränkungen: Die meisten Tools erfordern manuelle Eingriffe bei CAPTCHAs
- IP-Sperrung: Aggressives Scraping kann zur Sperrung Ihrer IP führen
Code-Beispiele
import requests
from bs4 import BeautifulSoup
# Thrillophilia nutzt Cloudflare, daher können Standard-Requests ohne Header oder Session-Management fehlschlagen
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Selektoren variieren je nach spezifischer Zielseite
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Tour: {title} | Preis: {price}')
except Exception as e:
print(f'Fehler aufgetreten: {e}')
scrape_thrill(url)Wann verwenden
Am besten für statische HTML-Seiten, bei denen Inhalte serverseitig geladen werden. Der schnellste und einfachste Ansatz, wenn kein JavaScript-Rendering erforderlich ist.
Vorteile
- ●Schnellste Ausführung (kein Browser-Overhead)
- ●Geringster Ressourcenverbrauch
- ●Einfach zu parallelisieren mit asyncio
- ●Ideal für APIs und statische Seiten
Einschränkungen
- ●Kann kein JavaScript ausführen
- ●Scheitert bei SPAs und dynamischen Inhalten
- ●Kann bei komplexen Anti-Bot-Systemen Probleme haben
Wie man Thrillophilia mit Code scrapt
Python + Requests
import requests
from bs4 import BeautifulSoup
# Thrillophilia nutzt Cloudflare, daher können Standard-Requests ohne Header oder Session-Management fehlschlagen
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://www.thrillophilia.com/destinations/bali/tours'
def scrape_thrill(url):
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Selektoren variieren je nach spezifischer Zielseite
tours = soup.select('.tour-card')
for tour in tours:
title = tour.find('h3').text.strip()
price = tour.select_one('.price-value').text.strip() if tour.select_one('.price-value') else 'N/A'
print(f'Tour: {title} | Preis: {price}')
except Exception as e:
print(f'Fehler aufgetreten: {e}')
scrape_thrill(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
# Das Starten mit einem echten Browser-Profil hilft, einfache Erkennungen zu umgehen
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://www.thrillophilia.com/destinations/egypt/tours', wait_until='networkidle')
# Warten, bis Tour-Karten dynamisch geladen werden
page.wait_for_selector('.tour-card')
tours = page.query_selector_all('.tour-card')
for tour in tours:
title = tour.query_selector('h3').inner_text()
print(f'Extrahiert: {title}')
browser.close()
run()Python + Scrapy
import scrapy
class ThrillSpider(scrapy.Spider):
name = 'thrillophilia'
start_urls = ['https://www.thrillophilia.com/destinations/japan/tours']
def parse(self, response):
for tour in response.css('.tour-card'):
yield {
'title': tour.css('h3::text').get(),
'price': tour.css('.current-price::text').get(),
'rating': tour.css('.rating-value::text').get()
}
# Pagination handhaben
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.thrillophilia.com/destinations/maldives');
// Skript im Browser-Kontext ausführen, um Daten zu extrahieren
const tours = await page.evaluate(() => {
const items = document.querySelectorAll('.tour-card');
return Array.from(items).map(item => ({
title: item.querySelector('h3')?.innerText,
price: item.querySelector('.price')?.innerText
}));
});
console.log(tours);
await browser.close();
})();Was Sie mit Thrillophilia-Daten machen können
Entdecken Sie praktische Anwendungen und Erkenntnisse aus Thrillophilia-Daten.
Dynamische Preisüberwachung
Überwachen Sie Aktivitätspreise täglich, um wettbewerbsfähige Preisstrategien anzupassen.
So implementieren Sie es:
- 1Tägliches Scraping der Tourpreise für Top-Destinationen
- 2Speichern historischer Daten in einer SQL-Datenbank
- 3Einrichten von Alerts für Preisabfälle von über 15 %
- 4Synchronisierung mit internem CRM zur Aktualisierung der eigenen Preisgestaltung
Verwenden Sie Automatio, um Daten von Thrillophilia zu extrahieren und diese Anwendungen ohne Code zu erstellen.
Was Sie mit Thrillophilia-Daten machen können
- Dynamische Preisüberwachung
Überwachen Sie Aktivitätspreise täglich, um wettbewerbsfähige Preisstrategien anzupassen.
- Tägliches Scraping der Tourpreise für Top-Destinationen
- Speichern historischer Daten in einer SQL-Datenbank
- Einrichten von Alerts für Preisabfälle von über 15 %
- Synchronisierung mit internem CRM zur Aktualisierung der eigenen Preisgestaltung
- Sentiment-Analyse von Bewertungen
Analysieren Sie Tausende von Bewertungen, um die Schwachstellen von Reisenden zu verstehen.
- Extrahieren aller Bewertungstexte und Ratings
- Anwenden von NLP-Modellen zur Kategorisierung des Sentiments
- Identifizieren spezifischer Keywords zu den Themen 'Sicherheit' oder 'Verzögerungen'
- Erstellen von Berichten zur Serviceverbesserung
- Erkennung von Reisetrends
Nutzen Sie Reisedaten, um neue Tour-Pakete zu entwerfen, die den Markttrends entsprechen.
- Scraping der detaillierten Tagesabläufe meistverkaufter Touren
- Identifizieren gängiger Hotel- und Aktivitätsmuster
- Vergleich der Popularität von Reisezielen über verschiedene Regionen hinweg
- Entwurf neuer Produkte basierend auf leistungsstarken Itinerary-Strukturen
- Lead-Generierung für Reiseausrüstung
Identifizieren Sie beliebte Aktivitäten, um den Verkauf von Ausrüstung an spezifische Zielgruppen zu richten.
- Verfolgen der am häufigsten gebuchten Abenteuerarten (z. B. Trekking vs. Luxus)
- Korrelieren der Aktivitätspopularität mit saisonalen Trends
- Gezielte Marketingkampagnen für Ausrüstung basierend auf Aktivitäts-Tags der Destination
- Verifizierung von Touranbietern
Überwachen Sie, welche Anbieter auf der Plattform konsistent hoch bewertet werden.
- Extrahieren von Anbieternamen und deren durchschnittlichen Bewertungsergebnissen
- Verfolgen des Volumens der von jedem Anbieter durchgeführten Touren
- Überprüfen potenzieller Partner für Ihr eigenes Reisebüro-Netzwerk
Optimieren Sie Ihren Workflow mit KI-Automatisierung
Automatio kombiniert die Kraft von KI-Agenten, Web-Automatisierung und intelligenten Integrationen, um Ihnen zu helfen, mehr in weniger Zeit zu erreichen.
Profi-Tipps für das Scrapen von Thrillophilia
Expertentipps für die erfolgreiche Datenextraktion von Thrillophilia.
Residential Proxies priorisieren
Um nicht von den Sicherheitssystemen von Thrillophilia markiert zu werden, sollten Sie hochwertige Residential Proxies verwenden, die echten Nutzer-Traffic imitieren, anstatt Datacenter-IPs zu nutzen.
Das NEXT_DATA Skript extrahieren
Suchen Sie im Quellcode der Seite nach einem Script-Tag, das __NEXT_DATA__ enthält. Dieses enthält oft ein vollständiges JSON-Objekt der Seitendaten, das viel schneller zu parsen ist.
Zufällige Verzögerungen implementieren
Richten Sie zufällige Wartezeiten zwischen den Interaktionen ein, um menschliche Browsing-Muster zu imitieren und die Wahrscheinlichkeit zu verringern, dass Rate Limits oder Sicherheitsabfragen ausgelöst werden.
Umgang mit Lazy-Loaded Bildern
Viele Bilder laden erst, wenn sie im Viewport erscheinen. Stellen Sie sicher, dass Ihr Scraper durch die Seite scrollt, um alle Tour-Foto-URLs korrekt zu erfassen.
Währung und Preise normalisieren
Preise können sich je nach Standort Ihres Proxys ändern. Extrahieren Sie immer den Währungscode zusammen mit dem numerischen Wert, um Dateninkonsistenzen zu vermeiden.
Erfahrungsberichte
Was Unsere Nutzer Sagen
Schliessen Sie sich Tausenden zufriedener Nutzer an, die ihren Workflow transformiert haben
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Verwandte Web Scraping
Häufig gestellte Fragen zu Thrillophilia
Finden Sie Antworten auf häufige Fragen zu Thrillophilia