
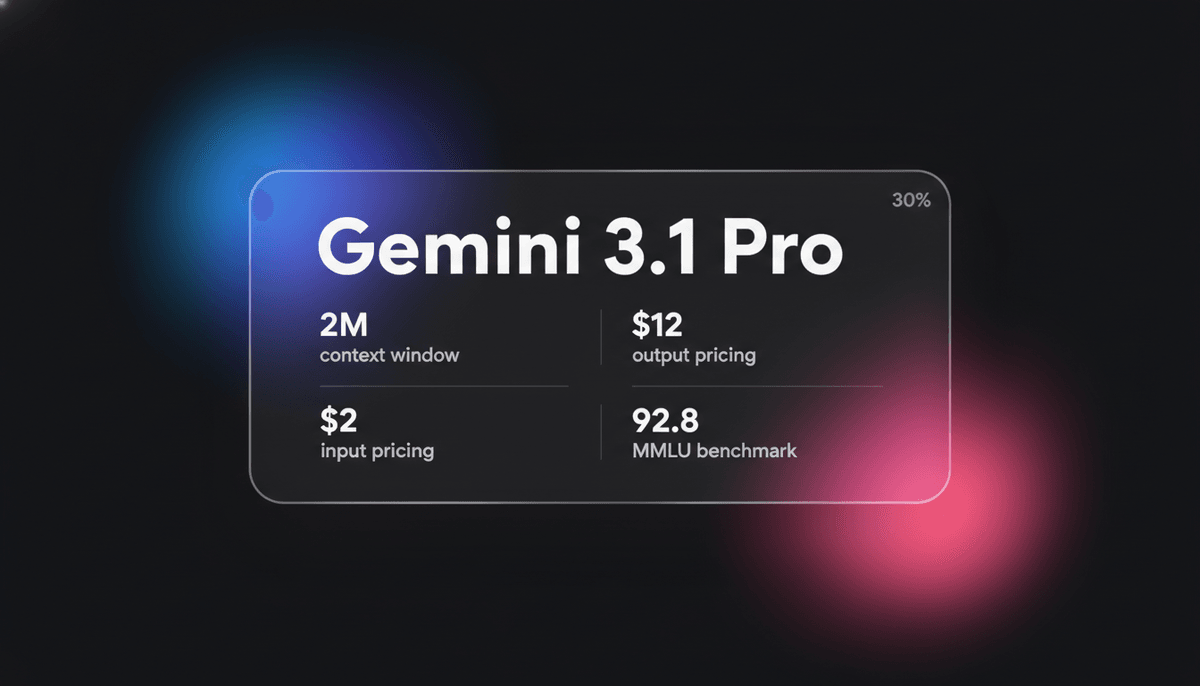
Gemini 3.1 Pro
Gemini 3.1 Pro ist Googles Elite-Modell mit multimodaler Verarbeitung, DeepThink reasoning-Engine, 1M+ context window und branchenführenden ARC-AGI-Logikwerten.
Über Gemini 3.1 Pro
Erfahren Sie mehr über die Fähigkeiten, Funktionen und Einsatzmöglichkeiten von Gemini 3.1 Pro.
Gemini 3.1 Pro repräsentiert eine ausgereifte Umsetzung des Sparse Mixture-of-Experts (MoE) Frameworks, nativ gepaart mit einer fortschrittlichen multimodalen Processing-Engine. Das herausragende Merkmal der Architektur ist die Demokratisierung der DeepThink System 2-Ebene, die es dem model ermöglicht, intern abzuwägen, bevor es sich für einen Output-token entscheidet. Dieses model führt ein einzigartiges dreistufiges Denksystem (Low, Medium, High) ein, das es Entwicklern erlaubt, den Kompromiss zwischen latency, Kosten und reasoning-Tiefe explizit zu steuern.
Mit einem massiven 1-Million-token context window ist Gemini 3.1 Pro für komplexe Workflows in den Bereichen Finanzen, Datenanalyse und dateiübergreifende Code-Migrationen optimiert. Es demonstriert die emergente Fähigkeit, neuartige Logikmuster zu lösen und erzielt dabei beispiellose 77,1 % im ARC-AGI-2 benchmark. Dies macht es zur bevorzugten Wahl für Entwickler, die sowohl multimodale Interaktionen mit geringer latency als auch eine kognitive Höchstleistung für autonome agentic-Aufgaben benötigen.
Anwendungsfälle für Gemini 3.1 Pro
Entdecken Sie die verschiedenen Möglichkeiten, Gemini 3.1 Pro für großartige Ergebnisse zu nutzen.
Code-Analyse für ganze Repositories
Nutzung des 1M context window zum Einlesen kompletter Software-Repositories für Refactoring und Dependency-Mapping.
Autonome Agenten-Committees
Steuerung mehrstufiger agentic-Workflows, bei denen interne Sub-Agenten Lösungen diskutieren und verifizieren, bevor sie ausgeführt werden.
Synthese wissenschaftlicher Forschung
Analyse tausender Forschungsarbeiten und komplexer Datensätze zur Gewinnung strukturierter Informationen und faktischer Erkenntnisse.
Multimodale Content-Erstellung
Gleichzeitige Verarbeitung von Text, Bildern und Audio zur Erstellung komplexer Lehrmaterialien und interaktiver Medien.
Terminal-basierte Automatisierung
Ausführung komplexer Bash-Befehle und Manipulation von Dateisystemen mit hoher Präzision durch fortschrittliche reasoning-Modi.
Unternehmens-Datenaudits
Analyse unstrukturierter Finanzdaten und Rechtsdokumente zur Identifizierung von Compliance-Lücken mit nahezu perfektem faktischem Abruf.
Stärken
Einschränkungen
API-Schnellstart
google/gemini-3.1-pro-preview
import { GoogleGenAI } from "@google/genai";
const genAI = new GoogleGenAI(process.env.GOOGLE_API_KEY);
const model = genAI.getGenerativeModel({
model: "gemini-3.1-pro-preview",
thinkingConfig: { tier: "high" }
});
const prompt = "Analysiere diese gesamte Codebasis auf Sicherheitslücken.";
const result = await model.generateContent(prompt);
console.log(result.response.text());Installieren Sie das SDK und beginnen Sie in wenigen Minuten mit API-Aufrufen.
Was die Leute über Gemini 3.1 Pro sagen
Sehen Sie, was die Community über Gemini 3.1 Pro denkt
“Der 77,1 %-Wert von Gemini 3.1 Pro stellt die bedeutendste Marktverschiebung dar; er verdoppelt den bisherigen Höchstwert bei ARC-AGI.”
“Die Coding-Benchmarks lügen nicht. Dieses model fand einen Bug in meinem Repo, den 3.5 und GPT-4o komplett übersehen haben.”
“Der Shitstorm um Gemini 3.1 ist wirklich interessant. Es hat die Benchmarks vernichtet, aber echte Nutzer sagen, der Ton und die Stimmung seien inkonsistent.”
“Die DeepThink-Engine kann zu erheblichen Verzögerungen führen, manchmal über 90 Sekunden, wenn Aufgaben tiefe Logik erfordern.”
“Context caching ist hier das Killer-Feature. Ich betreibe einen kompletten Dokumentations-Bot für ein paar Cents im Vergleich zu GPT-4o.”
“Gemini hat bei einer komplexen Planungsaufgabe überhaupt nicht über Python gesprochen... einige Logikschritte waren im endgültigen Plan einfach nicht vorhanden.”
Videos über Gemini 3.1 Pro
Schauen Sie Tutorials, Rezensionen und Diskussionen über Gemini 3.1 Pro
“Gemini 3.1 Pro generiert die bisher detaillierteste Version dieser Pagode”
“Gemini hat bei weitem das breiteste window von einer Million tokens”
“Die multimodale Wiedergabetreue bei der Audioverarbeitung ist spürbar besser als bei 3.0”
“Der token-Durchsatz bleibt stabil, selbst wenn sich das context window füllt”
“Der Langzeitabruf ist über die gesamte Million tokens hinweg im Grunde perfekt”
“Bei Rätseln, die nicht in den Trainingsdaten enthalten sein sollten, übertrifft die Gemini 3-Serie alle anderen Modelle”
“3.1 Pro könnte die Laufzeit eines fine-tuning-Skripts tatsächlich von 300 Sekunden auf 47 Sekunden reduzieren”
“DeepThink-Logikschritte sind im Trace deutlich sichtbar und zeigen echte Überlegung”
“Wir erreichen eine Benchmark-Sättigung, bei der nur ARC-AGI wirklich für den Fortschritt zählt”
“Die AGI-Trajektorie beschleunigt sich aufgrund dieser abstrakten reasoning-Sprünge”
“Ich denke, dass 3.1 sich wirklich wie ein Fortschritt anfühlt, auch wenn er nur sehr gering ist”
“Es scheint Gemini 3.0 Pro zu übertreffen, wenn wir genau dieselben prompts nebeneinander testen”
“Die Coding-Genauigkeit bei komplexen Python-Refactors ist die höchste, die ich je gesehen habe”
“Die API-Zuverlässigkeit hat sich im letzten Monat des Testens deutlich verbessert”
“Die reale Performance entspricht endlich dem Hype der Benchmark-Ergebnisse”
Optimieren Sie Ihren Workflow mit KI-Automatisierung
Automatio kombiniert die Kraft von KI-Agenten, Web-Automatisierung und intelligenten Integrationen, um Ihnen zu helfen, mehr in weniger Zeit zu erreichen.
Pro-Tipps für Gemini 3.1 Pro
Expertentipps, um das Beste aus Gemini 3.1 Pro herauszuholen.
Auswahl der Reasoning-Stufe
Nutzen Sie den High-Modus für komplexe Mathematik oder Logik, wechseln Sie aber für Standardformatierungen zu Low, um compute zu sparen.
Context Caching
Implementieren Sie context caching für statische Dokumentationen, um die Input-Preise um bis zu 90 % pro Million tokens zu senken.
Strukturierte Artefakte
Nutzen Sie die Fähigkeit des models, strukturierte Aufgabenlisten zu erstellen, um die menschliche Überwachung bei agentic-Durchläufen zu erleichtern.
Multimodal Prompting
Kombinieren Sie Video- und Audio-Inputs, um dem model den vollständigen Kontext von realen Szenarien anstelle von reinen Textbeschreibungen zu geben.
Erfahrungsberichte
Was Unsere Nutzer Sagen
Schliessen Sie sich Tausenden zufriedener Nutzer an, die ihren Workflow transformiert haben
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Verwandte AI Models
Claude Opus 4.7
Anthropic
Claude Opus 4.7 is Anthropic's flagship model with a 1-million-token context, adaptive reasoning, and 3.3x vision resolution for enterprise-scale agents.
Gemini 3.1 Flash Live Preview
Gemini 3.1 Flash Live Preview is Google's ultra-low-latency, audio-to-audio model featuring a 131K context window, high-fidelity multimodal reasoning, and...
GPT-5.5
OpenAI
GPT-5.5 is OpenAI's flagship frontier model with a 1M context window and five reasoning effort levels, optimized for autonomous agentic workflows and coding.
Grok-3
xAI
Grok-3 is xAI's flagship reasoning model, featuring deep logic deduction, a 128k context window, and real-time integration with X for live research and coding.
Kimi K3
Moonshot
Kimi K3 is Moonshot AI's 2.8T MoE model with a 1M token context window, native multimodal vision, and frontier-tier coding performance for complex agents.
GPT-5.2 Pro
OpenAI
GPT-5.2 Pro is OpenAI's 2025 flagship reasoning model featuring Extended Thinking for SOTA performance in mathematics, coding, and expert knowledge work.
Qwen 3.7 Max
alibaba
Qwen 3.7 Max is Alibaba’s flagship AI model for deep reasoning and autonomous agent tasks, featuring a 256k context window and top-tier coding performance.
Gemini 3 Pro
Google's Gemini 3 Pro is a multimodal powerhouse featuring a 1M token context window, native video processing, and industry-leading reasoning performance.
Häufig gestellte Fragen zu Gemini 3.1 Pro
Finden Sie Antworten auf häufige Fragen zu Gemini 3.1 Pro