Cómo extraer datos de Open Collective: Guía de datos financieros y de contribuidores
Aprende cómo extraer datos de Open Collective para transacciones financieras, listas de colaboradores y datos de financiación de proyectos. Obtén información...
Protección Anti-Bot Detectada
- Cloudflare
- WAF y gestión de bots de nivel empresarial. Usa desafíos JavaScript, CAPTCHAs y análisis de comportamiento. Requiere automatización de navegador con configuración sigilosa.
- Limitación de velocidad
- Limita solicitudes por IP/sesión en el tiempo. Se puede eludir con proxies rotativos, retrasos en solicitudes y scraping distribuido.
- WAF
Acerca de Open Collective
Descubre qué ofrece Open Collective y qué datos valiosos se pueden extraer.
Acerca de Open Collective
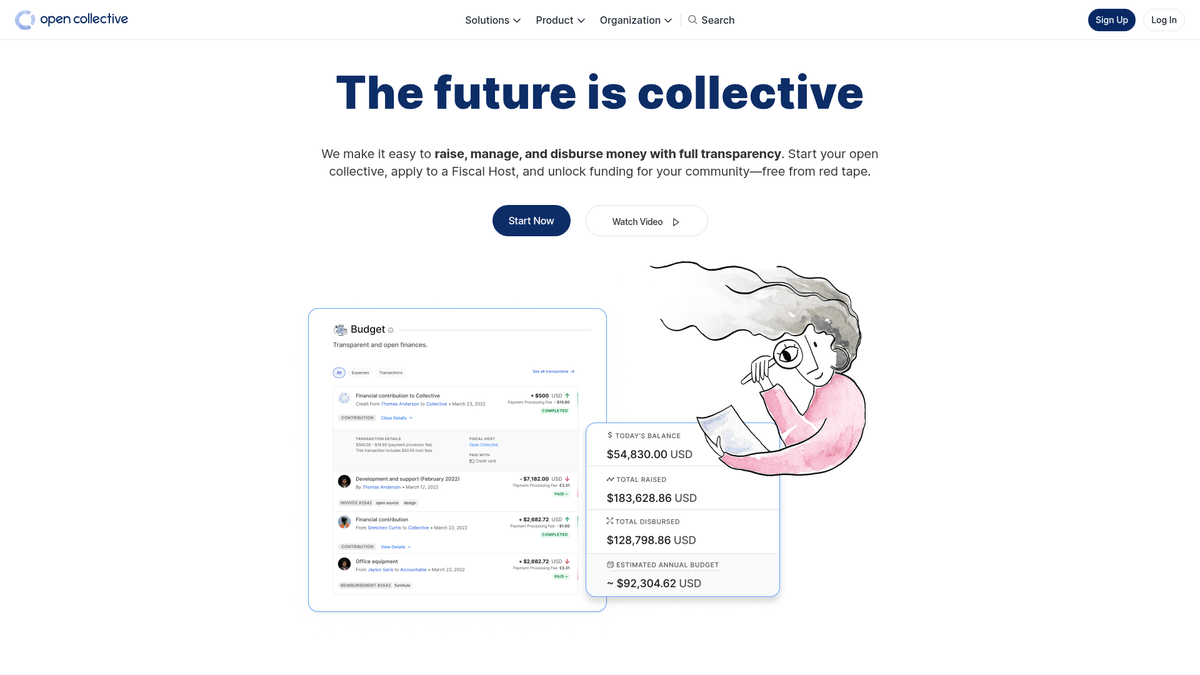
Open Collective es una plataforma financiera y legal única diseñada para brindar transparencia a organizaciones dirigidas por la comunidad, proyectos de software open-source y asociaciones de vecinos. Al actuar como una herramienta de financiación descentralizada, permite que los 'colectivos' recauden dinero y gestionen gastos sin necesidad de una entidad legal formal, utilizando a menudo anfitriones fiscales para el apoyo administrativo. Grandes proyectos tecnológicos como Babel y Webpack confían en esta plataforma para gestionar sus ecosistemas financiados por la comunidad.
La plataforma es reconocida por su transparencia radical. Cada transacción, ya sea una donación de una gran corporación o un pequeño gasto para una reunión comunitaria, se registra y es visible públicamente. Esto proporciona una gran cantidad de datos sobre la salud financiera y los hábitos de gasto de algunas de las dependencias de open-source más críticas del mundo.
Extraer datos de Open Collective es altamente valioso para las organizaciones que buscan realizar investigaciones de mercado sobre la economía del open-source. Permite a los usuarios identificar oportunidades de patrocinio corporativo, rastrear tendencias de financiación de desarrolladores y auditar la sostenibilidad financiera de proyectos de software críticos. Los datos sirven como una ventana directa al flujo de capital dentro de la comunidad global de desarrolladores.
¿Por Qué Scrapear Open Collective?
Descubre el valor comercial y los casos de uso para extraer datos de Open Collective.
Analizar la sostenibilidad del open-source
Realiza un seguimiento de la salud financiera y la viabilidad a largo plazo de proyectos de infraestructura tecnológica crítica como Webpack, Babel y Logseq.
Prospección de patrocinios corporativos
Identifica organizaciones que ya patrocinan software open-source para crear una lista dirigida de clientes potenciales para tus propias iniciativas.
Auditorías de transparencia financiera
Monitorea cómo los grupos descentralizados y los colectivos comunitarios asignan sus fondos para garantizar la rendición de cuentas ante donantes y partes interesadas.
Descubrimiento de tendencias de mercado
Evalúa qué categorías, como tecnología, activismo ambiental o educación, están recibiendo el mayor crecimiento en financiación comunitaria.
Investigación de colaboradores e influencers
Descubre a los principales colaboradores individuales y corporativos dentro de nichos específicos para encontrar influencers clave para divulgación o reclutamiento.
Seguimiento del impacto de subvenciones
Agrega datos sobre cómo se desembolsan las grandes subvenciones en múltiples proyectos para medir el impacto real del gasto filantrópico.
Desafíos de Scraping
Desafíos técnicos que puedes encontrar al scrapear Open Collective.
Renderizado con uso intensivo de JavaScript
Open Collective está construida como una aplicación web moderna que requiere la ejecución completa de JavaScript para renderizar los libros contables financieros y las listas de colaboradores.
Arquitectura GraphQL compleja
El sitio obtiene datos a través de consultas GraphQL profundamente anidadas, lo que hace que el análisis de HTML tradicional sea menos eficiente que el monitoreo de las respuestas de la API.
Patrones de carga dinámica
Los historiales de transacciones y las listas de miembros suelen utilizar scroll infinito o botones de 'Cargar más' que requieren automatización basada en eventos para su extracción completa.
Cloudflare y limitación de tasa
La extracción de alta frecuencia puede activar el Web Application Firewall (WAF) de Cloudflare o dar lugar a bloqueos temporales de IP debido a los estrictos límites de tasa globales.
Estructuras de datos anidadas
La información sobre anfitriones fiscales, colectivos y gastos se distribuye en diferentes capas de la página, lo que requiere una navegación compleja de varios pasos.
Scrapea Open Collective con IA
Sin código necesario. Extrae datos en minutos con automatización impulsada por IA.
Cómo Funciona
Describe lo que necesitas
Dile a la IA qué datos quieres extraer de Open Collective. Solo escríbelo en lenguaje natural — sin código ni selectores.
La IA extrae los datos
Nuestra inteligencia artificial navega Open Collective, maneja contenido dinámico y extrae exactamente lo que pediste.
Obtén tus datos
Recibe datos limpios y estructurados listos para exportar como CSV, JSON o enviar directamente a tus aplicaciones.
Por Qué Usar IA para el Scraping
La IA facilita el scraping de Open Collective sin escribir código. Nuestra plataforma impulsada por inteligencia artificial entiende qué datos quieres — solo descríbelo en lenguaje natural y la IA los extrae automáticamente.
How to scrape with AI:
- Describe lo que necesitas: Dile a la IA qué datos quieres extraer de Open Collective. Solo escríbelo en lenguaje natural — sin código ni selectores.
- La IA extrae los datos: Nuestra inteligencia artificial navega Open Collective, maneja contenido dinámico y extrae exactamente lo que pediste.
- Obtén tus datos: Recibe datos limpios y estructurados listos para exportar como CSV, JSON o enviar directamente a tus aplicaciones.
Why use AI for scraping:
- Extracción de datos visual: Extrae registros financieros complejos y tablas de colaboradores mediante una interfaz de apuntar y hacer clic sin tener que escribir ninguna lógica de consulta GraphQL.
- Manejo inteligente de paginación: Gestiona automáticamente el scroll infinito o los botones de 'Cargar más' para asegurar que cada gasto o donación se capture del libro contable.
- Programación de monitoreo automatizado: Configura un bot recurrente para extraer datos cada 24 horas, asegurándote de tener siempre el saldo y los registros de transacciones más actualizados.
- Evadir medidas anti-bot: Utiliza la rotación de IP integrada y las funciones de interacción de tipo humano para evitar ser marcado por Cloudflare mientras extraes datos a escala.
- Exportación directa a JSON/CSV: Transforma instantáneamente datos web brutos en formatos estructurados listos para el análisis en Google Sheets, Excel o bases de datos internas.
Scrapers Sin Código para Open Collective
Alternativas de apuntar y clic al scraping con IA
Varias herramientas sin código como Browse.ai, Octoparse, Axiom y ParseHub pueden ayudarte a scrapear Open Collective. Estas herramientas usan interfaces visuales para seleccionar elementos, pero tienen desventajas comparadas con soluciones con IA.
Flujo de Trabajo Típico con Herramientas Sin Código
Desafíos Comunes
Curva de aprendizaje
Comprender selectores y lógica de extracción lleva tiempo
Los selectores se rompen
Los cambios en el sitio web pueden romper todo el flujo de trabajo
Problemas con contenido dinámico
Los sitios con mucho JavaScript requieren soluciones complejas
Limitaciones de CAPTCHA
La mayoría de herramientas requieren intervención manual para CAPTCHAs
Bloqueo de IP
El scraping agresivo puede resultar en el bloqueo de tu IP
Scrapers Sin Código para Open Collective
Varias herramientas sin código como Browse.ai, Octoparse, Axiom y ParseHub pueden ayudarte a scrapear Open Collective. Estas herramientas usan interfaces visuales para seleccionar elementos, pero tienen desventajas comparadas con soluciones con IA.
Flujo de Trabajo Típico con Herramientas Sin Código
- Instalar extensión del navegador o registrarse en la plataforma
- Navegar al sitio web objetivo y abrir la herramienta
- Seleccionar con point-and-click los elementos de datos a extraer
- Configurar selectores CSS para cada campo de datos
- Configurar reglas de paginación para scrapear múltiples páginas
- Resolver CAPTCHAs (frecuentemente requiere intervención manual)
- Configurar programación para ejecuciones automáticas
- Exportar datos a CSV, JSON o conectar vía API
Desafíos Comunes
- Curva de aprendizaje: Comprender selectores y lógica de extracción lleva tiempo
- Los selectores se rompen: Los cambios en el sitio web pueden romper todo el flujo de trabajo
- Problemas con contenido dinámico: Los sitios con mucho JavaScript requieren soluciones complejas
- Limitaciones de CAPTCHA: La mayoría de herramientas requieren intervención manual para CAPTCHAs
- Bloqueo de IP: El scraping agresivo puede resultar en el bloqueo de tu IP
Ejemplos de Código
import requests
# El endpoint de la GraphQL API de Open Collective
url = 'https://api.opencollective.com/graphql/v2'
# Consulta GraphQL para obtener información básica sobre un colectivo
query = '''
query {
collective(slug: "webpack") {
name
stats {
totalAmountReceived { value }
balance { value }
}
}
}
'''
headers = {'Content-Type': 'application/json'}
try:
# Enviando solicitud POST a la API
response = requests.post(url, json={'query': query}, headers=headers)
response.raise_for_status()
data = response.json()
# Extrayendo e imprimiendo el nombre y el saldo
collective = data['data']['collective']
print(f"Nombre: {collective['name']}")
print(f"Saldo: {collective['stats']['balance']['value']}")
except Exception as e:
print(f"Ocurrió un error: {e}")Cuándo Usar
Mejor para páginas HTML estáticas donde el contenido se carga del lado del servidor. El enfoque más rápido y simple cuando no se requiere renderizado de JavaScript.
Ventajas
- ●Ejecución más rápida (sin sobrecarga del navegador)
- ●Menor consumo de recursos
- ●Fácil de paralelizar con asyncio
- ●Excelente para APIs y páginas estáticas
Limitaciones
- ●No puede ejecutar JavaScript
- ●Falla en SPAs y contenido dinámico
- ●Puede tener dificultades con sistemas anti-bot complejos
Cómo Scrapear Open Collective con Código
Python + Requests
import requests
# El endpoint de la GraphQL API de Open Collective
url = 'https://api.opencollective.com/graphql/v2'
# Consulta GraphQL para obtener información básica sobre un colectivo
query = '''
query {
collective(slug: "webpack") {
name
stats {
totalAmountReceived { value }
balance { value }
}
}
}
'''
headers = {'Content-Type': 'application/json'}
try:
# Enviando solicitud POST a la API
response = requests.post(url, json={'query': query}, headers=headers)
response.raise_for_status()
data = response.json()
# Extrayendo e imprimiendo el nombre y el saldo
collective = data['data']['collective']
print(f"Nombre: {collective['name']}")
print(f"Saldo: {collective['stats']['balance']['value']}")
except Exception as e:
print(f"Ocurrió un error: {e}")Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_opencollective():
with sync_playwright() as p:
# Lanzamiento del navegador con soporte para JS
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://opencollective.com/discover')
# Esperar a que se carguen las tarjetas de colectivos
page.wait_for_selector('.CollectiveCard')
# Extraer datos del DOM
collectives = page.query_selector_all('.CollectiveCard')
for c in collectives:
name = c.query_selector('h2').inner_text()
print(f'Proyecto encontrado: {name}')
browser.close()
scrape_opencollective()Python + Scrapy
import scrapy
import json
class OpenCollectiveSpider(scrapy.Spider):
name = 'opencollective'
start_urls = ['https://opencollective.com/webpack']
def parse(self, response):
# Open Collective utiliza Next.js; los datos suelen estar dentro de una etiqueta script
next_data = response.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
if next_data:
parsed_data = json.loads(next_data)
collective = parsed_data['props']['pageProps']['collective']
yield {
'name': collective.get('name'),
'balance': collective.get('stats', {}).get('balance'),
'currency': collective.get('currency')
}Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://opencollective.com/discover');
// Esperar a que se cargue el contenido dinámico
await page.waitForSelector('.CollectiveCard');
// Mapear los elementos para extraer nombres
const data = await page.evaluate(() => {
return Array.from(document.querySelectorAll('.CollectiveCard')).map(el => ({
name: el.querySelector('h2').innerText
}));
});
console.log(data);
await browser.close();
})();Qué Puedes Hacer Con Los Datos de Open Collective
Explora aplicaciones prácticas e insights de los datos de Open Collective.
Previsión de crecimiento del open-source
Identifica tecnologías de tendencia mediante el seguimiento de las tasas de crecimiento financiero de categorías colectivas específicas.
Cómo implementar:
- 1Extraer los ingresos mensuales de los principales proyectos en etiquetas específicas
- 2Calcular las tasas de crecimiento anual compuesto (CAGR)
- 3Visualizar la salud de la financiación del proyecto para predecir la adopción tecnológica
Usa Automatio para extraer datos de Open Collective y crear estas aplicaciones sin escribir código.
Qué Puedes Hacer Con Los Datos de Open Collective
- Previsión de crecimiento del open-source
Identifica tecnologías de tendencia mediante el seguimiento de las tasas de crecimiento financiero de categorías colectivas específicas.
- Extraer los ingresos mensuales de los principales proyectos en etiquetas específicas
- Calcular las tasas de crecimiento anual compuesto (CAGR)
- Visualizar la salud de la financiación del proyecto para predecir la adopción tecnológica
- Generación de leads para SaaS
Identifica proyectos bien financiados que puedan necesitar herramientas de desarrollo, hosting o servicios profesionales.
- Filtrar colectivos por presupuesto y cantidad total recaudada
- Extraer descripciones de proyectos y URLs de sitios web externos
- Verificar el stack tecnológico a través de los repositorios de GitHub vinculados
- Auditoría de filantropía corporativa
Rastrea dónde están gastando las grandes corporaciones sus presupuestos de contribución al open-source.
- Extraer listas de contribuidores para los principales proyectos
- Filtrar por perfiles organizacionales frente a perfiles individuales
- Agregar los montos de las contribuciones por entidad corporativa
- Investigación de impacto comunitario
Analiza cómo los grupos descentralizados distribuyen sus fondos para comprender el impacto social.
- Extraer el libro de transacciones completo para un colectivo específico
- Categorizar los gastos (viajes, salarios, hardware)
- Generar informes sobre la asignación de recursos dentro de los grupos comunitarios
- Pipeline de reclutamiento de desarrolladores
Encuentra líderes activos en ecosistemas específicos basados en su gestión comunitaria e historial de contribuciones.
- Extraer listas de miembros de colectivos técnicos clave
- Cruzar la información de los contribuidores con sus perfiles sociales públicos
- Identificar mantenedores activos para un acercamiento de alto nivel
Potencia tu flujo de trabajo con Automatizacion IA
Automatio combina el poder de agentes de IA, automatizacion web e integraciones inteligentes para ayudarte a lograr mas en menos tiempo.
Consejos Pro para Scrapear Open Collective
Consejos expertos para extraer datos exitosamente de Open Collective.
Extraer mediante Slugs de URL
La forma más sencilla de dirigirse a colectivos específicos es utilizar sus slugs de URL únicos, que se pueden obtener de la página principal de descubrimiento.
Verificar __NEXT_DATA__
El código fuente de la página a menudo contiene una etiqueta de script con el ID __NEXT_DATA__ que contiene JSON pre-renderizado, lo cual puede ser más rápido que extraer datos de la interfaz de usuario.
Usar selectores 'data-cy'
Dirígete a los atributos 'data-cy' en tus selectores, ya que son IDs de prueba que permanecen estables incluso cuando las clases CSS cambian durante las actualizaciones del sitio.
Monitorear solicitudes XHR
Utiliza las herramientas para desarrolladores del navegador para encontrar las llamadas directas al endpoint de GraphQL, ya que estas proporcionan la estructura de datos más limpia para las transacciones financieras.
Implementar retrasos aleatorios
Añade tiempos de espera aleatorios de entre 2 y 6 segundos para imitar la navegación natural y pasar desapercibido ante la detección automatizada de bots.
Aprovechar la documentación oficial
Revisa la documentación de la API GraphQL de Open Collective para comprender las convenciones de nomenclatura de los diferentes campos de datos financieros.
Testimonios
Lo Que Dicen Nuestros Usuarios
Unete a miles de usuarios satisfechos que han transformado su flujo de trabajo
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relacionados Web Scraping
How to Scrape Moon.ly | Step-by-Step NFT Data Extraction Guide
How to Scrape Yahoo Finance: Extract Stock Market Data
How to Scrape Rocket Mortgage: A Comprehensive Guide
How to Scrape jup.ag: Jupiter DEX Web Scraper Guide
How to Scrape Indiegogo: The Ultimate Crowdfunding Data Extraction Guide
How to Scrape ICO Drops: Comprehensive Crypto Data Guide
How to Scrape Crypto.com: Comprehensive Market Data Guide
How to Scrape Coinpaprika: Crypto Market Data Extraction Guide
Preguntas Frecuentes Sobre Open Collective
Encuentra respuestas a preguntas comunes sobre Open Collective