Cómo hacer scraping de Who.is para inteligencia de dominios e IP
Aprende a realizar scraping en Who.is para extraer detalles de propiedad de dominios, fechas de registro e información de contacto. Obtén leads B2B valiosos e...
Protección Anti-Bot Detectada
- Cloudflare
- WAF y gestión de bots de nivel empresarial. Usa desafíos JavaScript, CAPTCHAs y análisis de comportamiento. Requiere automatización de navegador con configuración sigilosa.
- Limitación de velocidad
- Limita solicitudes por IP/sesión en el tiempo. Se puede eludir con proxies rotativos, retrasos en solicitudes y scraping distribuido.
- Bloqueo de IP
- Bloquea IPs de centros de datos conocidos y direcciones marcadas. Requiere proxies residenciales o móviles para eludir efectivamente.
- Google reCAPTCHA
- Sistema CAPTCHA de Google. v2 requiere interacción del usuario, v3 funciona silenciosamente con puntuación de riesgo. Se puede resolver con servicios de CAPTCHA.
Acerca de Who.is
Descubre qué ofrece Who.is y qué datos valiosos se pueden extraer.
Servicio integral de búsqueda de dominios
Who.is es una herramienta web de primer nivel para realizar consultas WHOIS y RDAP con el fin de recuperar información de registro pública de nombres de dominio y direcciones IP. Funciona como un centro neurálgico para acceder a los registros mantenidos por registradores y registros de dominios en todo el mundo, ofreciendo información crítica sobre fechas de registro, plazos de expiración y configuraciones de servidores de nombres. La plataforma es ampliamente utilizada por profesionales de TI e investigadores para investigar la infraestructura de red e identificar a las entidades detrás de los recursos de internet.
Repositorio de datos enriquecidos
El sitio web muestra datos estructurados y no estructurados relativos a los contactos administrativos, técnicos y del registrante asociados a un dominio. Aunque gran parte de los datos de contacto personales están ahora redactados para cumplir con el GDPR y otros protocolos de privacidad, el sitio sigue proporcionando información esencial como el nombre del registrador, el estado del dominio y varios registros DNS. También ofrece herramientas para rastrear direcciones IP y monitorear el tiempo de actividad de los sitios web, lo que lo convierte en un recurso integral para la inteligencia web.
Valor empresarial del scraping de WHOIS
Extraer datos de Who.is es sumamente valioso para investigadores de ciberseguridad, analistas de inteligencia competitiva y profesionales del marketing. Permite la identificación de empresas recién registradas, el seguimiento de movimientos en carteras de dominios y la investigación de la infraestructura utilizada por posibles actores de amenazas. Al automatizar la extracción de estos datos, las organizaciones pueden adelantarse a las tendencias del mercado, proteger sus activos de marca y generar leads B2B de alta calidad de manera eficiente.
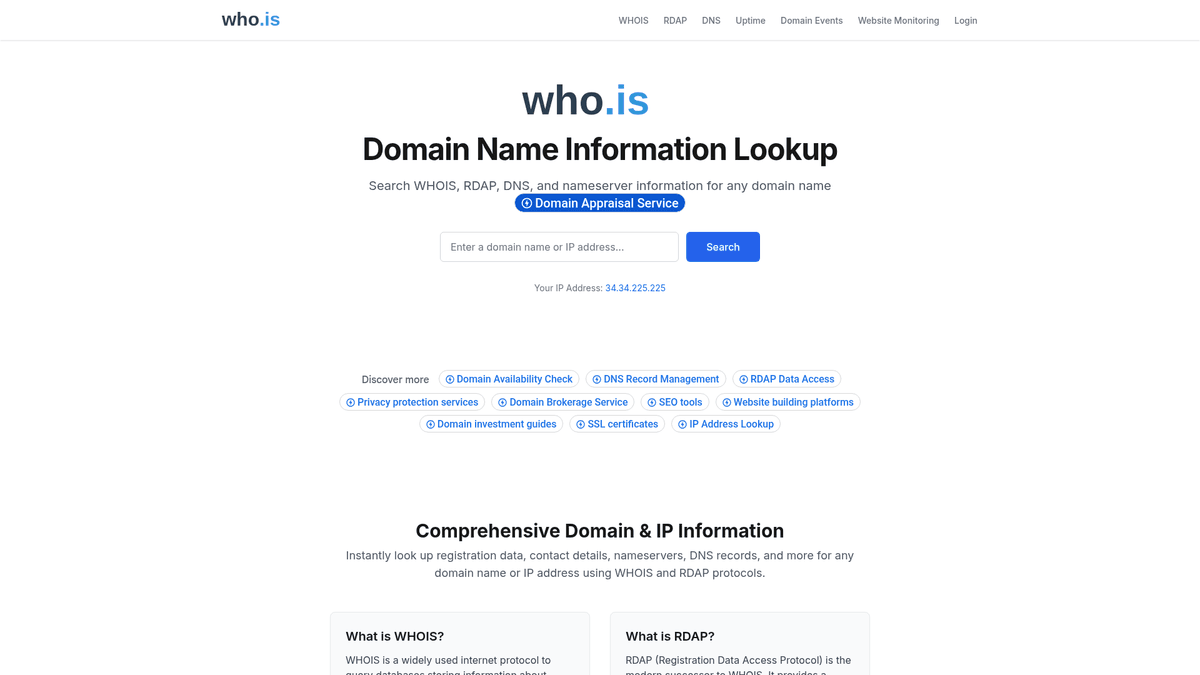
¿Por Qué Scrapear Who.is?
Descubre el valor comercial y los casos de uso para extraer datos de Who.is.
Generación de leads B2B
Identifica a los propietarios de dominios recién registrados para ofrecer servicios especializados como desarrollo web, SEO o branding tan pronto como lancen su proyecto.
Inteligencia de amenazas de ciberseguridad
Mapea la infraestructura de sitios web sospechosos analizando nameservers, organizaciones registrantes y patrones de registro históricos para prevenir ataques de phishing.
Seguimiento de expiración de dominios
Monitorea dominios de alto valor para conocer su estado de expiración y redención, y así realizar backorders competitivos en el momento en que estén disponibles para el registro público.
Protección de marca
Detecta typosquatting e infracciones de marcas registradas realizando scraping en Who.is para obtener detalles de registro de dominios que imitan de cerca tu identidad corporativa.
Investigación de mercado competitiva
Analiza los portafolios de dominios de la competencia para descubrir proyectos ocultos, lanzamientos de nuevos productos o expansiones geográficas basadas en su actividad de registro.
Desafíos de Scraping
Desafíos técnicos que puedes encontrar al scrapear Who.is.
Detección de bots sofisticada
Who.is emplea desafíos de Cloudflare y verificaciones de integridad del navegador que bloquean scripts automatizados estándar y navegadores headless sin las configuraciones de sigilo adecuadas.
Límites de frecuencia estrictos por IP
El sitio impone límites estrictos en el número de consultas permitidas desde una sola dirección IP, lo que resulta en bloqueos temporales inmediatos para scrapers de alta frecuencia.
Ocultación de datos (GDPR)
Las regulaciones de privacidad han limitado significativamente la cantidad de datos personales visibles en los registros WHOIS, obligando a los scrapers a buscar puntos de datos alternativos como los nameservers.
Texto en bruto no estructurado
La mayoría de los datos de dominios se presentan como un bloque de texto en bruto que varía según el registrador, lo que dificulta la extracción de datos limpios sin regex avanzado o lógica de parsing.
Scrapea Who.is con IA
Sin código necesario. Extrae datos en minutos con automatización impulsada por IA.
Cómo Funciona
Describe lo que necesitas
Dile a la IA qué datos quieres extraer de Who.is. Solo escríbelo en lenguaje natural — sin código ni selectores.
La IA extrae los datos
Nuestra inteligencia artificial navega Who.is, maneja contenido dinámico y extrae exactamente lo que pediste.
Obtén tus datos
Recibe datos limpios y estructurados listos para exportar como CSV, JSON o enviar directamente a tus aplicaciones.
Por Qué Usar IA para el Scraping
La IA facilita el scraping de Who.is sin escribir código. Nuestra plataforma impulsada por inteligencia artificial entiende qué datos quieres — solo descríbelo en lenguaje natural y la IA los extrae automáticamente.
How to scrape with AI:
- Describe lo que necesitas: Dile a la IA qué datos quieres extraer de Who.is. Solo escríbelo en lenguaje natural — sin código ni selectores.
- La IA extrae los datos: Nuestra inteligencia artificial navega Who.is, maneja contenido dinámico y extrae exactamente lo que pediste.
- Obtén tus datos: Recibe datos limpios y estructurados listos para exportar como CSV, JSON o enviar directamente a tus aplicaciones.
Why use AI for scraping:
- Evasión de bots fluida: El motor de navegador avanzado de Automatio gestiona de forma natural los desafíos de JavaScript y las mitigaciones de Cloudflare que suelen bloquear los métodos tradicionales de scraping.
- Rotación dinámica de IP: Integra fácilmente redes de proxies residenciales para rotar identidades en cada consulta, asegurando que nunca alcances los estrictos límites de frecuencia impuestos a las consultas de WHOIS.
- Estructuración de datos sin código: Selecciona y normaliza visualmente bloques de texto en bruto en formatos estructurados CSV o JSON sin escribir una sola línea de código complejo de parsing.
- Monitoreo automatizado: Configura tareas programadas para verificar el estado de los dominios en intervalos específicos y recibe notificaciones en el momento en que cambie un registro de registro.
Scrapers Sin Código para Who.is
Alternativas de apuntar y clic al scraping con IA
Varias herramientas sin código como Browse.ai, Octoparse, Axiom y ParseHub pueden ayudarte a scrapear Who.is. Estas herramientas usan interfaces visuales para seleccionar elementos, pero tienen desventajas comparadas con soluciones con IA.
Flujo de Trabajo Típico con Herramientas Sin Código
Desafíos Comunes
Curva de aprendizaje
Comprender selectores y lógica de extracción lleva tiempo
Los selectores se rompen
Los cambios en el sitio web pueden romper todo el flujo de trabajo
Problemas con contenido dinámico
Los sitios con mucho JavaScript requieren soluciones complejas
Limitaciones de CAPTCHA
La mayoría de herramientas requieren intervención manual para CAPTCHAs
Bloqueo de IP
El scraping agresivo puede resultar en el bloqueo de tu IP
Scrapers Sin Código para Who.is
Varias herramientas sin código como Browse.ai, Octoparse, Axiom y ParseHub pueden ayudarte a scrapear Who.is. Estas herramientas usan interfaces visuales para seleccionar elementos, pero tienen desventajas comparadas con soluciones con IA.
Flujo de Trabajo Típico con Herramientas Sin Código
- Instalar extensión del navegador o registrarse en la plataforma
- Navegar al sitio web objetivo y abrir la herramienta
- Seleccionar con point-and-click los elementos de datos a extraer
- Configurar selectores CSS para cada campo de datos
- Configurar reglas de paginación para scrapear múltiples páginas
- Resolver CAPTCHAs (frecuentemente requiere intervención manual)
- Configurar programación para ejecuciones automáticas
- Exportar datos a CSV, JSON o conectar vía API
Desafíos Comunes
- Curva de aprendizaje: Comprender selectores y lógica de extracción lleva tiempo
- Los selectores se rompen: Los cambios en el sitio web pueden romper todo el flujo de trabajo
- Problemas con contenido dinámico: Los sitios con mucho JavaScript requieren soluciones complejas
- Limitaciones de CAPTCHA: La mayoría de herramientas requieren intervención manual para CAPTCHAs
- Bloqueo de IP: El scraping agresivo puede resultar en el bloqueo de tu IP
Ejemplos de Código
import requests
from bs4 import BeautifulSoup
# Who.is utiliza Cloudflare, por lo que los encabezados de alta calidad son críticos
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept-Language': 'es-ES,es;q=0.9'
}
url = 'https://who.is/whois/example.com'
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Los datos de WHOIS suelen estar dentro de etiquetas pre o clases div específicas
whois_block = soup.find('pre')
if whois_block:
print(f'Datos WHOIS: {whois_block.get_text().strip()}')
else:
print('Bloque de datos no encontrado o bloqueado por anti-bot.')
except requests.exceptions.RequestException as e:
print(f'La solicitud falló: {e}')Cuándo Usar
Mejor para páginas HTML estáticas donde el contenido se carga del lado del servidor. El enfoque más rápido y simple cuando no se requiere renderizado de JavaScript.
Ventajas
- ●Ejecución más rápida (sin sobrecarga del navegador)
- ●Menor consumo de recursos
- ●Fácil de paralelizar con asyncio
- ●Excelente para APIs y páginas estáticas
Limitaciones
- ●No puede ejecutar JavaScript
- ●Falla en SPAs y contenido dinámico
- ●Puede tener dificultades con sistemas anti-bot complejos
Cómo Scrapear Who.is con Código
Python + Requests
import requests
from bs4 import BeautifulSoup
# Who.is utiliza Cloudflare, por lo que los encabezados de alta calidad son críticos
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept-Language': 'es-ES,es;q=0.9'
}
url = 'https://who.is/whois/example.com'
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Los datos de WHOIS suelen estar dentro de etiquetas pre o clases div específicas
whois_block = soup.find('pre')
if whois_block:
print(f'Datos WHOIS: {whois_block.get_text().strip()}')
else:
print('Bloque de datos no encontrado o bloqueado por anti-bot.')
except requests.exceptions.RequestException as e:
print(f'La solicitud falló: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_whois(domain):
with sync_playwright() as p:
# El modo headless debe usarse con plugins de sigilo si es posible
browser = p.chromium.launch(headless=True)
context = browser.new_context(user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/110.0.0.0 Safari/537.36')
page = context.new_page()
# Navegar a la página de consulta
page.goto(f'https://who.is/whois/{domain}')
# Esperar a que se renderice el contenedor de resultados
page.wait_for_selector('.query-results', timeout=10000)
# Extraer el texto interno de los resultados
results = page.inner_text('.query-results')
print(f'Resultados para {domain}:
{results}')
browser.close()
scrape_whois('google.com')Python + Scrapy
import scrapy
class WhoisSpider(scrapy.Spider):
name = 'whois_spider'
def start_requests(self):
# Dominios a consultar
domains = ['example.com', 'test.org']
for domain in domains:
yield scrapy.Request(
url=f'https://who.is/whois/{domain}',
callback=self.parse,
meta={'proxy': 'http://tu-proxy-residencial:puerto'}
)
def parse(self, response):
# Extrayendo el nombre del dominio y el texto WHOIS sin formato
yield {
'domain': response.css('h1::text').get(),
'raw_data': response.css('.query-results pre::text').get(),
'registrar': response.xpath("//div[contains(text(), 'Registrar')]/following-sibling::div/text()").get()
}Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Establecer un user agent realista
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36');
await page.goto('https://who.is/whois/example.com');
// Esperar por el bloque principal de texto preformateado que contiene los datos de WHOIS
try {
await page.waitForSelector('pre', { timeout: 5000 });
const whoisData = await page.evaluate(() => {
const pre = document.querySelector('pre');
return pre ? pre.innerText : 'Datos no encontrados';
});
console.log(whoisData);
} catch (err) {
console.log('Tiempo de espera agotado o bloqueo detectado:', err.message);
}
await browser.close();
})();Qué Puedes Hacer Con Los Datos de Who.is
Explora aplicaciones prácticas e insights de los datos de Who.is.
Prospección de ventas B2B
Los equipos de ventas pueden identificar a los responsables de la toma de decisiones detrás de los dominios recién registrados para ofrecer servicios como diseño web o hosting.
Cómo implementar:
- 1Monitorear listas diarias de nuevos registros de dominios.
- 2Extraer nombres de registrantes y detalles de la organización de Who.is.
- 3Filtrar leads por palabras clave relacionadas con la industria encontradas en los nombres de dominio.
- 4Importar contactos de alta intención en una plataforma de email marketing automatizada.
Usa Automatio para extraer datos de Who.is y crear estas aplicaciones sin escribir código.
Qué Puedes Hacer Con Los Datos de Who.is
- Prospección de ventas B2B
Los equipos de ventas pueden identificar a los responsables de la toma de decisiones detrás de los dominios recién registrados para ofrecer servicios como diseño web o hosting.
- Monitorear listas diarias de nuevos registros de dominios.
- Extraer nombres de registrantes y detalles de la organización de Who.is.
- Filtrar leads por palabras clave relacionadas con la industria encontradas en los nombres de dominio.
- Importar contactos de alta intención en una plataforma de email marketing automatizada.
- Mapeo de amenazas de ciberseguridad
Los analistas de seguridad utilizan los datos de WHOIS para mapear la infraestructura utilizada por actores maliciosos o campañas de phishing.
- Ingresar un dominio malicioso conocido en el scraper.
- Extraer los servidores de nombres asociados y los IDs de la organización registrante.
- Buscar otros dominios que compartan estos mismos identificadores de infraestructura.
- Bloquear los rangos de red identificados en los firewalls de seguridad corporativa.
- Monitoreo de adquisición de dominios
Los inversores pueden rastrear los dominios que desean comprar monitoreando sus fechas de expiración y cambios de estado.
- Compilar una lista de dominios objetivo de alto valor para su adquisición.
- Programar scrapings diarios para verificar la fecha de 'Expires' y el 'Domain Status'.
- Configurar alertas automatizadas para dominios que entren en el 'Periodo de redención'.
- Realizar reservas profesionales (backorders) tan pronto como el dominio se libere al mercado.
- Análisis de protección de marca
Las empresas pueden monitorear el typosquatting o sitios web fraudulentos que utilicen sus marcas registradas para proteger a sus clientes.
- Realizar búsquedas automatizadas de variaciones y errores ortográficos comunes del nombre de la marca.
- Extraer información del registrante y del registrador para cualquier dominio sospechoso que coincida.
- Analizar los servidores de nombres para determinar el proveedor de hosting del sitio fraudulento.
- Presentar solicitudes legales de eliminación (takedown) ante los registradores y empresas de hosting identificadas.
Potencia tu flujo de trabajo con Automatizacion IA
Automatio combina el poder de agentes de IA, automatizacion web e integraciones inteligentes para ayudarte a lograr mas en menos tiempo.
Consejos Pro para Scrapear Who.is
Consejos expertos para extraer datos exitosamente de Who.is.
Priorizar proxies residenciales
Utiliza direcciones IP residenciales para imitar a usuarios domésticos reales, ya que los proxies de datacenter suelen ser incluidos en listas negras de inmediato por el firewall anti-bot del sitio.
Implementar retardos aleatorios
Configura un jitter de entre 10 y 20 segundos entre cada consulta para simular patrones de navegación humanos naturales y evitar activar la detección de comportamiento.
Usar regex para parsing en bruto
Dado que la estructura de datos cambia según el registrador, aplicar regex al campo 'Raw WHOIS' es la forma más confiable de extraer direcciones de email y números de teléfono.
Revisar la pestaña RDAP
Comprueba siempre la sección RDAP en Who.is si está disponible, ya que a menudo proporciona datos más estructurados en comparación con el bloque de texto tradicional de WHOIS.
Monitorear códigos de estado
Realiza scraping específicamente del campo 'Domain Status' para identificar si un dominio está en estado 'clientHold' o 'pendingDelete' para fines de inversión.
Testimonios
Lo Que Dicen Nuestros Usuarios
Unete a miles de usuarios satisfechos que han transformado su flujo de trabajo
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relacionados Web Scraping

How to Scrape The AA (theaa.com): A Technical Guide for Car & Insurance Data

How to Scrape CSS Author: A Comprehensive Web Scraping Guide

How to Scrape Bilregistret.ai: Swedish Vehicle Data Extraction Guide

How to Scrape Biluppgifter.se: Vehicle Data Extraction Guide

How to Scrape Car.info | Vehicle Data & Valuation Extraction Guide

How to Scrape GoAbroad Study Abroad Programs

How to Scrape ResearchGate: Publication and Researcher Data

How to Scrape Statista: The Ultimate Guide to Market Data Extraction
Preguntas Frecuentes Sobre Who.is
Encuentra respuestas a preguntas comunes sobre Who.is