How to Scrape BetaList | BetaList Web Scraper Guide
Scopri come fare scraping su BetaList per estrarre lead di startup, dati dei fondatori e trend tecnologici. Impara a superare Cloudflare e i contenuti dinamici...
Protezione Anti-Bot Rilevata
- Cloudflare
- WAF e gestione bot di livello enterprise. Usa sfide JavaScript, CAPTCHA e analisi comportamentale. Richiede automazione del browser con impostazioni stealth.
- Rate Limiting
- Limita le richieste per IP/sessione nel tempo. Può essere aggirato con proxy rotanti, ritardi nelle richieste e scraping distribuito.
- Blocco IP
- Blocca IP di data center noti e indirizzi segnalati. Richiede proxy residenziali o mobili per aggirare efficacemente.
- Fingerprinting del browser
- Identifica i bot tramite caratteristiche del browser: canvas, WebGL, font, plugin. Richiede spoofing o profili browser reali.
Informazioni Su BetaList
Scopri cosa offre BetaList e quali dati preziosi possono essere estratti.
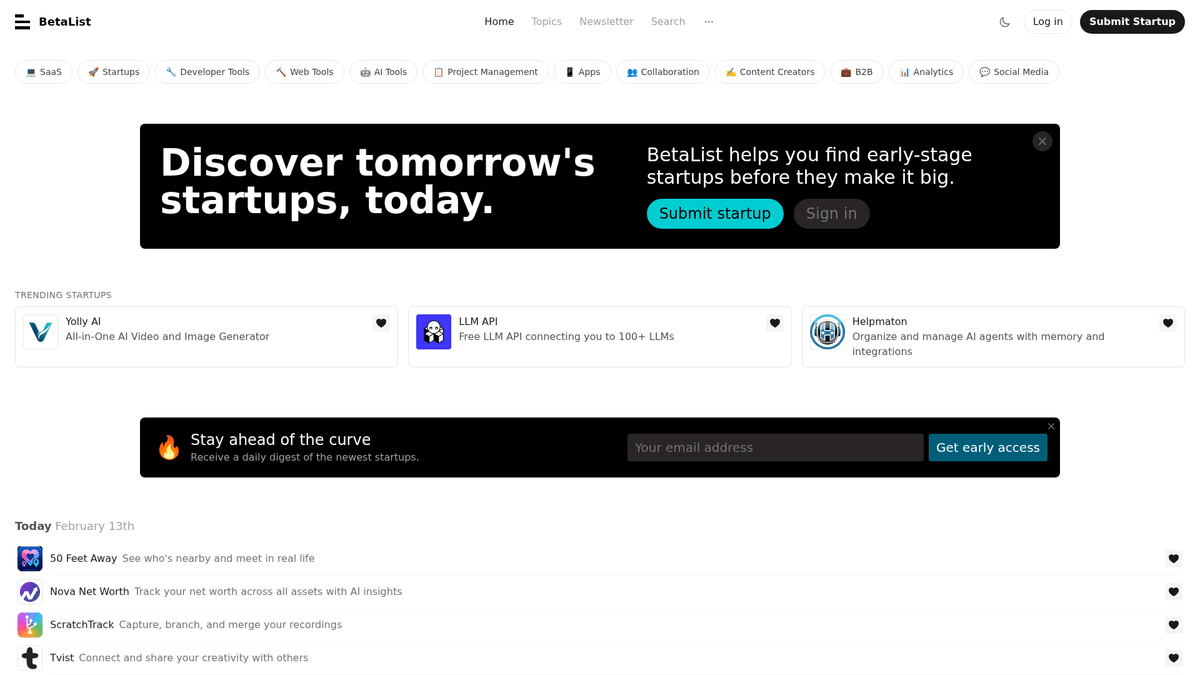
The Premier Startup Discovery Platform
BetaList is a widely recognized discovery platform dedicated to early-stage internet startups. Founded by Marc Köhlbrugge, it serves as a launchpad for founders to connect with early adopters, gather feedback, and build initial traction before entering mainstream markets like Product Hunt or the App Store.
Data-Rich Startup Profiles
The platform provides a vast directory of listings across sectors such as SaaS, Artificial Intelligence, Fintech, and E-commerce. Each listing contains rich metadata, including startup taglines, detailed product descriptions, high-resolution screenshots, founder profiles, and social media links. This data provides a snapshot of the newest innovations in the tech ecosystem.
Strategic Value for Data Scraping
For researchers and businesses, scraping BetaList is essential for identifying emerging trends and sourcing high-quality B2B leads. Investors use the platform to spot high-potential startups in their infancy, while service providers (agencies, developers, and marketers) use it to reach out to founders who are actively seeking growth and support tools.
Perché Fare Scraping di BetaList?
Scopri il valore commerciale e i casi d'uso per l'estrazione dati da BetaList.
Generazione di lead per vendite B2B
BetaList intercetta le startup nella loro fase iniziale, rendendolo una fonte ideale per agenzie e fornitori di servizi per trovare nuove aziende che necessitano di supporto marketing, legale o di sviluppo.
Flusso di deal per Venture Capital
Gli investitori e i VC utilizzano i dati di BetaList per scoprire aziende tecnologiche emergenti prima che acquisiscano popolarità su piattaforme più grandi come Product Hunt o Crunchbase.
Analisi dei trend di mercato
Estraendo i tag delle categorie e le date di invio, i ricercatori possono identificare quali nicchie tecnologiche, come la Generative AI o il Web3, stanno vedendo attualmente la maggiore attività imprenditoriale.
Intelligence competitiva
Le aziende SaaS possono monitorare i nuovi entranti nella loro specifica nicchia di settore per tenere traccia delle funzionalità innovative e del posizionamento di mercato dei potenziali concorrenti.
Networking e outreach con i fondatori
L'estrazione dei nomi dei fondatori e dei loro handle Twitter consente a recruiter e consulenti di contattare direttamente gli imprenditori che stanno attivamente costruendo e lanciando nuovi prodotti.
Sfide dello Scraping
Sfide tecniche che potresti incontrare durante lo scraping di BetaList.
Mitigazione dei bot di Cloudflare
BetaList utilizza Cloudflare per proteggere la sua directory, il che spesso blocca i normali script automatizzati e richiede una gestione sofisticata degli header o strumenti basati su browser.
Caricamento tramite infinite scroll
L'elenco delle startup utilizza il caricamento dinamico tramite infinite scroll, il che significa che i dati non sono presenti nell'HTML iniziale e richiedono uno scraper capace di simulare l'interazione dell'utente ed eseguire JavaScript.
Struttura DOM dinamica
Il sito web utilizza framework frontend moderni in cui gli elementi vengono iniettati dinamicamente, richiedendo allo scraper di attendere la comparsa di selettori specifici prima di tentare l'estrazione dei dati.
Rate limiting aggressivo
L'invio rapido di richieste alle pagine di dettaglio delle startup può innescare ban temporanei dell'IP, rendendo necessario implementare ritardi casuali e una rotazione di proxy di alta qualità.
Scraping di BetaList con l'IA
Nessun codice richiesto. Estrai dati in minuti con l'automazione basata sull'IA.
Come Funziona
Descrivi ciò di cui hai bisogno
Di' all'IA quali dati vuoi estrarre da BetaList. Scrivi semplicemente in linguaggio naturale — nessun codice o selettore necessario.
L'IA estrae i dati
La nostra intelligenza artificiale naviga BetaList, gestisce contenuti dinamici ed estrae esattamente ciò che hai richiesto.
Ottieni i tuoi dati
Ricevi dati puliti e strutturati pronti per l'esportazione in CSV, JSON o da inviare direttamente alle tue applicazioni.
Perché Usare l'IA per lo Scraping
L'IA rende facile lo scraping di BetaList senza scrivere codice. La nostra piattaforma basata sull'intelligenza artificiale capisce quali dati vuoi — descrivili in linguaggio naturale e l'IA li estrae automaticamente.
How to scrape with AI:
- Descrivi ciò di cui hai bisogno: Di' all'IA quali dati vuoi estrarre da BetaList. Scrivi semplicemente in linguaggio naturale — nessun codice o selettore necessario.
- L'IA estrae i dati: La nostra intelligenza artificiale naviga BetaList, gestisce contenuti dinamici ed estrae esattamente ciò che hai richiesto.
- Ottieni i tuoi dati: Ricevi dati puliti e strutturati pronti per l'esportazione in CSV, JSON o da inviare direttamente alle tue applicazioni.
Why use AI for scraping:
- Scraping visuale no-code: Automatio ti consente di costruire uno scraper per BetaList semplicemente cliccando sulle schede delle startup e sui link social, eliminando la necessità di scrivere complesso codice Python o Node.js.
- Gestione anti-bot automatizzata: La piattaforma gestisce automaticamente le impronte digitali del browser (fingerprints) e i proxy per navigare le sfide di Cloudflare che tipicamente bloccano gli scraper scritti a mano.
- Estrazione di lead pianificata: Imposta il tuo scraper per l'esecuzione giornaliera o settimanale per catturare automaticamente le nuove startup inviate e inviarle direttamente al tuo CRM o Google Sheets per un outreach immediato.
- Gestione dell'infinite scroll: Automatio gestisce nativamente l'infinite scroll e le azioni 'Carica altro', assicurandoti di poter estrarre migliaia di annunci storici di startup senza intervento manuale.
Scraper Web No-Code per BetaList
Alternative point-and-click allo scraping alimentato da IA
Diversi strumenti no-code come Browse.ai, Octoparse, Axiom e ParseHub possono aiutarti a fare scraping di BetaList senza scrivere codice. Questi strumenti usano interfacce visive per selezionare i dati, anche se possono avere difficoltà con contenuti dinamici complessi o misure anti-bot.
Workflow Tipico con Strumenti No-Code
Sfide Comuni
Curva di apprendimento
Comprendere selettori e logica di estrazione richiede tempo
I selettori si rompono
Le modifiche al sito web possono rompere l'intero flusso di lavoro
Problemi con contenuti dinamici
I siti con molto JavaScript richiedono soluzioni complesse
Limitazioni CAPTCHA
La maggior parte degli strumenti richiede intervento manuale per i CAPTCHA
Blocco IP
Lo scraping aggressivo può portare al blocco del tuo IP
Scraper Web No-Code per BetaList
Diversi strumenti no-code come Browse.ai, Octoparse, Axiom e ParseHub possono aiutarti a fare scraping di BetaList senza scrivere codice. Questi strumenti usano interfacce visive per selezionare i dati, anche se possono avere difficoltà con contenuti dinamici complessi o misure anti-bot.
Workflow Tipico con Strumenti No-Code
- Installare l'estensione del browser o registrarsi sulla piattaforma
- Navigare verso il sito web target e aprire lo strumento
- Selezionare con point-and-click gli elementi dati da estrarre
- Configurare i selettori CSS per ogni campo dati
- Impostare le regole di paginazione per lo scraping di più pagine
- Gestire i CAPTCHA (spesso richiede risoluzione manuale)
- Configurare la pianificazione per le esecuzioni automatiche
- Esportare i dati in CSV, JSON o collegare tramite API
Sfide Comuni
- Curva di apprendimento: Comprendere selettori e logica di estrazione richiede tempo
- I selettori si rompono: Le modifiche al sito web possono rompere l'intero flusso di lavoro
- Problemi con contenuti dinamici: I siti con molto JavaScript richiedono soluzioni complesse
- Limitazioni CAPTCHA: La maggior parte degli strumenti richiede intervento manuale per i CAPTCHA
- Blocco IP: Lo scraping aggressivo può portare al blocco del tuo IP
Esempi di Codice
import requests
from bs4 import BeautifulSoup
# Note: BetaList uses Cloudflare; requests alone may get a 403 Forbidden.
# You typically need a bypass or to use a session with realistic headers.
url = 'https://betalist.com/topics/saas'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Target the startup card containers
for card in soup.select('.startupCard'):
name = card.select_one('.startupCard__name').get_text(strip=True)
tagline = card.select_one('.startupCard__tagline').get_text(strip=True)
print(f'Scraped: {name} - {tagline}')
except Exception as e:
print(f'Request failed: {e}')Quando Usare
Ideale per pagine HTML statiche con JavaScript minimo. Perfetto per blog, siti di notizie e pagine prodotto e-commerce semplici.
Vantaggi
- ●Esecuzione più veloce (senza overhead del browser)
- ●Consumo risorse minimo
- ●Facile da parallelizzare con asyncio
- ●Ottimo per API e pagine statiche
Limitazioni
- ●Non può eseguire JavaScript
- ●Fallisce su SPA e contenuti dinamici
- ●Può avere difficoltà con sistemi anti-bot complessi
Come Fare Scraping di BetaList con Codice
Python + Requests
import requests
from bs4 import BeautifulSoup
# Note: BetaList uses Cloudflare; requests alone may get a 403 Forbidden.
# You typically need a bypass or to use a session with realistic headers.
url = 'https://betalist.com/topics/saas'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Target the startup card containers
for card in soup.select('.startupCard'):
name = card.select_one('.startupCard__name').get_text(strip=True)
tagline = card.select_one('.startupCard__tagline').get_text(strip=True)
print(f'Scraped: {name} - {tagline}')
except Exception as e:
print(f'Request failed: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
# Launch a real browser to handle JavaScript and anti-bot
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://betalist.com/', wait_until='networkidle')
# Scroll down to trigger lazy loading
page.evaluate('window.scrollTo(0, document.body.scrollHeight)')
page.wait_for_timeout(2000)
# Extract startup data
startups = page.query_selector_all('.startupCard')
for item in startups:
name = item.query_selector('.startupCard__name').inner_text()
tagline = item.query_selector('.startupCard__tagline').inner_text()
print({'startup': name.strip(), 'tagline': tagline.strip()})
browser.close()
run()Python + Scrapy
import scrapy
class BetalistSpider(scrapy.Spider):
name = 'betalist_spider'
start_urls = ['https://betalist.com/topics/ai']
def parse(self, response):
# Scrapy is fast but might need a middleware for Cloudflare
for startup in response.css('.startupCard'):
yield {
'name': startup.css('.startupCard__name::text').get().strip(),
'tagline': startup.css('.startupCard__tagline::text').get().strip(),
'link': response.urljoin(startup.css('a::attr(href)').get())
}
# Handle simple numbered pagination
next_page = response.css('a.pagination__next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Mimic a real user browser to avoid immediate detection
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/110.0.0.0 Safari/537.36');
await page.goto('https://betalist.com/');
// Wait for content to render via JS
await page.waitForSelector('.startupCard');
const results = await page.evaluate(() => {
const cards = Array.from(document.querySelectorAll('.startupCard'));
return cards.map(c => ({
title: c.querySelector('.startupCard__name').innerText.trim(),
description: c.querySelector('.startupCard__tagline').innerText.trim()
}));
});
console.log(results);
await browser.close();
})();Cosa Puoi Fare Con I Dati di BetaList
Esplora applicazioni pratiche e insight dai dati di BetaList.
Lead Enrichment for Sales Teams
B2B agencies use BetaList data to build a pipeline of newly launched startups that need marketing or growth services.
Come implementare:
- 1Scrape startup names and founder profile links from the 'Today' section.
- 2Visit founder profiles to extract Twitter/X handles.
- 3Use a third-party API (like Clay or Apollo) to find the founder's email.
- 4Launch a personalized email sequence referencing their recent BetaList launch.
Usa Automatio per estrarre dati da BetaList e costruire queste applicazioni senza scrivere codice.
Cosa Puoi Fare Con I Dati di BetaList
- Lead Enrichment for Sales Teams
B2B agencies use BetaList data to build a pipeline of newly launched startups that need marketing or growth services.
- Scrape startup names and founder profile links from the 'Today' section.
- Visit founder profiles to extract Twitter/X handles.
- Use a third-party API (like Clay or Apollo) to find the founder's email.
- Launch a personalized email sequence referencing their recent BetaList launch.
- VC Investment Signal Monitoring
Venture capitalists track the growth in upvotes for new startups to identify early viral success.
- Scrape BetaList categories weekly to capture all new submissions.
- Store the heart/upvote count in a database.
- Compare the heart count over a 7-day period to identify 'breakout' startups.
- Assign an analyst to reach out to founders with high growth metrics.
- SaaS Competitor Intelligence
Product managers monitor BetaList to see when new competitors enter their specific niche.
- Scrape listings tagged with relevant topics (e.g., 'Project Management').
- Extract the product description and screenshots.
- Use AI (like GPT-4) to summarize the competitor's unique selling proposition (USP).
- Update the internal competitive landscape document monthly.
- Emerging Tech Trend Reports
Journalists and analysts create data-driven reports on which industries are seeing the most startup activity.
- Scrape the last 6 months of startup data from BetaList.
- Quantify the number of startups per category tag.
- Visualize the rise of specific keywords (e.g., 'LLM', 'Sustainability').
- Publish a 'State of Startups' report for subscribers or stakeholders.
Potenzia il tuo workflow con l'automazione AI
Automatio combina la potenza degli agenti AI, dell'automazione web e delle integrazioni intelligenti per aiutarti a fare di piu in meno tempo.
Consigli Pro per lo Scraping di BetaList
Consigli esperti per estrarre con successo i dati da BetaList.
Estrai dati dalle pagine di dettaglio per i fondatori
L'elenco principale mostra solo dei riassunti; configura il tuo scraper per cliccare su ogni URL delle startup ed estrarre dati preziosi come gli handle Twitter e i link social dei fondatori.
Punta a URL specifici per argomento
Per migliorare l'efficienza e la qualità dei dati, esegui lo scraping di URL di categorie specifiche come /topics/saas o /topics/ai invece di scansionare l'intero sito.
Usa proxy residenziali
Per evitare errori 403 Forbidden dai filtri di sicurezza di BetaList, utilizza proxy residenziali che appaiono come reali utenti domestici piuttosto che come bot di data center.
Implementa tempi di attesa casuali
Simula il comportamento umano aggiungendo ritardi casuali tra 3 e 8 secondi tra le azioni per ridurre la probabilità di innescare i rate limiting.
Controlla i metadati della pagina
Ispeziona il sorgente della pagina alla ricerca di script di hydration o blocchi JSON-LD, poiché spesso contengono dati strutturati più affidabili da estrarre rispetto ai normali elementi HTML.
Testimonianze
Cosa dicono i nostri utenti
Unisciti a migliaia di utenti soddisfatti che hanno trasformato il loro workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Correlati Web Scraping

How to Scrape The AA (theaa.com): A Technical Guide for Car & Insurance Data

How to Scrape CSS Author: A Comprehensive Web Scraping Guide

How to Scrape Bilregistret.ai: Swedish Vehicle Data Extraction Guide

How to Scrape Biluppgifter.se: Vehicle Data Extraction Guide

How to Scrape Car.info | Vehicle Data & Valuation Extraction Guide

How to Scrape GoAbroad Study Abroad Programs

How to Scrape ResearchGate: Publication and Researcher Data

How to Scrape Statista: The Ultimate Guide to Market Data Extraction
Domande frequenti su BetaList
Trova risposte alle domande comuni su BetaList