วิธีดึงข้อมูลจาก Century 21: คู่มือการสกัดข้อมูลอสังหาริมทรัพย์
เรียนรู้วิธีดึงข้อมูลประกาศ ราคา และรายละเอียดตัวแทนจาก Century 21 ข้ามระบบป้องกัน Akamai และ CloudFront เพื่อการสกัดข้อมูลอสังหาริมทรัพย์ที่มีมูลค่าสูง
ตรวจพบการป้องกันบอท
- Akamai Bot Manager
- การตรวจจับบอทขั้นสูงโดยใช้ลายนิ้วมืออุปกรณ์ การวิเคราะห์พฤติกรรม และการเรียนรู้ของเครื่อง เป็นหนึ่งในระบบต่อต้านบอทที่ซับซ้อนที่สุด
- CloudFront
- Google reCAPTCHA
- ระบบ CAPTCHA ของ Google v2 ต้องมีการโต้ตอบของผู้ใช้ v3 ทำงานเงียบๆ ด้วยคะแนนความเสี่ยง สามารถแก้ได้ด้วยบริการ CAPTCHA
- การบล็อก IP
- บล็อก IP ของศูนย์ข้อมูลที่รู้จักและที่อยู่ที่ถูกทำเครื่องหมาย ต้องใช้พร็อกซีที่อยู่อาศัยหรือมือถือเพื่อหลีกเลี่ยงอย่างมีประสิทธิภาพ
- การจำกัดอัตรา
- จำกัดคำขอต่อ IP/เซสชันตามเวลา สามารถหลีกเลี่ยงได้ด้วยพร็อกซีหมุนเวียน การหน่วงเวลาคำขอ และการสแกรปแบบกระจาย
เกี่ยวกับ Century 21
ค้นพบสิ่งที่ Century 21 นำเสนอและข้อมูลที่มีค่าที่สามารถดึงได้
ผู้นำด้านอสังหาริมทรัพย์ระดับโลก
Century 21 Real Estate LLC เป็นบริษัทแฟรนไชส์อสังหาริมทรัพย์ระดับตำนานที่ก่อตั้งขึ้นในปี 1971 ในฐานะบริษัทในเครือของ Anywhere Real Estate โดยบริหารจัดการเครือข่ายขนาดใหญ่ที่มีสำนักงานที่เจ้าของบริหารเองกว่า 14,000 แห่งในกว่า 80 ประเทศ แพลตฟอร์มนี้ทำหน้าที่เป็นศูนย์กลางหลักสำหรับรายการประกาศที่พักอาศัย อสังหาริมทรัพย์เพื่อการพาณิชย์ และอสังหาริมทรัพย์ระดับหรู
ชุดข้อมูลอสังหาริมทรัพย์ที่ครอบคลุม
เว็บไซต์ประกอบด้วยข้อมูลที่มีโครงสร้างเชิงลึก รวมถึงราคาประกาศขาย, รายละเอียดทรัพย์สิน (ห้องนอน, ห้องน้ำ, พื้นที่ใช้สอย), ข้อมูลประชากรในละแวกใกล้เคียง และประวัติการเสียภาษี นอกจากนี้ยังมีโปรไฟล์ที่ครอบคลุมของตัวแทนและสำนักงานนายหน้า รวมถึงข้อมูลติดต่อและที่ตั้งสำนักงาน ทำให้เป็นแหล่งข้อมูลอันล้ำค่าสำหรับการหา leads ในอุตสาหกรรม
มูลค่าสำหรับนักวิทยาศาสตร์ข้อมูล
สำหรับนักลงทุนและนักพัฒนา proptech การดึงข้อมูลจาก Century 21 มีความสำคัญอย่างยิ่งต่อการสร้าง model ประเมินราคา, การติดตามแนวโน้มตลาด และการค้นหาลูกค้าเป้าหมายแบบอัตโนมัติ การสกัดข้อมูลนี้ช่วยให้ธุรกิจได้รับความได้เปรียบในการแข่งขัน ติดตามผลการดำเนินงานของนายหน้า และระบุโอกาสการลงทุนที่ให้ผลตอบแทนสูงได้แบบเรียลไทม์
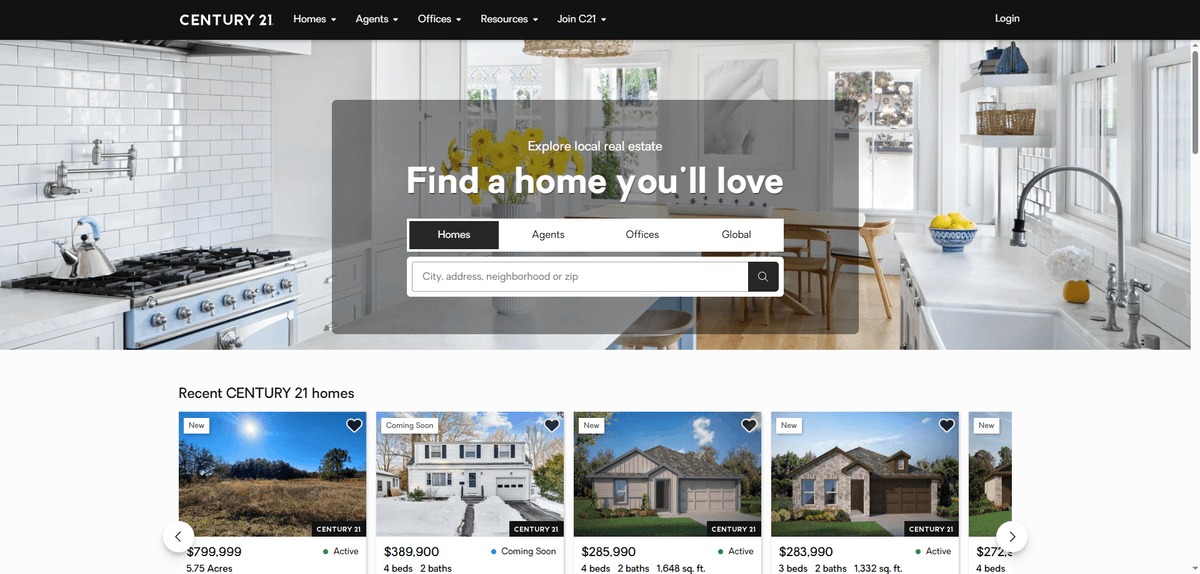
ทำไมต้อง Scrape Century 21?
ค้นพบคุณค่าทางธุรกิจและกรณีการใช้งานสำหรับการดึงข้อมูลจาก Century 21
สร้าง Model ประเมินมูลค่าอสังหาริมทรัพย์
รวบรวมข้อมูลประกาศย้อนหลังและปัจจุบันจำนวนมากเพื่อสร้าง model คาดการณ์สำหรับการประเมินราคาบ้านและการพยากรณ์ตลาด
การระบุโอกาสในการลงทุน
ติดตามการลดราคาและประกาศใหม่แบบเรียลไทม์เพื่อระบุทรัพย์สินที่มีราคาต่ำกว่ามูลค่าจริงสำหรับการเข้าซื้อหรือทำกำไรอย่างรวดเร็ว (flipping)
การหา Leads สำหรับสินเชื่อและเงินกู้
ระบุเจ้าของบ้านใหม่หรือผู้ขายที่ต้องการบริการทางการเงินหรือประกันภัยโดยการติดตามประกาศทรัพย์สินใหม่ๆ
ส่วนแบ่งการตลาดของคู่แข่ง
วิเคราะห์ว่านายหน้าและตัวแทนรายใดครองส่วนแบ่งประกาศขายมากที่สุดในรหัสไปรษณีย์เฉพาะ เพื่อทำความเข้าใจอิทธิพลในตลาดท้องถิ่น
แนวโน้มตลาดระดับจุลภาค
ติดตามการเปลี่ยนแปลงของราคาต่อตารางฟุตและระดับสินค้าคงคลังในระดับละแวกบ้าน เพื่อให้คำแนะนำลูกค้าเกี่ยวกับช่วงเวลาที่ดีที่สุดในการซื้อ
ความท้าทายในการ Scrape
ความท้าทายทางเทคนิคที่คุณอาจพบเมื่อ Scrape Century 21
ระบบป้องกัน Bot ของ Akamai
Century 21 ใช้การวิเคราะห์พฤติกรรมขั้นสูงของ Akamai เพื่อตรวจจับและบล็อก headless browsers และสคริปต์ดึงข้อมูลอัตโนมัติ
การ Render เนื้อหาแบบ Dynamic
เว็บไซต์ใช้ JavaScript frameworks สมัยใหม่ ซึ่งหมายความว่าข้อมูลจะไม่อยู่ในรูปแบบ static HTML และต้องใช้การรันผ่าน browser เต็มรูปแบบ
การจำกัดความถี่ IP ที่รุนแรง
การส่ง request บ่อยครั้งจาก IP address เดียวกันจะกระตุ้นการบล็อกทันทีหรือพบกับความท้าทาย CAPTCHA ซึ่งจำเป็นต้องใช้การหมุนเวียน Residential Proxy
CSS Selectors ที่เปลี่ยนแปลงง่าย
โครงสร้างเว็บไซต์และชื่อ class มีการอัปเดตบ่อยครั้ง จำเป็นต้องใช้ scraper ที่มีคุณสมบัติ self-healing หรือมี logic ที่ยืดหยุ่น
สกัดข้อมูลจาก Century 21 ด้วย AI
ไม่ต้องเขียนโค้ด สกัดข้อมูลภายในไม่กี่นาทีด้วยระบบอัตโนมัติที่ขับเคลื่อนด้วย AI
วิธีการทำงาน
อธิบายสิ่งที่คุณต้องการ
บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก Century 21 แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
AI สกัดข้อมูล
ปัญญาประดิษฐ์ของเรานำทาง Century 21 จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
รับข้อมูลของคุณ
รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
ทำไมต้องใช้ AI ในการสกัดข้อมูล
AI ทำให้การสกัดข้อมูลจาก Century 21 เป็นเรื่องง่ายโดยไม่ต้องเขียนโค้ด แพลตฟอร์มที่ขับเคลื่อนด้วยปัญญาประดิษฐ์ของเราเข้าใจว่าคุณต้องการข้อมูลอะไร — แค่อธิบายเป็นภาษาธรรมชาติ แล้ว AI จะสกัดให้โดยอัตโนมัติ
How to scrape with AI:
- อธิบายสิ่งที่คุณต้องการ: บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก Century 21 แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
- AI สกัดข้อมูล: ปัญญาประดิษฐ์ของเรานำทาง Century 21 จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
- รับข้อมูลของคุณ: รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
Why use AI for scraping:
- No-Code Visual Builder: ดึงข้อมูลที่ซับซ้อนจาก Century 21 ได้เพียงแค่ชี้และคลิก ไม่จำเป็นต้องพัฒนาด้วย Python หรือ Node.js
- ระบบข้าม Akamai ในตัว: Automatio จัดการ browser fingerprints และรูปแบบพฤติกรรมโดยอัตโนมัติเพื่อให้แนบเนียนต่อระบบ anti-bot ที่ซับซ้อน
- การรัน Dynamic JS: เครื่องมือนี้ทำการ render ส่วนประกอบ React แบบ dynamic ได้อย่างสมบูรณ์แบบ มั่นใจได้ว่าจะไม่พลาดรายละเอียดทรัพย์สินหรือรูปภาพใดๆ
- การตั้งเวลาบน Cloud อัตโนมัติ: ตั้งเวลาให้ scraper ทำงานรายวันหรือรายชั่วโมง โดยซิงค์ข้อมูลประกาศใหม่ไปยังฐานข้อมูลหรือ Google Sheets ของคุณโดยตรง
- จัดการ Infinite Scroll และ Pagination: Automatio รองรับปุ่ม 'Load More' และการเลื่อนหน้าจอแบบไม่สิ้นสุดได้ทันที ทำให้ดึงข้อมูลประกาศนับพันรายการได้อย่างง่ายดาย
No-code web scrapers สำหรับ Century 21
ทางเลือกแบบ point-and-click สำหรับการ scraping ด้วย AI
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape Century 21 โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
ความท้าทายทั่วไป
เส้นโค้งการเรียนรู้
การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
Selectors เสีย
การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
ปัญหาเนื้อหาไดนามิก
เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
ข้อจำกัด CAPTCHA
เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
การบล็อก IP
การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
No-code web scrapers สำหรับ Century 21
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape Century 21 โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
- ติดตั้งส่วนขยายเบราว์เซอร์หรือสมัครใช้งานแพลตฟอร์ม
- นำทางไปยังเว็บไซต์เป้าหมายและเปิดเครื่องมือ
- เลือกองค์ประกอบข้อมูลที่ต้องการดึงด้วยการชี้และคลิก
- กำหนดค่า CSS selectors สำหรับแต่ละฟิลด์ข้อมูล
- ตั้งค่ากฎการแบ่งหน้าเพื่อ scrape หลายหน้า
- จัดการ CAPTCHA (มักต้องแก้ไขด้วยตนเอง)
- กำหนดค่าการตั้งเวลาสำหรับการรันอัตโนมัติ
- ส่งออกข้อมูลเป็น CSV, JSON หรือเชื่อมต่อผ่าน API
ความท้าทายทั่วไป
- เส้นโค้งการเรียนรู้: การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
- Selectors เสีย: การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
- ปัญหาเนื้อหาไดนามิก: เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
- ข้อจำกัด CAPTCHA: เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
- การบล็อก IP: การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
ตัวอย่างโค้ด
import requests
from bs4 import BeautifulSoup
# Headers เพื่อเลียนแบบ browser จริงเพื่อหลีกเลี่ยงการบล็อกพื้นฐาน
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9',
'Referer': 'https://www.century21.com/'
}
url = 'https://www.century21.com/real-estate/new-york-ny/LCNYNEWYORK/'
try:
# แนะนำให้ใช้ proxy สำหรับการดึงข้อมูลจาก Century 21
response = requests.get(url, headers=headers, timeout=30)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# ตัวอย่าง: การค้นหาองค์ประกอบราคาอสังหาริมทรัพย์
for card in soup.select('.property-card'):
price = card.select_one('.property-price').text.strip()
address = card.select_one('.property-address').text.strip()
print(f'ราคา: {price} | ที่อยู่: {address}')
except Exception as e:
print(f'ไม่สามารถดึงข้อมูลได้: {e}')เมื่อไหร่ควรใช้
เหมาะที่สุดสำหรับหน้า HTML แบบ static ที่มี JavaScript น้อย เหมาะสำหรับบล็อก ไซต์ข่าว และหน้าสินค้า e-commerce ธรรมดา
ข้อดี
- ●ประมวลผลเร็วที่สุด (ไม่มี overhead ของเบราว์เซอร์)
- ●ใช้ทรัพยากรน้อยที่สุด
- ●ง่ายต่อการทำงานแบบขนานด้วย asyncio
- ●เหมาะมากสำหรับ API และหน้า static
ข้อจำกัด
- ●ไม่สามารถรัน JavaScript ได้
- ●ล้มเหลวใน SPA และเนื้อหาไดนามิก
- ●อาจมีปัญหากับระบบ anti-bot ที่ซับซ้อน
วิธีสเครปข้อมูล Century 21 ด้วยโค้ด
Python + Requests
import requests
from bs4 import BeautifulSoup
# Headers เพื่อเลียนแบบ browser จริงเพื่อหลีกเลี่ยงการบล็อกพื้นฐาน
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9',
'Referer': 'https://www.century21.com/'
}
url = 'https://www.century21.com/real-estate/new-york-ny/LCNYNEWYORK/'
try:
# แนะนำให้ใช้ proxy สำหรับการดึงข้อมูลจาก Century 21
response = requests.get(url, headers=headers, timeout=30)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# ตัวอย่าง: การค้นหาองค์ประกอบราคาอสังหาริมทรัพย์
for card in soup.select('.property-card'):
price = card.select_one('.property-price').text.strip()
address = card.select_one('.property-address').text.strip()
print(f'ราคา: {price} | ที่อยู่: {address}')
except Exception as e:
print(f'ไม่สามารถดึงข้อมูลได้: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_century21():
with sync_playwright() as p:
# เริ่มทำงานด้วย profile ของ browser จริงเพื่อข้ามการตรวจจับ
browser = p.chromium.launch(headless=True)
context = browser.new_context(user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36')
page = context.new_page()
# ไปที่หน้าผลการค้นหาที่ระบุ
page.goto('https://www.century21.com/real-estate/miami-fl/LCCAMIAMI/')
# รอให้การ์ดอสังหาริมทรัพย์แบบ dynamic ทำการ render
page.wait_for_selector('.property-card')
# สกัดข้อมูล
listings = page.query_selector_all('.property-card')
for item in listings:
price = item.query_selector('.property-price').inner_text()
address = item.query_selector('.property-address').inner_text()
print(f'บ้าน: {price}, ทำเล: {address}')
browser.close()
scrape_century21()Python + Scrapy
import scrapy
class Century21Spider(scrapy.Spider):
name = 'century21'
start_urls = ['https://www.century21.com/real-estate/los-angeles-ca/LCCALOSANGELES/']
# การตั้งค่าแบบ Custom เพื่อจัดการ anti-bot และการแบ่งหน้า (pagination)
custom_settings = {
'DOWNLOAD_DELAY': 2,
'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'CONCURRENT_REQUESTS': 1
}
def parse(self, response):
for card in response.css('.property-card'):
yield {
'price': card.css('.property-price::text').get().strip(),
'address': card.css('.property-address::text').get().strip(),
'beds': card.css('.property-beds strong::text').get(),
}
# ติดตามลิงก์หน้าถัดไป (pagination)
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
puppeteer.use(StealthPlugin());
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// ใช้ stealth เพื่อข้าม Akamai/CloudFront
await page.goto('https://www.century21.com/real-estate/san-francisco-ca/LCCASANFRANCISCO/');
// รอให้เนื้อหาของ React โหลดเสร็จ
await page.waitForSelector('.property-card');
const data = await page.evaluate(() => {
const cards = Array.from(document.querySelectorAll('.property-card'));
return cards.map(el => ({
price: el.querySelector('.property-price').innerText.trim(),
address: el.querySelector('.property-address').innerText.trim()
}));
});
console.log(data);
await browser.close();
})();คุณสามารถทำอะไรกับข้อมูล Century 21
สำรวจการใช้งานจริงและข้อมูลเชิงลึกจากข้อมูล Century 21
ระบบประเมินราคาทรัพย์สินเชิงพยากรณ์
นักพัฒนาอสังหาริมทรัพย์ใช้ข้อมูลที่ดึงมาเพื่อสร้างอัลกอริทึมที่คาดการณ์มูลค่าในอนาคตของทรัพย์สิน
วิธีการนำไปใช้:
- 1ดึงราคาประกาศขายปัจจุบันและย้อนหลังในภูมิภาคหนึ่งๆ
- 2นำมาเปรียบเทียบกับพื้นที่ใช้สอยและคะแนนของโรงเรียนในท้องถิ่น
- 3ฝึก machine learning model เพื่อคาดการณ์การเพิ่มขึ้นของมูลค่าทรัพย์สิน
ใช้ Automatio เพื่อดึงข้อมูลจาก Century 21 และสร้างแอปพลิเคชันเหล่านี้โดยไม่ต้องเขียนโค้ด
คุณสามารถทำอะไรกับข้อมูล Century 21
- ระบบประเมินราคาทรัพย์สินเชิงพยากรณ์
นักพัฒนาอสังหาริมทรัพย์ใช้ข้อมูลที่ดึงมาเพื่อสร้างอัลกอริทึมที่คาดการณ์มูลค่าในอนาคตของทรัพย์สิน
- ดึงราคาประกาศขายปัจจุบันและย้อนหลังในภูมิภาคหนึ่งๆ
- นำมาเปรียบเทียบกับพื้นที่ใช้สอยและคะแนนของโรงเรียนในท้องถิ่น
- ฝึก machine learning model เพื่อคาดการณ์การเพิ่มขึ้นของมูลค่าทรัพย์สิน
- การตลาดแบบเจาะกลุ่มเป้าหมายสำหรับผู้ให้กู้
ผู้ให้กู้จำนองสามารถระบุเจ้าของบ้านที่เพิ่งลงประกาศขายทรัพย์สินเพื่อเสนอการรีไฟแนนซ์หรือแพ็คเกจสินเชื่อใหม่
- ติดตามประกาศใหม่บน Century 21 ทุกวัน
- สกัดข้อมูลติดต่อของเจ้าของ/ตัวแทน และประเภททรัพย์สิน
- เชื่อมต่อข้อมูลเข้ากับระบบ CRM เพื่อทำการตลาดแบบอัตโนมัติ
- การเปรียบเทียบสมรรถนะของสำนักงานนายหน้าคู่แข่ง
หน่วยงานต่างๆ วิเคราะห์ประสิทธิภาพการขายของคู่แข่งเพื่อปรับปรุงกลยุทธ์การขายของตนเอง
- ดึงจำนวนประกาศขายของสำนักงานนายหน้าคู่แข่งทั้งหมดในเมือง
- ติดตามระยะเวลาที่ประกาศเปลี่ยนสถานะเป็น 'อยู่ระหว่างสัญญา'
- ระบุพื้นที่ที่บริการของคู่แข่งยังเข้าไม่ถึง
- การเลือกทำเลสำหรับร้านค้าปลีก
นักลงทุนเชิงพาณิชย์ใช้ข้อมูลเพื่อค้นหาทำเลที่ดีที่สุดสำหรับร้านค้าปลีกใหม่โดยอิงจากมูลค่าอสังหาริมทรัพย์ในพื้นที่
- ดึงรายการประกาศเชิงพาณิชย์สำหรับประเภทผังเมืองที่กำหนด
- วิเคราะห์มูลค่าอสังหาริมทรัพย์โดยรอบเพื่อประเมินความมั่งคั่งในพื้นที่
- จัดทำแผนที่ความหนาแน่นของประกาศเพื่อหาพื้นที่ที่ยังไม่มีคู่แข่ง
เพิ่มพลังให้เวิร์กโฟลว์ของคุณด้วย ระบบอัตโนมัติ AI
Automatio รวมพลังของ AI agents การอัตโนมัติเว็บ และการผสานรวมอัจฉริยะเพื่อช่วยให้คุณทำงานได้มากขึ้นในเวลาน้อยลง
เคล็ดลับมืออาชีพสำหรับการ Scrape Century 21
คำแนะนำจากผู้เชี่ยวชาญสำหรับการดึงข้อมูลจาก Century 21 อย่างประสบความสำเร็จ
ใช้ Residential Proxies
IP ของ data center มาตรฐานมักจะถูกตรวจพบและแบนได้ง่าย การใช้ Residential Proxies คุณภาพสูงจึงจำเป็นอย่างยิ่งในการเลียนแบบพฤติกรรมของผู้ใช้จากที่พักอาศัยจริง
ใช้เทคนิค Stealth Browsing
เมื่อใช้เครื่องมือ automation ให้ใช้ stealth plugins เพื่อซ่อนร่องรอยของ headless browser ที่ระบบของ Akamai และ CloudFront มักจะตรวจสอบ
ควบคุมความถี่ของ Request (Throttle)
หลีกเลี่ยงการดึงข้อมูลด้วยความถี่ที่สูงเกินไป ควรเพิ่มการหน่วงเวลาแบบสุ่มระหว่าง 2-10 วินาทีในแต่ละ request เพื่อจำลองพฤติกรรมการใช้งานของมนุษย์
ตรวจสอบ XHR Traffic
ตรวจสอบที่แท็บ Network เพื่อหาการเรียกใช้ JSON API ภายใน เพราะบ่อยครั้งที่ข้อมูลจะถูกโหลดผ่าน endpoint ที่สามารถนำมาประมวลผล (parse) ได้ง่ายกว่า
จัดการกับ Lazy Loading
รายละเอียดประกาศและรูปภาพจำนวนมากจะโหลดเฉพาะเมื่อคุณเลื่อนหน้าจอลงมาเท่านั้น ควรตรวจสอบให้แน่ใจว่า scraper ของคุณมีการเลื่อนหน้าจออย่างช้าๆ เพื่อกระตุ้นให้ข้อมูลโหลดออกมา
หมุนเวียน User-Agents
ควรหมุนเวียนใช้งาน User-Agent จากชุดข้อมูลที่เป็น Browser รุ่นปัจจุบันและมีการใช้งานจริง เพื่อหลีกเลี่ยงการตรวจจับจาก signature พื้นฐาน
คำรับรอง
ผู้ใช้ของเราพูดอย่างไร
เข้าร่วมกับผู้ใช้ที่พึงพอใจนับพันที่ได้เปลี่ยนแปลงเวิร์กโฟลว์ของพวกเขา
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
ที่เกี่ยวข้อง Web Scraping
How to Scrape Homes.com: Real Estate Data Extraction Guide
How to Scrape LivePiazza: Philadelphia Real Estate Scraper
How to Scrape Locations Hawaii | Locations Hawaii Web Scraper
How to Scrape HotPads: A Complete Guide to Extracting Rental Data
How to Scrape Sacramento Delta Property Management
How to Scrape RE/MAX (remax.com) Real Estate Listings
How to Scrape Century 21: A Technical Real Estate Guide

How to Scrape Apartments Near Me | Real Estate Data Scraper
คำถามที่พบบ่อยเกี่ยวกับ Century 21
ค้นหาคำตอบสำหรับคำถามทั่วไปเกี่ยวกับ Century 21