Як скрапити Web Designer News
Дізнайтеся, як скрапити Web Designer News, щоб отримати трендові історії дизайну, URL джерел та часові мітки. Ідеально для моніторингу трендів дизайну та...
Про Web Designer News
Дізнайтеся, що пропонує Web Designer News та які цінні дані можна витягнути.
Огляд Web Designer News
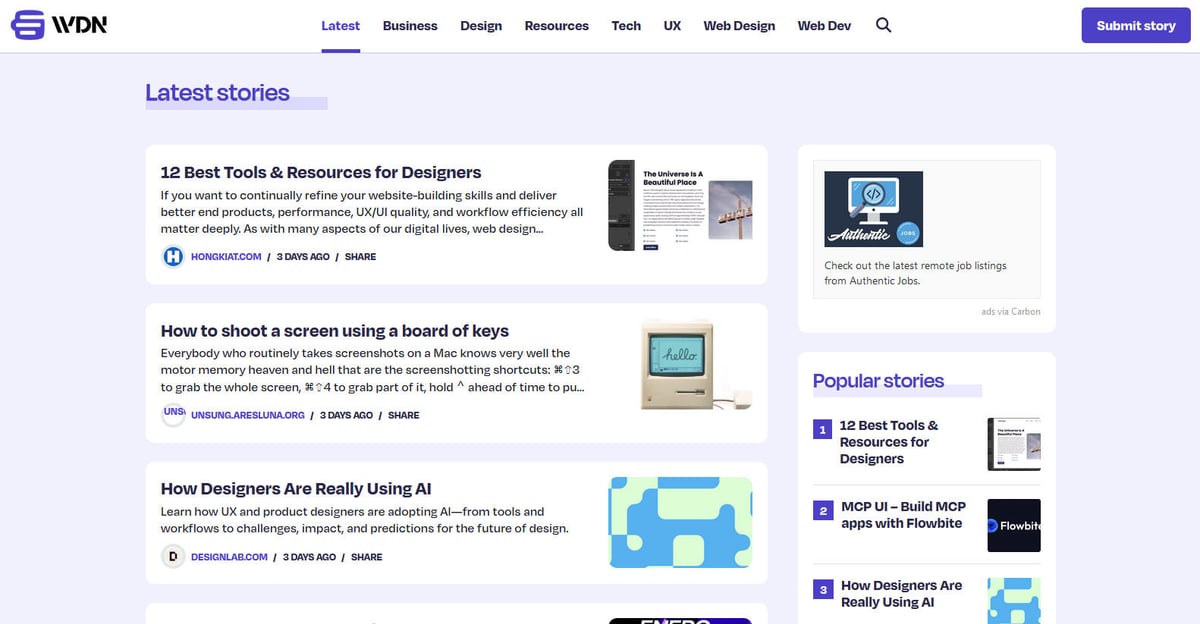
Web Designer News — це провідний агрегатор новин від спільноти, створений спеціально для екосистеми вебдизайну та розробки. З моменту свого заснування платформа функціонує як центральний хаб, де професіонали знаходять ретельно підібрані новини, туторіали, інструменти та ресурси з усього інтернету. Вона охоплює широкий спектр тем, включаючи UX-дизайн, бізнес-стратегію, технологічні оновлення та графічний дизайн, представлені у чистому хронологічному форматі.
Архітектура сайту та потенціал даних
Архітектура сайту побудована на WordPress, що забезпечує чітку структуру макета, де контент організований за категоріями, такими як 'Web Design', 'Web Dev', 'UX' та 'Resources'. Оскільки він агрегує дані з тисяч окремих блогів та журналів у єдиний інтерфейс із можливістю пошуку, він слугує високоякісним фільтром галузевої інформації. Така структура робить його ідеальною ціллю для вебскрапінгу, оскільки надає доступ до потоку перевірених цінних галузевих даних без необхідності сканувати сотні окремих доменів.
Чому Варто Парсити Web Designer News?
Дізнайтеся про бізнес-цінність та сценарії використання для витягування даних з Web Designer News.
Виявлення нових трендів та інструментів дизайну в реальному часі.
Автоматизація кураторства галузевих новин для розсилок та соціальних мереж.
Проведення конкурентного аналізу шляхом моніторингу контенту суперників.
Генерація високоякісних наборів даних для навчання Natural Language Processing (NLP).
Створення централізованої бібліотеки ресурсів дизайну для внутрішньої бази знань команди.
Виклики Парсингу
Технічні виклики, з якими ви можете зіткнутися при парсингу Web Designer News.
Обробка технічних редиректів через внутрішню систему посилань 'go' сайту.
Непостійна наявність зображень-мініатюр у старих архівних записах.
Обмеження частоти запитів (rate limiting) на стороні сервера через захист Nginx.
Скрапінг Web Designer News за допомогою ШІ
Без коду. Витягуйте дані за лічені хвилини з автоматизацією на базі ШІ.
Як це працює
Опишіть, що вам потрібно
Скажіть ШІ, які дані ви хочете витягнути з Web Designer News. Просто напишіть звичайною мовою — без коду чи селекторів.
ШІ витягує дані
Наш штучний інтелект навігує по Web Designer News, обробляє динамічний контент і витягує саме те, що ви запросили.
Отримайте свої дані
Отримайте чисті, структуровані дані, готові до експорту в CSV, JSON або відправки безпосередньо у ваші додатки.
Чому варто використовувати ШІ для скрапінгу
ШІ спрощує скрапінг Web Designer News без написання коду. Наша платформа на базі штучного інтелекту розуміє, які дані вам потрібні — просто опишіть їх звичайною мовою, і ШІ витягне їх автоматично.
How to scrape with AI:
- Опишіть, що вам потрібно: Скажіть ШІ, які дані ви хочете витягнути з Web Designer News. Просто напишіть звичайною мовою — без коду чи селекторів.
- ШІ витягує дані: Наш штучний інтелект навігує по Web Designer News, обробляє динамічний контент і витягує саме те, що ви запросили.
- Отримайте свої дані: Отримайте чисті, структуровані дані, готові до експорту в CSV, JSON або відправки безпосередньо у ваші додатки.
Why use AI for scraping:
- Повністю no-code робочий процес для дизайнерів та маркетологів.
- Хмарне планування дозволяє автоматизувати щоденне вилучення новин.
- Вбудована обробка пагінації та виявлення структурованих елементів.
- Пряма інтеграція з Google Sheets для миттєвого розповсюдження даних.
No-code веб-парсери для Web Designer News
Альтернативи point-and-click до AI-парсингу
Кілька no-code інструментів, таких як Browse.ai, Octoparse, Axiom та ParseHub, можуть допомогти вам парсити Web Designer News без написання коду. Ці інструменти зазвичай використовують візуальні інтерфейси для вибору даних, хоча можуть мати проблеми зі складним динамічним контентом чи anti-bot заходами.
Типовий робочий процес з no-code інструментами
Типові виклики
Крива навчання
Розуміння селекторів та логіки вилучення потребує часу
Селектори ламаються
Зміни на вебсайті можуть зламати весь робочий процес
Проблеми з динамічним контентом
Сайти з великою кількістю JavaScript потребують складних рішень
Обмеження CAPTCHA
Більшість інструментів потребує ручного втручання для CAPTCHA
Блокування IP
Агресивний парсинг може призвести до блокування вашої IP
No-code веб-парсери для Web Designer News
Кілька no-code інструментів, таких як Browse.ai, Octoparse, Axiom та ParseHub, можуть допомогти вам парсити Web Designer News без написання коду. Ці інструменти зазвичай використовують візуальні інтерфейси для вибору даних, хоча можуть мати проблеми зі складним динамічним контентом чи anti-bot заходами.
Типовий робочий процес з no-code інструментами
- Встановіть розширення браузера або зареєструйтесь на платформі
- Перейдіть на цільовий вебсайт і відкрийте інструмент
- Виберіть елементи даних для вилучення методом point-and-click
- Налаштуйте CSS-селектори для кожного поля даних
- Налаштуйте правила пагінації для парсингу кількох сторінок
- Обробіть CAPTCHA (часто потрібне ручне розв'язання)
- Налаштуйте розклад для автоматичних запусків
- Експортуйте дані в CSV, JSON або підключіть через API
Типові виклики
- Крива навчання: Розуміння селекторів та логіки вилучення потребує часу
- Селектори ламаються: Зміни на вебсайті можуть зламати весь робочий процес
- Проблеми з динамічним контентом: Сайти з великою кількістю JavaScript потребують складних рішень
- Обмеження CAPTCHA: Більшість інструментів потребує ручного втручання для CAPTCHA
- Блокування IP: Агресивний парсинг може призвести до блокування вашої IP
Приклади коду
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Надсилаємо запит на головну сторінку
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Знаходимо контейнери постів
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Перевіряємо, чи існує назва сайту-джерела
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Title: {title} | Source: {source} | Link: {link}')
except Exception as e:
print(f'Виникла помилка: {e}')Коли використовувати
Найкраще для статичних HTML-сторінок з мінімумом JavaScript. Ідеально для блогів, новинних сайтів та простих сторінок товарів e-commerce.
Переваги
- ●Найшвидше виконання (без навантаження браузера)
- ●Найменше споживання ресурсів
- ●Легко розпаралелити з asyncio
- ●Чудово для API та статичних сторінок
Обмеження
- ●Не може виконувати JavaScript
- ●Не працює на SPA та динамічному контенті
- ●Може мати проблеми зі складними anti-bot системами
Як парсити Web Designer News за допомогою коду
Python + Requests
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Надсилаємо запит на головну сторінку
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Знаходимо контейнери постів
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Перевіряємо, чи існує назва сайту-джерела
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unknown'
link = post.find('h3').find('a')['href']
print(f'Title: {title} | Source: {source} | Link: {link}')
except Exception as e:
print(f'Виникла помилка: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_wdn():
with sync_playwright() as p:
# Запуск headless браузера
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://webdesignernews.com/')
# Чекаємо на завантаження елементів поста
page.wait_for_selector('.single-post')
posts = page.query_selector_all('.single-post')
for post in posts:
title_el = post.query_selector('h3 a')
if title_el:
title = title_el.inner_text()
link = title_el.get_attribute('href')
print(f'Scraped: {title} - {link}')
browser.close()
scrape_wdn()Python + Scrapy
import scrapy
class WdnSpider(scrapy.Spider):
name = 'wdn_spider'
start_urls = ['https://webdesignernews.com/']
def parse(self, response):
# Витягуємо кожен пост у стрічці
for post in response.css('.single-post'):
yield {
'title': post.css('h3 a::text').get(),
'source': post.css('.site_name::text').get(),
'link': post.css('h3 a::attr(href)').get()
}
# Обробка пагінації через пошук посилання 'Next'
next_page = response.css('a.next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://webdesignernews.com/', { waitUntil: 'domcontentloaded' });
// Оцінюємо сторінку для витягування полів даних
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.single-post'));
return items.map(item => ({
title: item.querySelector('h3 a') ? item.querySelector('h3 a').innerText : null,
source: item.querySelector('.site_name') ? item.querySelector('.site_name').innerText : null,
link: item.querySelector('h3 a') ? item.querySelector('h3 a').href : null
}));
});
console.log(results);
await browser.close();
})();Що Можна Робити З Даними Web Designer News
Досліджуйте практичні застосування та інсайти з даних Web Designer News.
Автоматизована стрічка новин дизайну
Створіть живий, курований канал новин для професійних дизайнерських команд через Slack або Discord.
Як реалізувати:
- 1Скрапте топові історії кожні 4 години.
- 2Фільтруйте результати за відповідними тегами категорій, такими як 'UX' або 'Web Dev'.
- 3Надсилайте отримані заголовки та описи у вебхук месенджера.
- 4Архівуйте дані для відстеження довгострокової популярності галузевих інструментів.
Використовуйте Automatio для витягування даних з Web Designer News та створення цих додатків без написання коду.
Що Можна Робити З Даними Web Designer News
- Автоматизована стрічка новин дизайну
Створіть живий, курований канал новин для професійних дизайнерських команд через Slack або Discord.
- Скрапте топові історії кожні 4 години.
- Фільтруйте результати за відповідними тегами категорій, такими як 'UX' або 'Web Dev'.
- Надсилайте отримані заголовки та описи у вебхук месенджера.
- Архівуйте дані для відстеження довгострокової популярності галузевих інструментів.
- Трекер трендів інструментів дизайну
Визначайте, яке програмне забезпечення для дизайну або бібліотеки отримують найбільшу увагу спільноти.
- Витягніть заголовки та уривки з архіву категорії 'Resources'.
- Проведіть аналіз частоти ключових слів для специфічних термінів (наприклад, 'Figma', 'React').
- Порівнюйте зростання згадок місяць до місяця, щоб виявити нові тренди.
- Експортуйте візуальні звіти для команд маркетингу або продуктової стратегії.
- Моніторинг зворотних посилань конкурентів
Визначайте, які блоги або агентства успішно розміщують контент на головних хабах.
- Скрапте поле 'Назва сайту-джерела' для всіх історичних записів.
- Агрегуйте кількість згадок на зовнішній домен, щоб побачити, хто публікується найчастіше.
- Аналізуйте типи контенту, які приймаються, для покращення власного охоплення.
- Визначайте потенційних партнерів для співпраці у сфері дизайну.
- Набір даних для навчання Machine Learning
Використовуйте куровані фрагменти та описи для навчання моделей технічного резюмування.
- Скрапте понад 10 000 заголовків історій та відповідних описів.
- Очистіть текстові дані від параметрів відстеження та HTML.
- Використовуйте заголовок як ціль, а опис як вхідні дані для fine-tuning.
- Протестуйте модель на нових статтях про дизайн для оцінки продуктивності.
Прискорте вашу роботу з AI-автоматизацією
Automatio поєднує силу AI-агентів, веб-автоматизації та розумних інтеграцій, щоб допомогти вам досягти більшого за менший час.
Професійні Поради Щодо Парсингу Web Designer News
Експертні поради для успішного витягування даних з Web Designer News.
Використовуйте endpoint WordPress REST API (/wp-json/wp/v2/posts) для отримання структурованих даних швидше та надійніше, ніж через парсинг HTML.
Відстежуйте RSS-стрічку сайту за адресою webdesignernews.com/feed/, щоб фіксувати нові історії в момент їх публікації.
Плануйте завдання зі скрапінгу на 9
00 ранку за часом EST, щоб потрапити на пік щоденного оновлення контенту від спільноти.
Змінюйте (ротуйте) рядки User-Agent та встановіть 2-секундну затримку між запитами, щоб уникнути спрацювання лімітів Nginx.
Завжди розкривайте внутрішні посилання '/go/', слідуючи за редиректами, щоб отримати кінцеву канонічну URL джерела.
Очищайте текстові дані уривків, видаляючи HTML-теги та зайві трикрапки для отримання кращих результатів аналізу.
Відгуки
Що кажуть наші користувачі
Приєднуйтесь до тисяч задоволених користувачів, які трансформували свою роботу
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Пов'язані Web Scraping




Часті запитання про Web Designer News
Знайдіть відповіді на поширені запитання про Web Designer News