So scrapen Sie Web Designer News
Erfahre, wie du Web Designer News scrapst, um Trend-Storys, Quell-URLs und Zeitstempel zu extrahieren. Ideal für die Überwachung von Design-Trends und...
Über Web Designer News
Entdecken Sie, was Web Designer News bietet und welche wertvollen Daten extrahiert werden können.
Überblick über Web Designer News
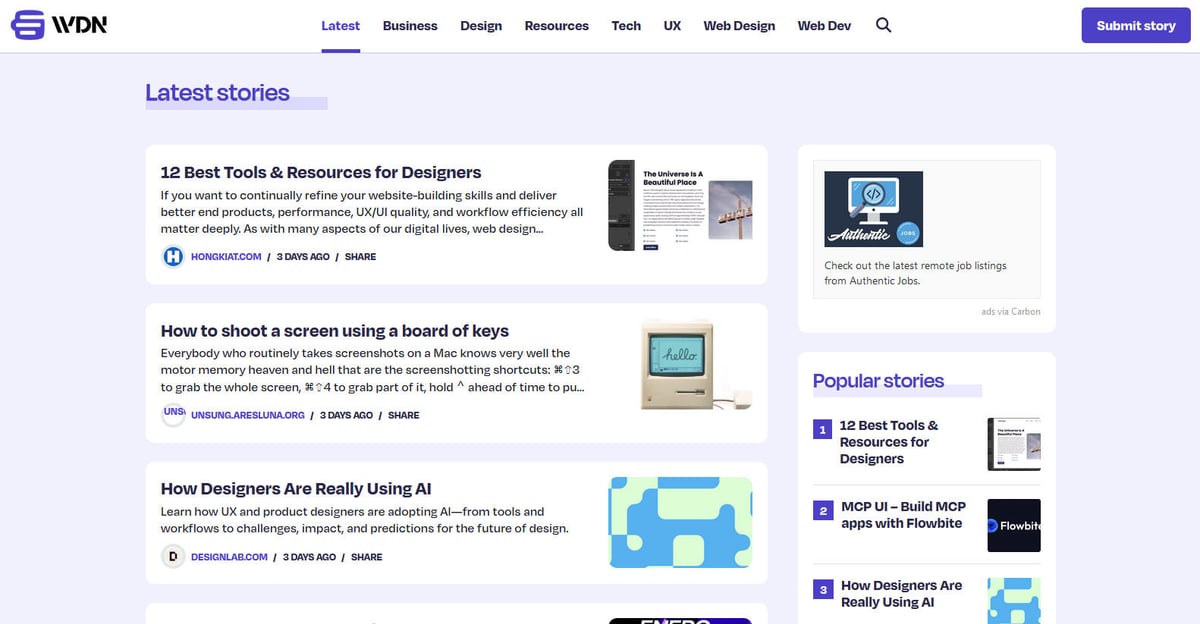
Web Designer News ist ein führender, community-basierter News-Aggregator, der speziell für das Webdesign- und Development-Ökosystem kuratiert wird. Seit seiner Gründung fungiert die Plattform als zentraler Knotenpunkt, an dem Fachleute eine handverlesene Auswahl der relevantesten Nachrichten, Tutorials, Tools und Ressourcen aus dem gesamten Internet entdecken. Sie deckt ein breites Spektrum an Themen ab, darunter UX-Design, Geschäftsstrategie, Technologie-Updates und Grafikdesign, präsentiert in einem sauberen, chronologischen Feed.
Website-Architektur und Datenpotenzial
Die Architektur der Website basiert auf WordPress und verfügt über ein hochstrukturiertes Layout, das Inhalte in spezifische Kategorien wie 'Web Design', 'Web Dev', 'UX' und 'Resources' organisiert. Da sie Daten von Tausenden einzelner Blogs und Fachzeitschriften in einer einzigen, durchsuchbaren Oberfläche aggregiert, dient sie als hochwertiger Filter für Brancheninformationen. Diese Struktur macht sie zu einem idealen Ziel für Web Scraping, da sie Zugriff auf einen vorab geprüften Stream hochwertiger Branchendaten bietet, ohne dass Hunderte von separaten Domains gecrawlt werden müssen.
Warum Web Designer News Scrapen?
Entdecken Sie den Geschäftswert und die Anwendungsfälle für die Datenextraktion von Web Designer News.
Trend-Erkennung in Echtzeit
Erkenne aufstrebende Design-Frameworks, UI-Libraries und Prototyping-Tools in dem Moment, in dem sie in der Fach-Community an Bedeutung gewinnen.
Automatisierte Content-Kuration
Halte deinen eigenen Design-Blog, Newsletter oder deine Social-Media-Kanäle auf dem neuesten Stand, indem du die hochwertigsten, von Branchenexperten geprüften Storys aggregierst.
Marktanalyse
Identifiziere, welche Design-Agenturen und Software-Unternehmen regelmäßig virale oder redaktionell ausgewählte Inhalte produzieren, um Marktführer zu verstehen.
SEO- und Keyword-Recherche
Analysiere Schlagzeilen und Snippets von Trend-Storys, um die relevantesten Keywords und Themen zu identifizieren, die das Interesse der Branche wecken.
Historische Branchenarchivierung
Baue eine langfristige Datenbank der Webdesign-Evolution auf, um zu verfolgen, wie die Popularität bestimmter Stile, Coding-Standards und Technologien über Jahre hinweg schwankt.
B2B Lead-Generierung
Entdecke neue Startups und Agenturen, die auf der Plattform vorgestellt werden, um potenzielle Partner oder Kunden im Bereich kreativer Technologien zu identifizieren.
Scraping-Herausforderungen
Technische Herausforderungen beim Scrapen von Web Designer News.
Interne Tracking-Redirects
Die Website verwendet interne '/go/'-Links für ausgehenden Traffic, was bedeutet, dass ein Scraper Redirects folgen muss, um die tatsächliche Quell-URL zu extrahieren.
Parsen relativer Daten
Zeitstempel werden oft in relativen Formaten wie 'vor 5 Stunden' angezeigt, was eine benutzerdefinierte Logik erfordert, um sie in standardisierte ISO-Datumsformate umzuwandeln.
Probleme mit der Datenkonsistenz
Einige Posts enthalten vollständige beschreibende Snippets und Kategorien, während andere nur einen Titel bieten, was es schwierig macht, eine einheitliche Datenbankstruktur beizubehalten.
Serverseitiges Rate Limiting
Die Nginx-basierte Infrastruktur kann hochfrequente Anfragen erkennen und drosseln, was den Einsatz von Verzögerungen und rotierenden Headern erforderlich macht, um IP-Sperren zu vermeiden.
Scrape Web Designer News mit KI
Kein Code erforderlich. Extrahiere Daten in Minuten mit KI-gestützter Automatisierung.
So funktioniert's
Beschreibe, was du brauchst
Sag der KI, welche Daten du von Web Designer News extrahieren möchtest. Tippe es einfach in natürlicher Sprache ein — kein Code oder Selektoren nötig.
KI extrahiert die Daten
Unsere künstliche Intelligenz navigiert Web Designer News, verarbeitet dynamische Inhalte und extrahiert genau das, was du angefordert hast.
Erhalte deine Daten
Erhalte saubere, strukturierte Daten, bereit zum Export als CSV, JSON oder zum direkten Senden an deine Apps und Workflows.
Warum KI zum Scraping nutzen
KI macht es einfach, Web Designer News zu scrapen, ohne Code zu schreiben. Unsere KI-gestützte Plattform nutzt künstliche Intelligenz, um zu verstehen, welche Daten du möchtest — beschreibe es einfach in natürlicher Sprache und die KI extrahiert sie automatisch.
How to scrape with AI:
- Beschreibe, was du brauchst: Sag der KI, welche Daten du von Web Designer News extrahieren möchtest. Tippe es einfach in natürlicher Sprache ein — kein Code oder Selektoren nötig.
- KI extrahiert die Daten: Unsere künstliche Intelligenz navigiert Web Designer News, verarbeitet dynamische Inhalte und extrahiert genau das, was du angefordert hast.
- Erhalte deine Daten: Erhalte saubere, strukturierte Daten, bereit zum Export als CSV, JSON oder zum direkten Senden an deine Apps und Workflows.
Why use AI for scraping:
- Visuelle Redirect-Handhabung: Automatio kann so konfiguriert werden, dass es internen 'go'-Links automatisch folgt und die finale Ziel-URL erfasst, ohne komplexe Redirection-Logik schreiben zu müssen.
- No-Code Pagination: Navigiere mühelos durch die umfangreichen Archivseiten der Website, indem du einfach den 'Next'-Button in der Point-and-Click-Oberfläche auswählst.
- Cloud-basiertes Scheduling: Führe deine Scraper nach einem täglichen Zeitplan in der Cloud aus, damit deine Design-News-Datenbank ohne manuelles Eingreifen aktuell bleibt.
- Synchronisierung strukturierter Daten: Exportiere deine gescrapten News-Daten direkt nach Google Sheets, Webflow oder über die API, um deine eigenen designfokussierten Anwendungen sofort zu betreiben.
No-Code Web Scraper für Web Designer News
Point-and-Click-Alternativen zum KI-gestützten Scraping
Verschiedene No-Code-Tools wie Browse.ai, Octoparse, Axiom und ParseHub können Ihnen beim Scrapen von Web Designer News helfen. Diese Tools verwenden visuelle Oberflächen zur Elementauswahl, haben aber Kompromisse im Vergleich zu KI-gestützten Lösungen.
Typischer Workflow mit No-Code-Tools
Häufige Herausforderungen
Lernkurve
Das Verständnis von Selektoren und Extraktionslogik braucht Zeit
Selektoren brechen
Website-Änderungen können den gesamten Workflow zerstören
Probleme mit dynamischen Inhalten
JavaScript-lastige Seiten erfordern komplexe Workarounds
CAPTCHA-Einschränkungen
Die meisten Tools erfordern manuelle Eingriffe bei CAPTCHAs
IP-Sperrung
Aggressives Scraping kann zur Sperrung Ihrer IP führen
No-Code Web Scraper für Web Designer News
Verschiedene No-Code-Tools wie Browse.ai, Octoparse, Axiom und ParseHub können Ihnen beim Scrapen von Web Designer News helfen. Diese Tools verwenden visuelle Oberflächen zur Elementauswahl, haben aber Kompromisse im Vergleich zu KI-gestützten Lösungen.
Typischer Workflow mit No-Code-Tools
- Browser-Erweiterung installieren oder auf der Plattform registrieren
- Zur Zielwebseite navigieren und das Tool öffnen
- Per Point-and-Click die zu extrahierenden Datenelemente auswählen
- CSS-Selektoren für jedes Datenfeld konfigurieren
- Paginierungsregeln zum Scrapen mehrerer Seiten einrichten
- CAPTCHAs lösen (erfordert oft manuelle Eingabe)
- Zeitplanung für automatische Ausführungen konfigurieren
- Daten als CSV, JSON exportieren oder per API verbinden
Häufige Herausforderungen
- Lernkurve: Das Verständnis von Selektoren und Extraktionslogik braucht Zeit
- Selektoren brechen: Website-Änderungen können den gesamten Workflow zerstören
- Probleme mit dynamischen Inhalten: JavaScript-lastige Seiten erfordern komplexe Workarounds
- CAPTCHA-Einschränkungen: Die meisten Tools erfordern manuelle Eingriffe bei CAPTCHAs
- IP-Sperrung: Aggressives Scraping kann zur Sperrung Ihrer IP führen
Code-Beispiele
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Anfrage an die Hauptseite senden
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Post-Container lokalisieren
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Prüfen, ob der Name der Quellseite existiert
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unbekannt'
link = post.find('h3').find('a')['href']
print(f'Titel: {title} | Quelle: {source} | Link: {link}')
except Exception as e:
print(f'Ein Fehler ist aufgetreten: {e}')Wann verwenden
Am besten für statische HTML-Seiten, bei denen Inhalte serverseitig geladen werden. Der schnellste und einfachste Ansatz, wenn kein JavaScript-Rendering erforderlich ist.
Vorteile
- ●Schnellste Ausführung (kein Browser-Overhead)
- ●Geringster Ressourcenverbrauch
- ●Einfach zu parallelisieren mit asyncio
- ●Ideal für APIs und statische Seiten
Einschränkungen
- ●Kann kein JavaScript ausführen
- ●Scheitert bei SPAs und dynamischen Inhalten
- ●Kann bei komplexen Anti-Bot-Systemen Probleme haben
Wie man Web Designer News mit Code scrapt
Python + Requests
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
url = 'https://webdesignernews.com/'
try:
# Anfrage an die Hauptseite senden
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Post-Container lokalisieren
posts = soup.find_all('div', class_='single-post')
for post in posts:
title = post.find('h3').get_text(strip=True)
# Prüfen, ob der Name der Quellseite existiert
source = post.find('span', class_='site_name').get_text(strip=True) if post.find('span', class_='site_name') else 'Unbekannt'
link = post.find('h3').find('a')['href']
print(f'Titel: {title} | Quelle: {source} | Link: {link}')
except Exception as e:
print(f'Ein Fehler ist aufgetreten: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_wdn():
with sync_playwright() as p:
# Starte headless browser
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://webdesignernews.com/')
# Warte, bis die Post-Elemente geladen sind
page.wait_for_selector('.single-post')
posts = page.query_selector_all('.single-post')
for post in posts:
title_el = post.query_selector('h3 a')
if title_el:
title = title_el.inner_text()
link = title_el.get_attribute('href')
print(f'Scraped: {title} - {link}')
browser.close()
scrape_wdn()Python + Scrapy
import scrapy
class WdnSpider(scrapy.Spider):
name = 'wdn_spider'
start_urls = ['https://webdesignernews.com/']
def parse(self, response):
# Extrahiere jeden Post im Feed
for post in response.css('.single-post'):
yield {
'title': post.css('h3 a::text').get(),
'source': post.css('.site_name::text').get(),
'link': post.css('h3 a::attr(href)').get()
}
# Pagination: Suche nach dem 'Next'-Link
next_page = response.css('a.next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://webdesignernews.com/', { waitUntil: 'domcontentloaded' });
// Evaluiere die Seite, um Datenfelder zu extrahieren
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.single-post'));
return items.map(item => ({
title: item.querySelector('h3 a') ? item.querySelector('h3 a').innerText : null,
source: item.querySelector('.site_name') ? item.querySelector('.site_name').innerText : null,
link: item.querySelector('h3 a') ? item.querySelector('h3 a').href : null
}));
});
console.log(results);
await browser.close();
})();Was Sie mit Web Designer News-Daten machen können
Entdecken Sie praktische Anwendungen und Erkenntnisse aus Web Designer News-Daten.
Automatisierter Design-News-Feed
Erstellen Sie einen Live-Kanal für kuratierte Nachrichten für professionelle Design-Teams via Slack oder Discord.
So implementieren Sie es:
- 1Scrapen Sie alle 4 Stunden die am besten bewerteten Stories.
- 2Filtern Sie die Ergebnisse nach relevanten Kategorie-Tags wie 'UX' oder 'Web Dev'.
- 3Senden Sie extrahierte Titel und Zusammenfassungen an einen Messaging-Webhook.
- 4Archivieren Sie die Daten, um die langfristige Popularität von Branchen-Tools zu verfolgen.
Verwenden Sie Automatio, um Daten von Web Designer News zu extrahieren und diese Anwendungen ohne Code zu erstellen.
Was Sie mit Web Designer News-Daten machen können
- Automatisierter Design-News-Feed
Erstellen Sie einen Live-Kanal für kuratierte Nachrichten für professionelle Design-Teams via Slack oder Discord.
- Scrapen Sie alle 4 Stunden die am besten bewerteten Stories.
- Filtern Sie die Ergebnisse nach relevanten Kategorie-Tags wie 'UX' oder 'Web Dev'.
- Senden Sie extrahierte Titel und Zusammenfassungen an einen Messaging-Webhook.
- Archivieren Sie die Daten, um die langfristige Popularität von Branchen-Tools zu verfolgen.
- Trend-Tracker für Design-Tools
Identifizieren Sie, welche Design-Software oder Bibliotheken die meiste Resonanz in der Community gewinnen.
- Extrahieren Sie Titel und Auszüge aus dem Archiv der Kategorie 'Resources'.
- Führen Sie eine Keyword-Frequenzanalyse für bestimmte Begriffe durch (z. B. 'Figma', 'React').
- Vergleichen Sie das Wachstum der Nennungen im Monatsvergleich, um Aufsteiger zu identifizieren.
- Exportieren Sie visuelle Berichte für Marketing- oder Produktstrategie-Teams.
- Backlink-Monitoring von Wettbewerbern
Identifizieren Sie, welche Blogs oder Agenturen erfolgreich Inhalte auf großen Hubs platzieren.
- Scrapen Sie das Feld 'Source Website Name' für alle historischen Einträge.
- Aggregieren Sie die Anzahl der Nennungen pro externer Domain, um zu sehen, wer am häufigsten gefeatured wird.
- Analysieren Sie die Arten von Inhalten, die akzeptiert werden, für ein besseres Outreach.
- Identifizieren Sie potenzielle Kooperationspartner im Designbereich.
- Trainingsdatensatz für machine learning
Nutzen Sie die kuratierten Snippets und Zusammenfassungen, um technische Zusammenfassungs-Modelle zu trainieren.
- Scrapen Sie über 10.000 Story-Titel und entsprechende Zusammenfassungen.
- Bereinigen Sie die Textdaten von internen Tracking-Parametern und HTML.
- Verwenden Sie den Titel als Ziel und den Auszug als Input für das fine-tuning.
- Testen Sie das model an neuen, unbekannten Design-Artikeln auf seine Performance.
Optimieren Sie Ihren Workflow mit KI-Automatisierung
Automatio kombiniert die Kraft von KI-Agenten, Web-Automatisierung und intelligenten Integrationen, um Ihnen zu helfen, mehr in weniger Zeit zu erreichen.
Profi-Tipps für das Scrapen von Web Designer News
Expertentipps für die erfolgreiche Datenextraktion von Web Designer News.
Nutze die REST API
Greife auf die WordPress REST API der Website unter /wp-json/wp/v2/posts zu, um einen saubereren, strukturierten JSON-Feed zu erhalten, der schneller verarbeitet werden kann als reines HTML.
Überwache die Sidebar
Scrape die Sidebar-Bereiche 'Popular' und 'Recent', um Content mit hohem Engagement für deine Kuration oder Analyse zu priorisieren.
Browser-Header rotieren
Verwende stets realistische User-Agent-Strings und rotiere diese, um verschiedene Browsertypen zu simulieren und das Risiko einer Blockierung durch die Nginx-Security zu verringern.
Kategorie-Metadaten extrahieren
Ziele auf die spezifischen CSS-Klassen für Post-Kategorien ab, um tiefgehendes Filtern und thematische Analysen in deinem finalen Datensatz zu ermöglichen.
Umgang mit Lazy Images
Vorschaubilder können Lazy-Loading verwenden; stelle sicher, dass dein Scraper die Attribute 'data-src' oder 'srcset' ansteuert, um keine visuellen Assets zu verpassen.
Request-Verzögerungen implementieren
Eine einfache Verzögerung von 2-3 Sekunden zwischen den Anfragen stellt sicher, dass du den Server nicht überlastest, und hilft dabei, dass deine Scraping-Aktivitäten unentdeckt bleiben.
Erfahrungsberichte
Was Unsere Nutzer Sagen
Schliessen Sie sich Tausenden zufriedener Nutzer an, die ihren Workflow transformiert haben
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Verwandte Web Scraping




Häufig gestellte Fragen zu Web Designer News
Finden Sie Antworten auf häufige Fragen zu Web Designer News