Cómo hacer scraping en BetaList | Guía de Web Scraper para BetaList
Aprende a realizar scraping en BetaList para extraer leads de startups, datos de fundadores y tendencias tecnológicas. Domina cómo evadir Cloudflare y el...
Protección Anti-Bot Detectada
- Cloudflare
- WAF y gestión de bots de nivel empresarial. Usa desafíos JavaScript, CAPTCHAs y análisis de comportamiento. Requiere automatización de navegador con configuración sigilosa.
- Limitación de velocidad
- Limita solicitudes por IP/sesión en el tiempo. Se puede eludir con proxies rotativos, retrasos en solicitudes y scraping distribuido.
- Bloqueo de IP
- Bloquea IPs de centros de datos conocidos y direcciones marcadas. Requiere proxies residenciales o móviles para eludir efectivamente.
- Huella del navegador
- Identifica bots por características del navegador: canvas, WebGL, fuentes, plugins. Requiere spoofing o perfiles de navegador reales.
Acerca de BetaList
Descubre qué ofrece BetaList y qué datos valiosos se pueden extraer.
La Plataforma Líder para el Descubrimiento de Startups
BetaList es una plataforma de descubrimiento ampliamente reconocida dedicada a startups de internet en etapa temprana. Fundada por Marc Köhlbrugge, sirve como trampolín para que los fundadores conecten con early adopters, recopilen feedback y generen tracción inicial antes de entrar en mercados masivos como Product Hunt o la App Store.
Perfiles de Startups Ricos en Datos
La plataforma ofrece un vasto directorio de listados en sectores como SaaS, Inteligencia Artificial, Fintech y E-commerce. Cada listado contiene metadatos valiosos, incluyendo eslóganes de la startup, descripciones detalladas del producto, capturas de pantalla de alta resolución, perfiles de fundadores y enlaces a redes sociales. Estos datos proporcionan una instantánea de las innovaciones más recientes en el ecosistema tecnológico.
Valor Estratégico para el Scraping de Datos
Para investigadores y empresas, hacer scraping en BetaList es esencial para identificar tendencias emergentes y captar leads B2B de alta calidad. Los inversores utilizan la plataforma para detectar startups de alto potencial en su infancia, mientras que los proveedores de servicios (agencias, desarrolladores y especialistas en marketing) la utilizan para contactar a fundadores que buscan activamente herramientas de crecimiento y soporte.
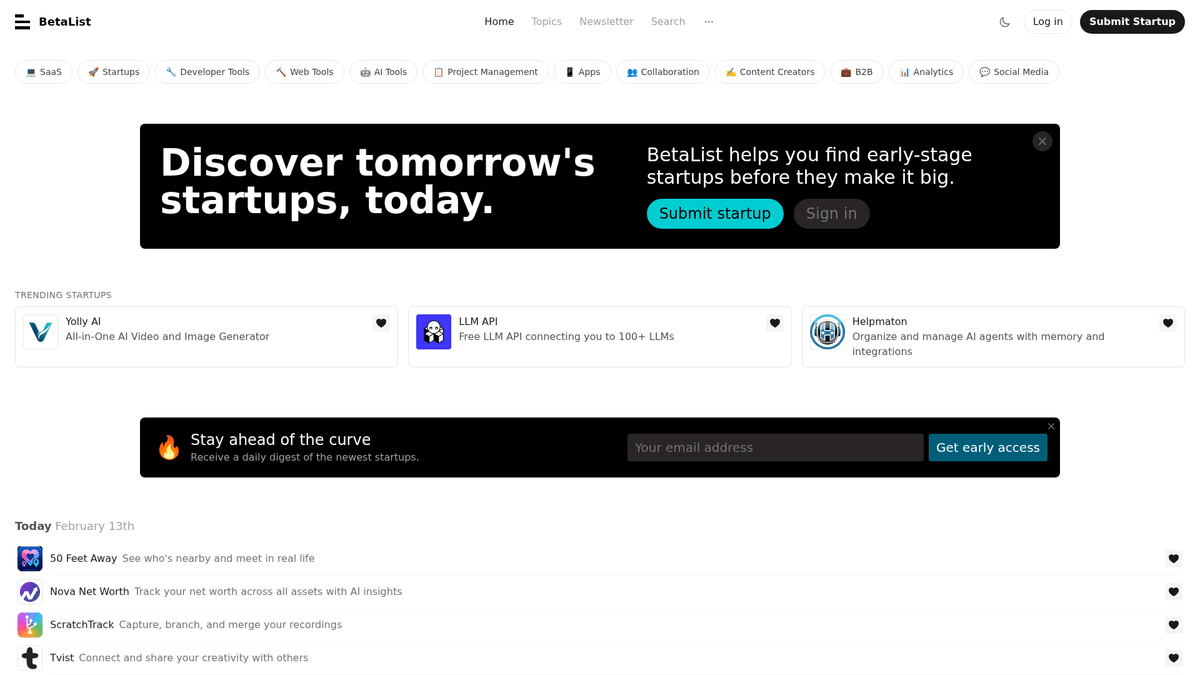
¿Por Qué Scrapear BetaList?
Descubre el valor comercial y los casos de uso para extraer datos de BetaList.
Generación de leads para ventas B2B
BetaList detecta startups en su etapa más temprana, lo que la convierte en una fuente ideal para que agencias y proveedores de servicios encuentren nuevas empresas que necesiten ayuda en marketing, legal o desarrollo.
Flujo de acuerdos para Venture Capital
Inversores y VCs utilizan los datos de BetaList para descubrir empresas tecnológicas emergentes antes de que ganen popularidad masiva en plataformas más grandes como Product Hunt o Crunchbase.
Análisis de tendencias de mercado
Al extraer las etiquetas de categoría y las fechas de envío, los investigadores pueden identificar qué nichos tecnológicos, como Generative AI o Web3, presentan actualmente la mayor actividad emprendedora.
Inteligencia competitiva
Las empresas SaaS pueden monitorizar a los nuevos integrantes en su nicho de industria específico para seguir de cerca las funciones innovadoras y los cambios en el posicionamiento de mercado de competidores potenciales.
Networking y contacto con fundadores
Extraer los nombres de los fundadores y sus perfiles de Twitter permite a reclutadores y consultores contactar directamente con emprendedores que están construyendo y lanzando nuevos productos activamente.
Desafíos de Scraping
Desafíos técnicos que puedes encontrar al scrapear BetaList.
Mitigación de bots de Cloudflare
BetaList utiliza Cloudflare para proteger su directorio, lo que a menudo bloquea los scripts automatizados estándar y requiere una gestión sofisticada de encabezados o herramientas basadas en navegador.
Carga mediante scroll infinito
La lista de startups utiliza carga dinámica mediante scroll infinito, lo que significa que los datos no están presentes en el HTML inicial y requieren un scraper que pueda simular la interacción del usuario y ejecutar JavaScript.
Estructura DOM dinámica
El sitio web utiliza frameworks de frontend modernos donde los elementos se inyectan dinámicamente, lo que obliga al scraper a esperar a que aparezcan selectores específicos antes de intentar extraer los datos.
Rate limiting agresivo
Enviar solicitudes rápidamente a las páginas de detalles de las startups puede provocar bloqueos temporales de IP, por lo que es necesario implementar retrasos aleatorios y una rotación de proxies de alta calidad.
Scrapea BetaList con IA
Sin código necesario. Extrae datos en minutos con automatización impulsada por IA.
Cómo Funciona
Describe lo que necesitas
Dile a la IA qué datos quieres extraer de BetaList. Solo escríbelo en lenguaje natural — sin código ni selectores.
La IA extrae los datos
Nuestra inteligencia artificial navega BetaList, maneja contenido dinámico y extrae exactamente lo que pediste.
Obtén tus datos
Recibe datos limpios y estructurados listos para exportar como CSV, JSON o enviar directamente a tus aplicaciones.
Por Qué Usar IA para el Scraping
La IA facilita el scraping de BetaList sin escribir código. Nuestra plataforma impulsada por inteligencia artificial entiende qué datos quieres — solo descríbelo en lenguaje natural y la IA los extrae automáticamente.
How to scrape with AI:
- Describe lo que necesitas: Dile a la IA qué datos quieres extraer de BetaList. Solo escríbelo en lenguaje natural — sin código ni selectores.
- La IA extrae los datos: Nuestra inteligencia artificial navega BetaList, maneja contenido dinámico y extrae exactamente lo que pediste.
- Obtén tus datos: Recibe datos limpios y estructurados listos para exportar como CSV, JSON o enviar directamente a tus aplicaciones.
Why use AI for scraping:
- Scraping visual sin código: Automatio te permite crear un scraper para BetaList simplemente haciendo clic en las fichas de las startups y los enlaces sociales, eliminando la necesidad de escribir código complejo en Python o Node.js.
- Gestión automatizada anti-bots: La plataforma gestiona automáticamente las huellas dactilares del navegador y los proxies para superar los desafíos de Cloudflare que suelen bloquear a los scrapers programados a medida.
- Extracción de leads programada: Configura tu scraper para que se ejecute diaria o semanalmente para capturar automáticamente las startups recién enviadas y enviarlas directamente a tu CRM o Google Sheets para un contacto inmediato.
- Manejo de scroll infinito: Automatio gestiona de forma nativa el scroll infinito y las acciones de 'Cargar más', asegurando que puedas extraer miles de listados históricos de startups sin intervención manual.
Scrapers Sin Código para BetaList
Alternativas de apuntar y clic al scraping con IA
Varias herramientas sin código como Browse.ai, Octoparse, Axiom y ParseHub pueden ayudarte a scrapear BetaList. Estas herramientas usan interfaces visuales para seleccionar elementos, pero tienen desventajas comparadas con soluciones con IA.
Flujo de Trabajo Típico con Herramientas Sin Código
Desafíos Comunes
Curva de aprendizaje
Comprender selectores y lógica de extracción lleva tiempo
Los selectores se rompen
Los cambios en el sitio web pueden romper todo el flujo de trabajo
Problemas con contenido dinámico
Los sitios con mucho JavaScript requieren soluciones complejas
Limitaciones de CAPTCHA
La mayoría de herramientas requieren intervención manual para CAPTCHAs
Bloqueo de IP
El scraping agresivo puede resultar en el bloqueo de tu IP
Scrapers Sin Código para BetaList
Varias herramientas sin código como Browse.ai, Octoparse, Axiom y ParseHub pueden ayudarte a scrapear BetaList. Estas herramientas usan interfaces visuales para seleccionar elementos, pero tienen desventajas comparadas con soluciones con IA.
Flujo de Trabajo Típico con Herramientas Sin Código
- Instalar extensión del navegador o registrarse en la plataforma
- Navegar al sitio web objetivo y abrir la herramienta
- Seleccionar con point-and-click los elementos de datos a extraer
- Configurar selectores CSS para cada campo de datos
- Configurar reglas de paginación para scrapear múltiples páginas
- Resolver CAPTCHAs (frecuentemente requiere intervención manual)
- Configurar programación para ejecuciones automáticas
- Exportar datos a CSV, JSON o conectar vía API
Desafíos Comunes
- Curva de aprendizaje: Comprender selectores y lógica de extracción lleva tiempo
- Los selectores se rompen: Los cambios en el sitio web pueden romper todo el flujo de trabajo
- Problemas con contenido dinámico: Los sitios con mucho JavaScript requieren soluciones complejas
- Limitaciones de CAPTCHA: La mayoría de herramientas requieren intervención manual para CAPTCHAs
- Bloqueo de IP: El scraping agresivo puede resultar en el bloqueo de tu IP
Ejemplos de Código
import requests
from bs4 import BeautifulSoup
# Nota: BetaList utiliza Cloudflare; requests por sí solo puede obtener un 403 Forbidden.
# Normalmente necesitas un bypass o usar una sesión con headers realistas.
url = 'https://betalist.com/topics/saas'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Apuntar a los contenedores de las tarjetas de startups
for card in soup.select('.startupCard'):
name = card.select_one('.startupCard__name').get_text(strip=True)
tagline = card.select_one('.startupCard__tagline').get_text(strip=True)
print(f'Extraído: {name} - {tagline}')
except Exception as e:
print(f'La petición falló: {e}')Cuándo Usar
Mejor para páginas HTML estáticas donde el contenido se carga del lado del servidor. El enfoque más rápido y simple cuando no se requiere renderizado de JavaScript.
Ventajas
- ●Ejecución más rápida (sin sobrecarga del navegador)
- ●Menor consumo de recursos
- ●Fácil de paralelizar con asyncio
- ●Excelente para APIs y páginas estáticas
Limitaciones
- ●No puede ejecutar JavaScript
- ●Falla en SPAs y contenido dinámico
- ●Puede tener dificultades con sistemas anti-bot complejos
Cómo Scrapear BetaList con Código
Python + Requests
import requests
from bs4 import BeautifulSoup
# Nota: BetaList utiliza Cloudflare; requests por sí solo puede obtener un 403 Forbidden.
# Normalmente necesitas un bypass o usar una sesión con headers realistas.
url = 'https://betalist.com/topics/saas'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Apuntar a los contenedores de las tarjetas de startups
for card in soup.select('.startupCard'):
name = card.select_one('.startupCard__name').get_text(strip=True)
tagline = card.select_one('.startupCard__tagline').get_text(strip=True)
print(f'Extraído: {name} - {tagline}')
except Exception as e:
print(f'La petición falló: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
# Lanzar un navegador real para manejar JavaScript y anti-bot
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://betalist.com/', wait_until='networkidle')
# Desplazar hacia abajo para activar el lazy loading
page.evaluate('window.scrollTo(0, document.body.scrollHeight)')
page.wait_for_timeout(2000)
# Extraer datos de startups
startups = page.query_selector_all('.startupCard')
for item in startups:
name = item.query_selector('.startupCard__name').inner_text()
tagline = item.query_selector('.startupCard__tagline').inner_text()
print({'startup': name.strip(), 'tagline': tagline.strip()})
browser.close()
run()Python + Scrapy
import scrapy
class BetalistSpider(scrapy.Spider):
name = 'betalist_spider'
start_urls = ['https://betalist.com/topics/ai']
def parse(self, response):
# Scrapy es rápido pero podría necesitar un middleware para Cloudflare
for startup in response.css('.startupCard'):
yield {
'name': startup.css('.startupCard__name::text').get().strip(),
'tagline': startup.css('.startupCard__tagline::text').get().strip(),
'link': response.urljoin(startup.css('a::attr(href)').get())
}
# Manejo de paginación numérica simple
next_page = response.css('a.pagination__next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Simular un navegador de usuario real para evitar la detección inmediata
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/110.0.0.0 Safari/537.36');
await page.goto('https://betalist.com/');
// Esperar a que el contenido se renderice vía JS
await page.waitForSelector('.startupCard');
const results = await page.evaluate(() => {
const cards = Array.from(document.querySelectorAll('.startupCard'));
return cards.map(c => ({
title: c.querySelector('.startupCard__name').innerText.trim(),
description: c.querySelector('.startupCard__tagline').innerText.trim()
}));
});
console.log(results);
await browser.close();
})();Qué Puedes Hacer Con Los Datos de BetaList
Explora aplicaciones prácticas e insights de los datos de BetaList.
Enriquecimiento de Leads para Equipos de Ventas
Las agencias B2B utilizan los datos de BetaList para construir un pipeline de startups recién lanzadas que necesitan servicios de marketing o crecimiento.
Cómo implementar:
- 1Extrae nombres de startups y enlaces a perfiles de fundadores de la sección 'Today'.
- 2Visita los perfiles de los fundadores para extraer sus nombres de usuario de Twitter/X.
- 3Usa una API de terceros (como Clay o Apollo) para encontrar el email del fundador.
- 4Lanza una secuencia de correos personalizados haciendo referencia a su reciente lanzamiento en BetaList.
Usa Automatio para extraer datos de BetaList y crear estas aplicaciones sin escribir código.
Qué Puedes Hacer Con Los Datos de BetaList
- Enriquecimiento de Leads para Equipos de Ventas
Las agencias B2B utilizan los datos de BetaList para construir un pipeline de startups recién lanzadas que necesitan servicios de marketing o crecimiento.
- Extrae nombres de startups y enlaces a perfiles de fundadores de la sección 'Today'.
- Visita los perfiles de los fundadores para extraer sus nombres de usuario de Twitter/X.
- Usa una API de terceros (como Clay o Apollo) para encontrar el email del fundador.
- Lanza una secuencia de correos personalizados haciendo referencia a su reciente lanzamiento en BetaList.
- Monitoreo de Señales de Inversión para VC
Los capitalistas de riesgo rastrean el crecimiento de los votos positivos para nuevas startups con el fin de identificar éxitos virales tempranos.
- Extrae las categorías de BetaList semanalmente para capturar todos los nuevos registros.
- Almacena el recuento de corazones/votos en una base de datos.
- Compara el recuento de votos durante un período de 7 días para identificar startups con crecimiento explosivo.
- Asigna a un analista para contactar a los fundadores con métricas de alto crecimiento.
- Inteligencia Competitiva de SaaS
Los product managers monitorean BetaList para ver cuándo entran nuevos competidores en su nicho específico.
- Extrae listados etiquetados con temas relevantes (ej. 'Gestión de Proyectos').
- Extrae la descripción del producto y las capturas de pantalla.
- Usa AI (como GPT-4) para resumir la propuesta única de venta (USP) del competidor.
- Actualiza mensualmente el documento interno de panorama competitivo.
- Informes de Tendencias Tecnológicas Emergentes
Periodistas y analistas crean informes basados en datos sobre qué industrias están experimentando la mayor actividad de startups.
- Extrae los datos de startups de los últimos 6 meses de BetaList.
- Cuantifica el número de startups por etiqueta de categoría.
- Visualiza el auge de palabras clave específicas (ej. 'LLM', 'Sostenibilidad').
- Publica un informe del 'Estado de las Startups' para suscriptores o partes interesadas.
Potencia tu flujo de trabajo con Automatizacion IA
Automatio combina el poder de agentes de IA, automatizacion web e integraciones inteligentes para ayudarte a lograr mas en menos tiempo.
Consejos Pro para Scrapear BetaList
Consejos expertos para extraer datos exitosamente de BetaList.
Extrae datos de las páginas de detalles de los fundadores
La lista principal solo muestra resúmenes; configura tu scraper para entrar en la URL de cada startup y extraer datos valiosos como los perfiles de Twitter de los fundadores y sus redes sociales.
Enfócate en URLs de temas específicos
Para mejorar la eficiencia y la calidad de los datos, realiza scraping en URLs de categorías específicas como /topics/saas o /topics/ai en lugar de rastrear todo el sitio.
Usa proxies residenciales
Para evitar errores 403 Forbidden de los filtros de seguridad de BetaList, utiliza proxies residenciales que parecen usuarios reales desde su hogar en lugar de bots de centros de datos.
Implementa tiempos de espera aleatorios
Simula el comportamiento humano añadiendo retrasos aleatorios de entre 3 y 8 segundos entre acciones para reducir la probabilidad de activar los rate limits.
Revisa los metadatos de la página
Inspecciona el código fuente de la página en busca de scripts de hidratación o bloques JSON-LD, ya que suelen contener datos estructurados que son más fiables de extraer que los elementos HTML puros.
Testimonios
Lo Que Dicen Nuestros Usuarios
Unete a miles de usuarios satisfechos que han transformado su flujo de trabajo
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relacionados Web Scraping

How to Scrape The AA (theaa.com): A Technical Guide for Car & Insurance Data

How to Scrape CSS Author: A Comprehensive Web Scraping Guide

How to Scrape Bilregistret.ai: Swedish Vehicle Data Extraction Guide

How to Scrape Biluppgifter.se: Vehicle Data Extraction Guide

How to Scrape Car.info | Vehicle Data & Valuation Extraction Guide

How to Scrape GoAbroad Study Abroad Programs

How to Scrape ResearchGate: Publication and Researcher Data

How to Scrape Statista: The Ultimate Guide to Market Data Extraction
Preguntas Frecuentes Sobre BetaList
Encuentra respuestas a preguntas comunes sobre BetaList