Comment scraper LivePiazza : Scraper immobilier pour Philadelphie
Découvrez comment scraper LivePiazza.com pour extraire les prix des appartements de luxe, la disponibilité et les plans d'étage. Surveillez le marché...
Protection Anti-Bot Détectée
- Cloudflare
- WAF et gestion de bots de niveau entreprise. Utilise des défis JavaScript, des CAPTCHAs et l'analyse comportementale. Nécessite l'automatisation du navigateur avec des paramètres furtifs.
- Limitation de débit
- Limite les requêtes par IP/session dans le temps. Peut être contourné avec des proxys rotatifs, des délais de requête et du scraping distribué.
- Empreinte navigateur
- Identifie les bots par les caractéristiques du navigateur : canvas, WebGL, polices, plugins. Nécessite du spoofing ou de vrais profils de navigateur.
- Défi JavaScript
- Nécessite l'exécution de JavaScript pour accéder au contenu. Les requêtes simples échouent ; un navigateur headless comme Playwright ou Puppeteer est nécessaire.
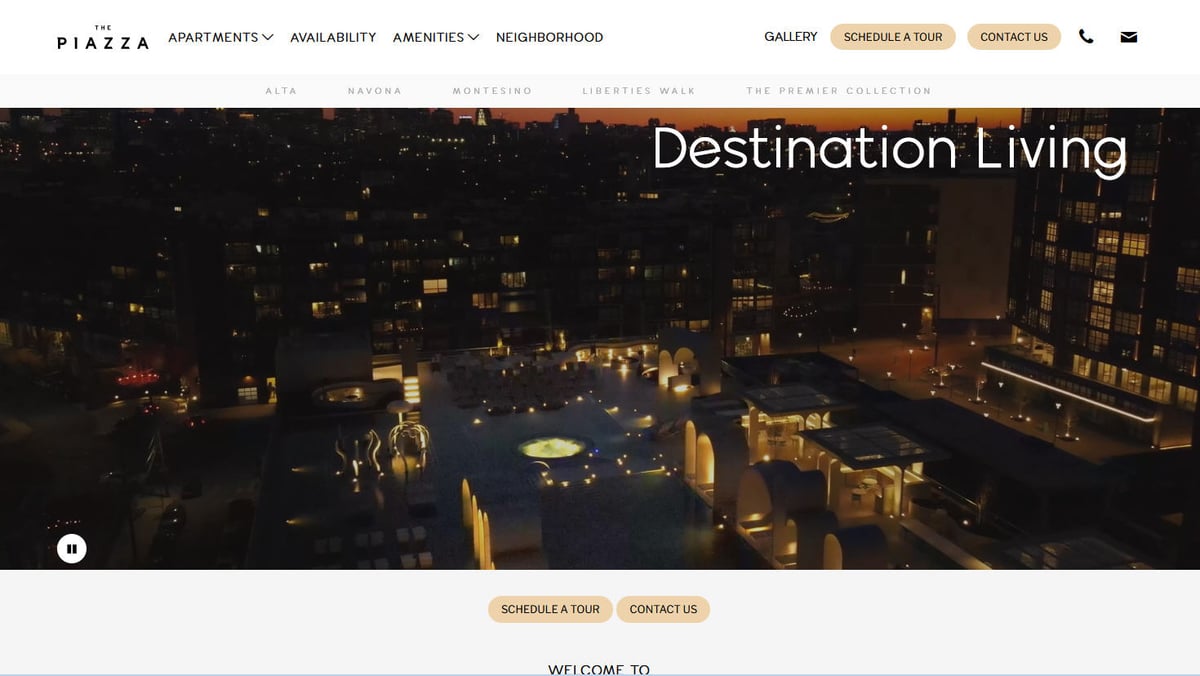
À Propos de The Piazza
Découvrez ce que The Piazza offre et quelles données précieuses peuvent être extraites.
The Piazza, géré par Post Brothers, est un développement résidentiel et commercial de premier plan dans le quartier de Northern Liberties à Philadelphie. Il comprend quatre communautés de luxe distinctes — Alta, Navona, Montesino et Liberties Walk — offrant une expérience de 'ville dans la ville' avec des équipements haut de gamme et un design moderne.
Le site web fonctionne comme un portail en temps réel pour les futurs résidents, affichant les tarifs de location actuels, les dates de disponibilité des unités spécifiques et les options détaillées de finition intérieure. Pour les data scientists et les analystes immobiliers, LivePiazza représente une source de données critique pour comprendre le marché multifamilial de luxe dans l'un des couloirs urbains à la croissance la plus rapide du Nord-Est.
Le scraping de ces données permet une surveillance à haute fréquence des tendances de prix, des niveaux d'occupation et de l'efficacité des diverses incitations à la location offertes par les promoteurs immobiliers de grande envergure.
Pourquoi Scraper The Piazza?
Découvrez la valeur commerciale et les cas d'utilisation pour l'extraction de données de The Piazza.
Benchmark du marché en temps réel
Analysez les tendances de la location de luxe à Philadelphie en suivant les tarifs actuels des propriétés Alta, Navona et Montesino.
Suivi de l'offre et de la demande
Suivez la disponibilité des unités au fil du temps pour calculer les taux d'occupation et comprendre les niveaux d'absorption du quartier.
Suivi des concessions de loyer
Surveillez les offres promotionnelles telles que les mois de loyer gratuits pour déterminer le loyer net effectif par rapport au prix brut affiché.
Recherche sur les stratégies concurrentielles
Évaluez comment Post Brothers ajuste les prix pour des plans d'étage spécifiques ou des finitions intérieures en fonction de la demande du marché.
Génération de leads pour des services
Identifiez les disponibilités d'unités à venir pour cibler les déménageurs, les décorateurs d'intérieur et les détaillants de meubles locaux avec un marketing ciblé.
Analyse d'investissement
Collectez des données historiques sur les prix pour aider les investisseurs à déterminer le ROI des équipements de luxe et des développements urbains.
Défis du Scraping
Défis techniques que vous pouvez rencontrer lors du scraping de The Piazza.
Protection Cloudflare
Le site utilise un WAF Cloudflare agressif qui déclenche des challenges JS et bloque les requêtes provenant de bibliothèques HTTP standards.
Rendu de contenu dynamique
Les tableaux d'annonces et les cartes interactives sont rendus via React, ce qui nécessite un navigateur headless pour exécuter le JavaScript afin d'extraire les données.
Injections de données XHR
Les prix et la disponibilité sont souvent injectés via des appels d'API internes utilisant des tokens basés sur la session, qui peuvent expirer pendant le crawl.
Ressources en chargement différé
Les images de plans d'étage de haute qualité et les photos d'unités utilisent le lazy-loading, nécessitant des déclencheurs de défilement pour s'assurer que tous les médias sont capturés.
Changements fréquents de schéma
Le backend de gestion immobilière met fréquemment à jour sa structure DOM, ce qui peut casser les sélecteurs statiques s'ils ne sont pas gérés de manière dynamique.
Scrapez The Piazza avec l'IA
Aucun code requis. Extrayez des données en minutes avec l'automatisation par IA.
Comment ça marche
Décrivez ce dont vous avez besoin
Dites à l'IA quelles données vous souhaitez extraire de The Piazza. Tapez simplement en langage naturel — pas de code ni de sélecteurs.
L'IA extrait les données
Notre intelligence artificielle navigue sur The Piazza, gère le contenu dynamique et extrait exactement ce que vous avez demandé.
Obtenez vos données
Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Pourquoi utiliser l'IA pour le scraping
L'IA facilite le scraping de The Piazza sans écrire de code. Notre plateforme alimentée par l'intelligence artificielle comprend quelles données vous voulez — décrivez-les en langage naturel et l'IA les extrait automatiquement.
How to scrape with AI:
- Décrivez ce dont vous avez besoin: Dites à l'IA quelles données vous souhaitez extraire de The Piazza. Tapez simplement en langage naturel — pas de code ni de sélecteurs.
- L'IA extrait les données: Notre intelligence artificielle navigue sur The Piazza, gère le contenu dynamique et extrait exactement ce que vous avez demandé.
- Obtenez vos données: Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Why use AI for scraping:
- Contournement fluide des anti-bots: Automatio gère automatiquement les challenges Cloudflare et l'empreinte du navigateur, garantissant un accès ininterrompu aux données de tarification.
- Outil de sélection visuelle: Mappez facilement les champs de données à partir de tableaux de résidences complexes à l'aide d'une interface pointer-cliquer, sans écrire de CSS ou de XPath personnalisés.
- Planification automatisée: Configurez le scraper pour qu'il s'exécute quotidiennement afin de capturer les fluctuations de prix à haute fréquence et les nouvelles sorties d'unités sans intervention manuelle.
- Exécution de scripts dynamiques: Affiche parfaitement le contenu basé sur React, vous permettant de scraper des données à partir d'éléments interactifs que les scrapers traditionnels ignorent.
- Intégration de données sans code: Synchronisez vos données immobilières extraites directement vers Google Sheets ou des CRM via des Webhooks pour une analyse immédiate du marché.
Scrapers Web No-Code pour The Piazza
Alternatives pointer-cliquer au scraping alimenté par l'IA
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper The Piazza sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
Défis Courants
Courbe d'apprentissage
Comprendre les sélecteurs et la logique d'extraction prend du temps
Les sélecteurs cassent
Les modifications du site web peuvent casser tout le workflow
Problèmes de contenu dynamique
Les sites riches en JavaScript nécessitent des solutions complexes
Limitations des CAPTCHAs
La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
Blocage d'IP
Le scraping agressif peut entraîner le blocage de votre IP
Scrapers Web No-Code pour The Piazza
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper The Piazza sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
- Installer l'extension de navigateur ou s'inscrire sur la plateforme
- Naviguer vers le site web cible et ouvrir l'outil
- Sélectionner en point-and-click les éléments de données à extraire
- Configurer les sélecteurs CSS pour chaque champ de données
- Configurer les règles de pagination pour scraper plusieurs pages
- Gérer les CAPTCHAs (nécessite souvent une résolution manuelle)
- Configurer la planification pour les exécutions automatiques
- Exporter les données en CSV, JSON ou se connecter via API
Défis Courants
- Courbe d'apprentissage: Comprendre les sélecteurs et la logique d'extraction prend du temps
- Les sélecteurs cassent: Les modifications du site web peuvent casser tout le workflow
- Problèmes de contenu dynamique: Les sites riches en JavaScript nécessitent des solutions complexes
- Limitations des CAPTCHAs: La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
- Blocage d'IP: Le scraping agressif peut entraîner le blocage de votre IP
Exemples de Code
import requests
from bs4 import BeautifulSoup
# Note : Cette requête directe échouera probablement à cause de Cloudflare
# Une solution de proxy ou de contournement comme cloudscraper est recommandée
url = 'https://www.livepiazza.com/residences'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36',
'Accept-Language': 'fr-FR,fr;q=0.9'
}
def fetch_piazza():
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# Exemple de sélecteur pour les cartes de résidence
for card in soup.select('.residence-card'):
name = card.select_one('.residence-name').text.strip()
price = card.select_one('.price-value').text.strip()
print(f'Community: {name} | Price: {price}')
else:
print(f'Bloqué par Anti-Bot : Statut {response.status_code}')
except Exception as e:
print(f'Erreur : {e}')
fetch_piazza()Quand Utiliser
Idéal pour les pages HTML statiques avec peu de JavaScript. Parfait pour les blogs, sites d'actualités et pages e-commerce simples.
Avantages
- ●Exécution la plus rapide (sans surcharge navigateur)
- ●Consommation de ressources minimale
- ●Facile à paralléliser avec asyncio
- ●Excellent pour les APIs et pages statiques
Limitations
- ●Ne peut pas exécuter JavaScript
- ●Échoue sur les SPAs et contenu dynamique
- ●Peut avoir des difficultés avec les systèmes anti-bot complexes
Comment Scraper The Piazza avec du Code
Python + Requests
import requests
from bs4 import BeautifulSoup
# Note : Cette requête directe échouera probablement à cause de Cloudflare
# Une solution de proxy ou de contournement comme cloudscraper est recommandée
url = 'https://www.livepiazza.com/residences'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36',
'Accept-Language': 'fr-FR,fr;q=0.9'
}
def fetch_piazza():
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# Exemple de sélecteur pour les cartes de résidence
for card in soup.select('.residence-card'):
name = card.select_one('.residence-name').text.strip()
price = card.select_one('.price-value').text.strip()
print(f'Community: {name} | Price: {price}')
else:
print(f'Bloqué par Anti-Bot : Statut {response.status_code}')
except Exception as e:
print(f'Erreur : {e}')
fetch_piazza()Python + Playwright
import asyncio
from playwright.async_api import async_playwright
async def scrape_live_piazza():
async with async_playwright() as p:
# Lancement avec un user agent spécifique pour imiter un vrai navigateur
browser = await p.chromium.launch(headless=True)
context = await browser.new_context(user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36')
page = await context.new_page()
await page.goto('https://www.livepiazza.com/alta/')
# Attendre que le tableau dynamique des unités charge
await page.wait_for_selector('.unit-row', timeout=15000)
units = await page.query_selector_all('.unit-row')
for unit in units:
unit_id = await (await unit.query_selector('.unit-id')).inner_text()
rent = await (await unit.query_selector('.unit-rent')).inner_text()
print(f'Unit: {unit_id.strip()} | Rent: {rent.strip()}')
await browser.close()
asyncio.run(scrape_live_piazza())Python + Scrapy
import scrapy
class PiazzaSpider(scrapy.Spider):
name = 'piazza_spider'
start_urls = ['https://www.livepiazza.com/communities']
def parse(self, response):
# Scrapy nécessite un middleware de rendu JS (comme Scrapy-Playwright) pour ce site
for building in response.css('.building-section'):
yield {
'building_name': building.css('h3.name::text').get(),
'link': building.css('a.explore-btn::attr(href)').get(),
'starting_price': building.css('.starting-from::text').get()
}
# Exemple de suivi de pagination
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
puppeteer.use(StealthPlugin());
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto('https://www.livepiazza.com/montesino', { waitUntil: 'networkidle2' });
// Attendre que le conteneur des résidences soit rendu
await page.waitForSelector('.residences-container');
const apartmentData = await page.evaluate(() => {
const rows = Array.from(document.querySelectorAll('.apartment-listing'));
return rows.map(row => ({
type: row.querySelector('.plan-type').innerText,
sqft: row.querySelector('.sqft').innerText,
available: row.querySelector('.availability').innerText
}));
});
console.log(apartmentData);
await browser.close();
})();Que Pouvez-Vous Faire Avec Les Données de The Piazza
Explorez les applications pratiques et les insights des données de The Piazza.
Indice des loyers en temps réel
Créez un tableau de bord en direct suivant le loyer moyen par pied carré pour les appartements de luxe à Northern Liberties.
Comment implémenter :
- 1Extraire les prix quotidiens pour tous les studios, 1BR et 2BR.
- 2Normaliser les prix par pied carré pour créer une métrique PPSF.
- 3Visualiser la ligne de tendance sur une période de 90 jours.
Utilisez Automatio pour extraire des données de The Piazza et créer ces applications sans écrire de code.
Que Pouvez-Vous Faire Avec Les Données de The Piazza
- Indice des loyers en temps réel
Créez un tableau de bord en direct suivant le loyer moyen par pied carré pour les appartements de luxe à Northern Liberties.
- Extraire les prix quotidiens pour tous les studios, 1BR et 2BR.
- Normaliser les prix par pied carré pour créer une métrique PPSF.
- Visualiser la ligne de tendance sur une période de 90 jours.
- Analyse des stratégies de concession
Analysez comment les gestionnaires immobiliers utilisent les incitations de type 'loyer offert' pour remplir les logements vacants dans des bâtiments spécifiques.
- Scraper le champ 'Promotions' pour chaque unité listée.
- Croiser les promotions avec le nombre de jours depuis la mise en ligne de l'unité.
- Déterminer le 'point de bascule' où les promoteurs augmentent les incitations.
- Études de faisabilité d'investissement
Utilisez les données pour justifier ou rejeter de nouveaux développements de luxe dans la zone immédiate en fonction de l'offre et de la demande actuelles.
- Agréger le nombre total d'unités disponibles pour Alta, Navona et Montesino.
- Segmenter la disponibilité par 'date d'emménagement' pour prévoir l'absorption de l'offre.
- Comparer les prix de Piazza aux moyennes de luxe à l'échelle de la ville.
- Lead Gen pour les déménageurs
Identifiez les fenêtres d'emménagement à fort volume pour cibler le marketing des services locaux de déménagement et de nettoyage.
- Filtrer les annonces scrapées pour 'Disponible dès maintenant' ou des dates spécifiques à venir.
- Cibler les bâtiments avec la plus forte disponibilité prochaine.
- Aligner les dépenses publicitaires avec les périodes de rotation prévues les plus élevées.
Optimisez votre flux de travail avec l'Automatisation IA
Automatio combine la puissance des agents IA, de l'automatisation web et des integrations intelligentes pour vous aider a accomplir plus en moins de temps.
Conseils Pro pour Scraper The Piazza
Conseils d'experts pour extraire avec succès les données de The Piazza.
Utiliser des proxies à Philadelphie
L'utilisation de proxies résidentiels situés dans la région de Philadelphie réduit le risque d'être signalé comme un bot suspect par les filtres régionaux.
Attendre l'hydratation du tableau
Implémentez une condition « wait for element » pour la liste des résidences afin de vous assurer que l'application React est complètement hydratée avant l'extraction des données.
Surveiller les logs réseau
Identifiez les points de terminaison JSON internes utilisés par le logiciel de gestion immobilière du site pour extraire des données structurées plus efficacement.
Analyser le texte des promotions
Extrayez toujours le texte des champs « Specials » ou « Promotions » pour calculer avec précision le loyer net après remises.
Scroller pour l'extraction des médias
Configurez votre scraper pour qu'il défile jusqu'au bas des pages d'annonces afin de déclencher le chargement de toutes les images de plans d'étage et des photos d'unités.
Effectuer une rotation des User Agents
Alternez entre différentes empreintes de navigateurs de bureau modernes pour éviter la détection basée sur des signatures de headers identiques répétées.
Témoignages
Ce Que Disent Nos Utilisateurs
Rejoignez des milliers d'utilisateurs satisfaits qui ont transforme leur flux de travail
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Associés Web Scraping
How to Scrape Century 21 Property Listings
How to Scrape Homes.com: Real Estate Data Extraction Guide
How to Scrape Century 21: A Technical Real Estate Guide
How to Scrape HotPads: A Complete Guide to Extracting Rental Data
How to Scrape Sacramento Delta Property Management
How to Scrape Locations Hawaii | Locations Hawaii Web Scraper
How to Scrape RE/MAX (remax.com) Real Estate Listings

How to Scrape Apartments Near Me | Real Estate Data Scraper
Questions Fréquentes sur The Piazza
Trouvez des réponses aux questions courantes sur The Piazza