كيفية كشط WebElements: دليل بيانات الجدول الدوري
استخرج بيانات العناصر الكيميائية الدقيقة من WebElements. قم بكشط الأوزان الذرية والخصائص الفيزيائية وتاريخ الاكتشاف للبحوث وتطبيقات AI.
حول WebElements
اكتشف ما يقدمه WebElements وما هي البيانات القيمة التي يمكن استخراجها.
يعد WebElements جدولاً دورياً رائداً عبر الإنترنت يشرف عليه مارك وينتر في جامعة شيفيلد. أُطلق في عام 1993، وكان أول جدول دوري على شبكة الويب العالمية، وأصبح منذ ذلك الحين مورداً ذا سلطة عالية للطلاب والأكاديميين والكيميائيين المحترفين. يقدم الموقع بيانات عميقة ومنظمة حول كل عنصر كيميائي معروف، بدءاً من الأوزان الذرية القياسية وصولاً إلى التكوينات الإلكترونية المعقدة.
تكمن قيمة كشط WebElements في بياناته العلمية عالية الجودة والمراجعة من قبل الأقران. بالنسبة للمطورين الذين يبنون أدوات تعليمية، أو الباحثين الذين يجرون تحليلاً للاتجاهات عبر الجدول الدوري، أو علماء المواد الذين يدربون نماذج machine learning، يوفر WebElements مصدراً موثوقاً وغنياً تقنياً يصعب تجميعه يدوياً.
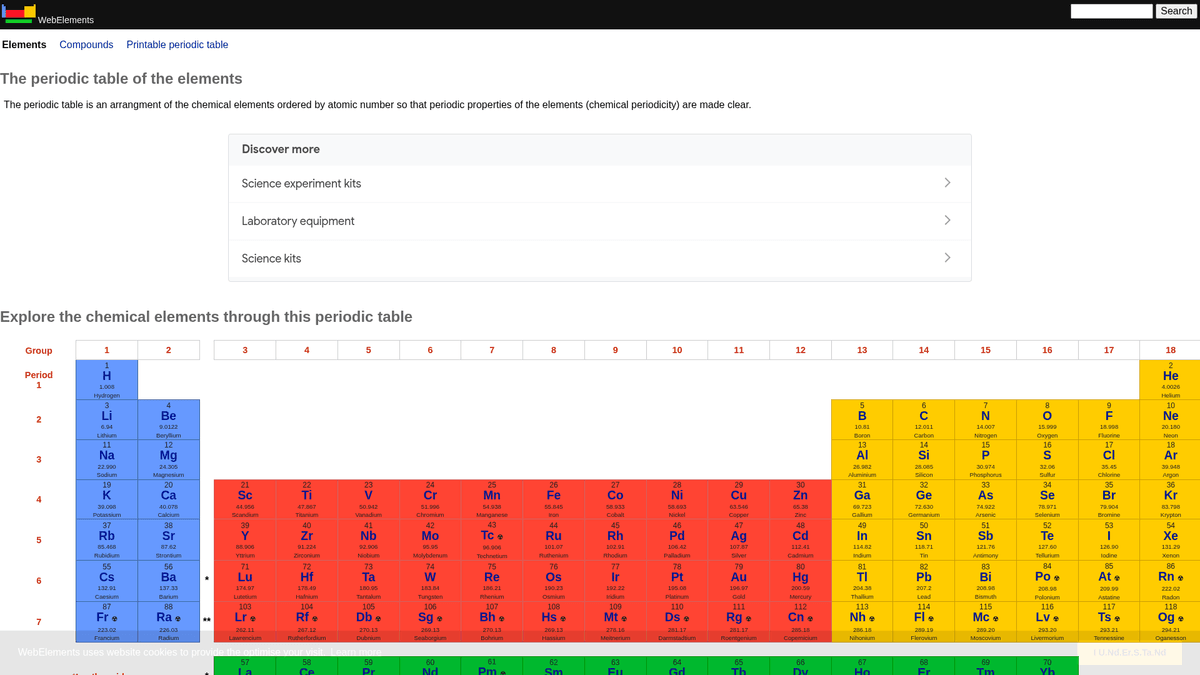
لماذا تجريد WebElements؟
اكتشف القيمة التجارية وحالات الاستخدام لاستخراج البيانات من WebElements.
جمع بيانات علمية عالية الجودة لتطوير الأدوات التعليمية.
تجميع خصائص العناصر لأبحاث علوم المواد ونماذج machine learning.
الملء التلقائي لأنظمة مخزون المختبرات بالمواصفات الكيميائية.
التحليل التاريخي لاكتشافات العناصر والتقدم العلمي.
إنشاء مجموعات بيانات شاملة للخصائص الكيميائية للمنشورات الأكاديمية.
تحديات التجريد
التحديات التقنية التي قد تواجهها عند تجريد WebElements.
البيانات موزعة على صفحات فرعية متعددة لكل عنصر (مثل /history، /compounds).
تخطيطات HTML القديمة القائمة على الجداول تتطلب منطق اختيار دقيق.
الارتباك في اسم النطاق مع فئة 'WebElement' الخاصة بـ Selenium عند البحث عن الدعم.
استخرج بيانات WebElements بالذكاء الاصطناعي
لا حاجة للبرمجة. استخرج البيانات في دقائق مع الأتمتة المدعومة بالذكاء الاصطناعي.
كيف يعمل
صف ما تحتاجه
أخبر الذكاء الاصطناعي بالبيانات التي تريد استخراجها من WebElements. فقط اكتب بلغة طبيعية — لا حاجة لأكواد أو محددات.
الذكاء الاصطناعي يستخرج البيانات
ذكاؤنا الاصطناعي يتصفح WebElements، يتعامل مع المحتوى الديناميكي، ويستخرج بالضبط ما طلبته.
احصل على بياناتك
احصل على بيانات نظيفة ومنظمة جاهزة للتصدير كـ CSV أو JSON أو إرسالها مباشرة إلى تطبيقاتك.
لماذا تستخدم الذكاء الاصطناعي للاستخراج
الذكاء الاصطناعي يجعل استخراج بيانات WebElements سهلاً بدون كتابة أكواد. منصتنا المدعومة بالذكاء الاصطناعي تفهم البيانات التي تريدها — فقط صفها بلغة طبيعية والذكاء الاصطناعي يستخرجها تلقائياً.
How to scrape with AI:
- صف ما تحتاجه: أخبر الذكاء الاصطناعي بالبيانات التي تريد استخراجها من WebElements. فقط اكتب بلغة طبيعية — لا حاجة لأكواد أو محددات.
- الذكاء الاصطناعي يستخرج البيانات: ذكاؤنا الاصطناعي يتصفح WebElements، يتعامل مع المحتوى الديناميكي، ويستخرج بالضبط ما طلبته.
- احصل على بياناتك: احصل على بيانات نظيفة ومنظمة جاهزة للتصدير كـ CSV أو JSON أو إرسالها مباشرة إلى تطبيقاتك.
Why use AI for scraping:
- التنقل بدون كود (No-code) عبر الهياكل العنصرية الهرمية.
- معالجة استخراج الجداول العلمية المعقدة تلقائياً.
- التنفيذ السحابي يسمح باستخراج مجموعة البيانات كاملة دون توقف محلي.
- تصدير سهل إلى CSV/JSON للاستخدام المباشر في أدوات التحليل العلمي.
- المراقبة المجدولة يمكنها اكتشاف التحديثات على بيانات العناصر المؤكدة.
أدوات تجريد الويب بدون كود لـWebElements
بدائل النقر والتأشير للتجريد المدعوم بالذكاء الاصطناعي
يمكن لعدة أدوات بدون كود مثل Browse.ai وOctoparse وAxiom وParseHub مساعدتك في تجريد WebElements بدون كتابة كود. تستخدم هذه الأدوات عادةً واجهات مرئية لتحديد البيانات، على الرغم من أنها قد تواجه صعوبة مع المحتوى الديناميكي المعقد أو إجراءات مكافحة البوتات.
سير العمل النموذجي مع أدوات بدون كود
التحديات الشائعة
منحنى التعلم
فهم المحددات ومنطق الاستخراج يستغرق وقتًا
المحددات تتعطل
تغييرات الموقع يمكن أن تكسر سير العمل بالكامل
مشاكل المحتوى الديناميكي
المواقع الغنية بـ JavaScript تتطلب حلولاً معقدة
قيود CAPTCHA
معظم الأدوات تتطلب تدخلاً يدويًا لـ CAPTCHA
حظر IP
الاستخراج المكثف قد يؤدي إلى حظر عنوان IP الخاص بك
أدوات تجريد الويب بدون كود لـWebElements
يمكن لعدة أدوات بدون كود مثل Browse.ai وOctoparse وAxiom وParseHub مساعدتك في تجريد WebElements بدون كتابة كود. تستخدم هذه الأدوات عادةً واجهات مرئية لتحديد البيانات، على الرغم من أنها قد تواجه صعوبة مع المحتوى الديناميكي المعقد أو إجراءات مكافحة البوتات.
سير العمل النموذجي مع أدوات بدون كود
- تثبيت إضافة المتصفح أو التسجيل في المنصة
- الانتقال إلى الموقع المستهدف وفتح الأداة
- اختيار عناصر البيانات المراد استخراجها بالنقر
- تكوين محددات CSS لكل حقل بيانات
- إعداد قواعد التصفح لاستخراج صفحات متعددة
- التعامل مع CAPTCHA (غالبًا يتطلب حلاً يدويًا)
- تكوين الجدولة للتشغيل التلقائي
- تصدير البيانات إلى CSV أو JSON أو الاتصال عبر API
التحديات الشائعة
- منحنى التعلم: فهم المحددات ومنطق الاستخراج يستغرق وقتًا
- المحددات تتعطل: تغييرات الموقع يمكن أن تكسر سير العمل بالكامل
- مشاكل المحتوى الديناميكي: المواقع الغنية بـ JavaScript تتطلب حلولاً معقدة
- قيود CAPTCHA: معظم الأدوات تتطلب تدخلاً يدويًا لـ CAPTCHA
- حظر IP: الاستخراج المكثف قد يؤدي إلى حظر عنوان IP الخاص بك
أمثلة الكود
import requests
from bs4 import BeautifulSoup
import time
# Target URL for a specific element (e.g., Gold)
url = 'https://www.webelements.com/gold/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
def scrape_element(element_url):
try:
response = requests.get(element_url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Extracting the element name from the H1 tag
name = soup.find('h1').get_text().strip()
# Extracting Atomic Number using table label logic
atomic_number = soup.find('th', string=lambda s: s and 'Atomic number' in s).find_next('td').text.strip()
print(f'Element: {name}, Atomic Number: {atomic_number}')
except Exception as e:
print(f'An error occurred: {e}')
# Following robots.txt recommendations
time.sleep(1)
scrape_element(url)متى تستخدم
الأفضل لصفحات HTML الثابتة مع حد أدنى من JavaScript. مثالي للمدونات ومواقع الأخبار وصفحات المنتجات البسيطة.
المزايا
- ●أسرع تنفيذ (بدون عبء المتصفح)
- ●أقل استهلاك للموارد
- ●سهل التوازي مع asyncio
- ●ممتاز لواجهات API والصفحات الثابتة
القيود
- ●لا يمكنه تنفيذ JavaScript
- ●يفشل في تطبيقات الصفحة الواحدة والمحتوى الديناميكي
- ●قد يواجه صعوبة مع أنظمة مكافحة البوتات المعقدة
كيفية استخراج بيانات WebElements بالكود
Python + Requests
import requests
from bs4 import BeautifulSoup
import time
# Target URL for a specific element (e.g., Gold)
url = 'https://www.webelements.com/gold/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
def scrape_element(element_url):
try:
response = requests.get(element_url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Extracting the element name from the H1 tag
name = soup.find('h1').get_text().strip()
# Extracting Atomic Number using table label logic
atomic_number = soup.find('th', string=lambda s: s and 'Atomic number' in s).find_next('td').text.strip()
print(f'Element: {name}, Atomic Number: {atomic_number}')
except Exception as e:
print(f'An error occurred: {e}')
# Following robots.txt recommendations
time.sleep(1)
scrape_element(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Elements are linked from the main periodic table
page.goto('https://www.webelements.com/iron/')
# Wait for the property table to be present
page.wait_for_selector('table')
element_data = {
'name': page.inner_text('h1'),
'density': page.locator('th:has-text("Density") + td').inner_text().strip()
}
print(element_data)
browser.close()
run()Python + Scrapy
import scrapy
class ElementsSpider(scrapy.Spider):
name = 'elements'
start_urls = ['https://www.webelements.com/']
def parse(self, response):
# Follow every element link in the periodic table
for link in response.css('table a[title]::attr(href)'):
yield response.follow(link, self.parse_element)
def parse_element(self, response):
yield {
'name': response.css('h1::text').get().strip(),
'symbol': response.xpath('//th[contains(text(), "Symbol")]/following-sibling::td/text()').get().strip(),
'atomic_number': response.xpath('//th[contains(text(), "Atomic number")]/following-sibling::td/text()').get().strip(),
}Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.webelements.com/silver/');
const data = await page.evaluate(() => {
const name = document.querySelector('h1').innerText;
const meltingPoint = Array.from(document.querySelectorAll('th'))
.find(el => el.textContent.includes('Melting point'))
?.nextElementSibling.innerText;
return { name, meltingPoint };
});
console.log('Extracted Data:', data);
await browser.close();
})();ماذا يمكنك فعله ببيانات WebElements
استكشف التطبيقات العملية والرؤى من بيانات WebElements.
تدريب AI في علوم المواد
تدريب نماذج machine learning للتنبؤ بخصائص السبائك الجديدة بناءً على سمات العناصر.
كيفية التنفيذ:
- 1استخراج الخصائص الفيزيائية لجميع العناصر المعدنية.
- 2تنظيف وتطبيع القيم مثل الكثافة ونقاط الانصهار.
- 3إدخال البيانات في نماذج التنبؤ أو الـ regression للمواد.
- 4التحقق من التنبؤات مقابل بيانات السبائك التجريبية الموجودة.
استخدم Automatio لاستخراج البيانات من WebElements وبناء هذه التطبيقات بدون كتابة كود.
ماذا يمكنك فعله ببيانات WebElements
- تدريب AI في علوم المواد
تدريب نماذج machine learning للتنبؤ بخصائص السبائك الجديدة بناءً على سمات العناصر.
- استخراج الخصائص الفيزيائية لجميع العناصر المعدنية.
- تنظيف وتطبيع القيم مثل الكثافة ونقاط الانصهار.
- إدخال البيانات في نماذج التنبؤ أو الـ regression للمواد.
- التحقق من التنبؤات مقابل بيانات السبائك التجريبية الموجودة.
- محتوى التطبيقات التعليمية
تزويد الجداول الدورية التفاعلية لطلاب الكيمياء ببيانات مراجعة علمياً.
- كشط الأعداد الذرية والرموز وأوصاف العناصر.
- استخراج السياق التاريخي وتفاصيل الاكتشاف.
- تنظيم البيانات حسب المجموعة والكتلة الدورية.
- دمج البيانات في واجهة مستخدم مع هياكل بلورية مرئية.
- تحليل الاتجاهات الكيميائية
تصور الاتجاهات الدورية مثل طاقة التأين أو نصف القطر الذري عبر الدورات والمجموعات.
- جمع بيانات الخصائص لكل عنصر بالترتيب الرقمي.
- تصنيف العناصر في مجموعاتها الخاصة.
- استخدام مكتبات الرسوم البيانية لتصور الاتجاهات.
- تحديد وتحليل نقاط البيانات الشاذة في كتل معينة.
- إدارة مخزون المختبرات
الملء التلقائي لأنظمة إدارة المواد الكيميائية ببيانات السلامة الفيزيائية والكثافة.
- ربط قائمة المخزون الداخلي بمدخلات WebElements.
- كشط الكثافة، مخاطر التخزين، وبيانات نقطة الانصهار.
- تحديث قاعدة بيانات المختبر المركزية عبر API.
- توليد تحذيرات سلامة آلية للعناصر عالية المخاطر.
عزز سير عملك مع أتمتة الذكاء الاصطناعي
يجمع Automatio بين قوة وكلاء الذكاء الاصطناعي وأتمتة الويب والتكاملات الذكية لمساعدتك على إنجاز المزيد في وقت أقل.
نصائح احترافية لتجريد WebElements
نصائح الخبراء لاستخراج البيانات بنجاح من WebElements.
التزم بـ Crawl-delay
1 المحدد في ملف robots.txt الخاص بالموقع.
استخدم العدد الذري (Atomic Number) كمفتاح أساسي لضمان اتساق قاعدة البيانات.
قم بكشط الصفحات الفرعية مثل 'history' و'compounds' للحصول على مجموعة بيانات كاملة لكل عنصر.
ركز على محددات (selectors) الجداول لأن هيكل الموقع تقليدي للغاية ومستقر.
تحقق من البيانات مقابل معايير IUPAC إذا كانت ستُستخدم في أبحاث نقدية.
قم بتخزين القيم الرقمية مثل الكثافة أو نقاط الانصهار كأرقام عشرية (floats) لتسهيل تحليلها.
الشهادات
ماذا يقول مستخدمونا
انضم إلى الآلاف من المستخدمين الراضين الذين حولوا سير عملهم
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
ذو صلة Web Scraping

How to Scrape GitHub | The Ultimate 2025 Technical Guide

How to Scrape Pollen.com: Local Allergy Data Extraction Guide

How to Scrape Britannica: Educational Data Web Scraper

How to Scrape RethinkEd: A Technical Data Extraction Guide

How to Scrape Wikipedia: The Ultimate Web Scraping Guide

How to Scrape Weather.com: A Guide to Weather Data Extraction

How to Scrape Worldometers for Real-Time Global Statistics

How to Scrape American Museum of Natural History (AMNH)
الأسئلة الشائعة حول WebElements
ابحث عن إجابات للأسئلة الشائعة حول WebElements