Jak scrapovat WebElements: Průvodce daty periodické tabulky
Extrahujte přesná data o chemických prvcích z WebElements. Scrapujte atomové hmotnosti, fyzikální vlastnosti a historii objevů pro výzkum a AI aplikace.
O WebElements
Objevte, co WebElements nabízí a jaká cenná data lze extrahovat.
WebElements je přední online periodická tabulka spravovaná Markem Winterem na University of Sheffield. Byla spuštěna v roce 1993 jako vůbec první periodická tabulka na World Wide Web a od té doby se stala vysoce autoritativním zdrojem pro studenty, akademiky i profesionální chemiky. Stránka nabízí hloubková, strukturovaná data o každém známém chemickém prvku, od standardních atomových hmotností až po složité elektronové konfigurace.
Hodnota scrapování WebElements spočívá v jeho vysoce kvalitních, recenzovaných vědeckých datech. Pro vývojáře budující vzdělávací nástroje, výzkumníky provádějící analýzu trendů v periodické tabulce nebo materiálové vědce trénující machine learning modely, poskytuje WebElements spolehlivý a technicky bohatý zdroj pravdy, který je obtížné shromažďovat manuálně.
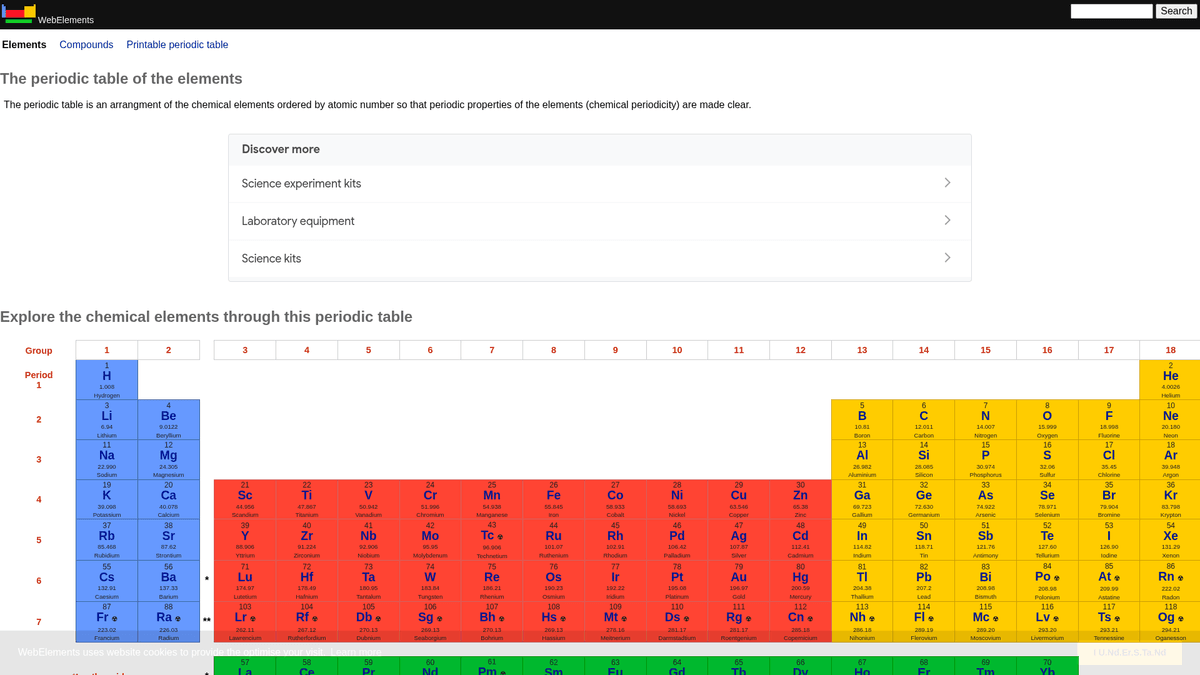
Proč Scrapovat WebElements?
Objevte obchodní hodnotu a případy použití pro extrakci dat z WebElements.
Sběr vysoce kvalitních vědeckých dat pro vývoj vzdělávacích nástrojů.
Agregace vlastností prvků pro výzkum v materiálových vědách a machine learning modely.
Automatické plnění systémů laboratorní evidence chemickými specifikacemi.
Historická analýza objevů prvků a vědeckého pokroku.
Tvorba komplexních datových sad chemických vlastností pro akademické publikace.
Výzvy Scrapování
Technické výzvy, se kterými se můžete setkat při scrapování WebElements.
Data jsou rozptýlena na více podstránkách pro každý prvek (např. /history, /compounds).
Starší HTML rozvržení založená na tabulkách vyžadují přesnou logiku selektorů.
Záměna názvu domény s třídou 'WebElement' v Selenium při vyhledávání podpory.
Scrapujte WebElements pomocí AI
Žádný kód není potřeba. Extrahujte data během minut s automatizací poháněnou AI.
Jak to funguje
Popište, co potřebujete
Řekněte AI, jaká data chcete extrahovat z WebElements. Stačí to napsat přirozeným jazykem — žádný kód ani selektory.
AI extrahuje data
Naše umělá inteligence prochází WebElements, zpracovává dynamický obsah a extrahuje přesně to, co jste požadovali.
Získejte svá data
Získejte čistá, strukturovaná data připravená k exportu jako CSV, JSON nebo k odeslání přímo do vašich aplikací.
Proč používat AI pro scrapování
AI usnadňuje scrapování WebElements bez psaní kódu. Naše platforma poháněná umělou inteligencí rozumí, jaká data chcete — stačí je popsat přirozeným jazykem a AI je automaticky extrahuje.
How to scrape with AI:
- Popište, co potřebujete: Řekněte AI, jaká data chcete extrahovat z WebElements. Stačí to napsat přirozeným jazykem — žádný kód ani selektory.
- AI extrahuje data: Naše umělá inteligence prochází WebElements, zpracovává dynamický obsah a extrahuje přesně to, co jste požadovali.
- Získejte svá data: Získejte čistá, strukturovaná data připravená k exportu jako CSV, JSON nebo k odeslání přímo do vašich aplikací.
Why use AI for scraping:
- No-code navigace skrze hierarchické struktury prvků.
- Automaticky zvládá extrakci složitých vědeckých tabulek.
- Cloudové spouštění umožňuje extrakci celé datové sady bez lokálních prostojů.
- Snadný export do CSV/JSON pro přímé použití v nástrojích pro vědeckou analýzu.
- Plánované monitorování dokáže detekovat aktualizace potvrzených dat o prvcích.
No-code webové scrapery pro WebElements
Alternativy point-and-click k AI scrapingu
Několik no-code nástrojů jako Browse.ai, Octoparse, Axiom a ParseHub vám může pomoci scrapovat WebElements bez psaní kódu. Tyto nástroje obvykle používají vizuální rozhraní pro výběr dat, i když mohou mít problémy se složitým dynamickým obsahem nebo anti-bot opatřeními.
Typický workflow s no-code nástroji
Běžné výzvy
Křivka učení
Pochopení selektorů a logiky extrakce vyžaduje čas
Selektory se rozbijí
Změny webu mohou rozbít celý pracovní postup
Problémy s dynamickým obsahem
Weby s hodně JavaScriptem vyžadují složitá řešení
Omezení CAPTCHA
Většina nástrojů vyžaduje ruční zásah u CAPTCHA
Blokování IP
Agresivní scrapování může vést k zablokování vaší IP
No-code webové scrapery pro WebElements
Několik no-code nástrojů jako Browse.ai, Octoparse, Axiom a ParseHub vám může pomoci scrapovat WebElements bez psaní kódu. Tyto nástroje obvykle používají vizuální rozhraní pro výběr dat, i když mohou mít problémy se složitým dynamickým obsahem nebo anti-bot opatřeními.
Typický workflow s no-code nástroji
- Nainstalujte rozšíření prohlížeče nebo se zaregistrujte na platformě
- Přejděte na cílový web a otevřete nástroj
- Vyberte datové prvky k extrakci kliknutím
- Nakonfigurujte CSS selektory pro každé datové pole
- Nastavte pravidla stránkování pro scrapování více stránek
- Vyřešte CAPTCHA (často vyžaduje ruční řešení)
- Nakonfigurujte plánování automatických spuštění
- Exportujte data do CSV, JSON nebo připojte přes API
Běžné výzvy
- Křivka učení: Pochopení selektorů a logiky extrakce vyžaduje čas
- Selektory se rozbijí: Změny webu mohou rozbít celý pracovní postup
- Problémy s dynamickým obsahem: Weby s hodně JavaScriptem vyžadují složitá řešení
- Omezení CAPTCHA: Většina nástrojů vyžaduje ruční zásah u CAPTCHA
- Blokování IP: Agresivní scrapování může vést k zablokování vaší IP
Příklady kódu
import requests
from bs4 import BeautifulSoup
import time
# Target URL for a specific element (e.g., Gold)
url = 'https://www.webelements.com/gold/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
def scrape_element(element_url):
try:
response = requests.get(element_url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Extracting the element name from the H1 tag
name = soup.find('h1').get_text().strip()
# Extracting Atomic Number using table label logic
atomic_number = soup.find('th', string=lambda s: s and 'Atomic number' in s).find_next('td').text.strip()
print(f'Element: {name}, Atomic Number: {atomic_number}')
except Exception as e:
print(f'An error occurred: {e}')
# Following robots.txt recommendations
time.sleep(1)
scrape_element(url)Kdy použít
Nejlepší pro statické HTML stránky s minimem JavaScriptu. Ideální pro blogy, zpravodajské weby a jednoduché e-commerce produktové stránky.
Výhody
- ●Nejrychlejší provedení (bez režie prohlížeče)
- ●Nejnižší spotřeba zdrojů
- ●Snadná paralelizace s asyncio
- ●Skvělé pro API a statické stránky
Omezení
- ●Nemůže spustit JavaScript
- ●Selhává na SPA a dynamickém obsahu
- ●Může mít problémy se složitými anti-bot systémy
Jak scrapovat WebElements pomocí kódu
Python + Requests
import requests
from bs4 import BeautifulSoup
import time
# Target URL for a specific element (e.g., Gold)
url = 'https://www.webelements.com/gold/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
def scrape_element(element_url):
try:
response = requests.get(element_url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Extracting the element name from the H1 tag
name = soup.find('h1').get_text().strip()
# Extracting Atomic Number using table label logic
atomic_number = soup.find('th', string=lambda s: s and 'Atomic number' in s).find_next('td').text.strip()
print(f'Element: {name}, Atomic Number: {atomic_number}')
except Exception as e:
print(f'An error occurred: {e}')
# Following robots.txt recommendations
time.sleep(1)
scrape_element(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Elements are linked from the main periodic table
page.goto('https://www.webelements.com/iron/')
# Wait for the property table to be present
page.wait_for_selector('table')
element_data = {
'name': page.inner_text('h1'),
'density': page.locator('th:has-text("Density") + td').inner_text().strip()
}
print(element_data)
browser.close()
run()Python + Scrapy
import scrapy
class ElementsSpider(scrapy.Spider):
name = 'elements'
start_urls = ['https://www.webelements.com/']
def parse(self, response):
# Follow every element link in the periodic table
for link in response.css('table a[title]::attr(href)'):
yield response.follow(link, self.parse_element)
def parse_element(self, response):
yield {
'name': response.css('h1::text').get().strip(),
'symbol': response.xpath('//th[contains(text(), "Symbol")]/following-sibling::td/text()').get().strip(),
'atomic_number': response.xpath('//th[contains(text(), "Atomic number")]/following-sibling::td/text()').get().strip(),
}Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.webelements.com/silver/');
const data = await page.evaluate(() => {
const name = document.querySelector('h1').innerText;
const meltingPoint = Array.from(document.querySelectorAll('th'))
.find(el => el.textContent.includes('Melting point'))
?.nextElementSibling.innerText;
return { name, meltingPoint };
});
console.log('Extracted Data:', data);
await browser.close();
})();Co Můžete Dělat S Daty WebElements
Prozkoumejte praktické aplikace a poznatky z dat WebElements.
Trénování AI v materiálových vědách
Trénování machine learning modelů pro předpovídání vlastností nových slitin na základě atributů prvků.
Jak implementovat:
- 1Extrahujte fyzikální vlastnosti všech kovových prvků.
- 2Vyčistěte a normalizujte hodnoty jako hustota a body tání.
- 3Vložte data do regresních nebo prediktivních materiálových modelů.
- 4Ověřte predikce proti stávajícím experimentálním datům o slitinách.
Použijte Automatio k extrakci dat z WebElements a vytvoření těchto aplikací bez psaní kódu.
Co Můžete Dělat S Daty WebElements
- Trénování AI v materiálových vědách
Trénování machine learning modelů pro předpovídání vlastností nových slitin na základě atributů prvků.
- Extrahujte fyzikální vlastnosti všech kovových prvků.
- Vyčistěte a normalizujte hodnoty jako hustota a body tání.
- Vložte data do regresních nebo prediktivních materiálových modelů.
- Ověřte predikce proti stávajícím experimentálním datům o slitinách.
- Obsah pro vzdělávací aplikace
Plnění interaktivních periodických tabulek pro studenty chemie recenzovanými daty.
- Scrapujte atomová čísla, symboly a popisy prvků.
- Extrahujte historický kontext a detaily o objevech.
- Uspořádejte data podle periodické skupiny a bloku.
- Integrujte do uživatelského rozhraní s vizuálními krystalovými strukturami.
- Analýza chemických trendů
Vizualizace periodických trendů, jako je ionizační energie nebo atomový poloměr, napříč periodami a skupinami.
- Shromážděte data o vlastnostech každého prvku v číselném pořadí.
- Zařaďte prvky do jejich příslušných skupin.
- Použijte grafické knihovny pro vizualizaci trendů.
- Identifikujte a analyzujte anomální datové body v konkrétních blocích.
- Správa laboratorních zásob
Automatické plnění systémů pro správu chemikálií daty o fyzikální bezpečnosti a hustotě.
- Namapujte interní seznam zásob na záznamy ve WebElements.
- Scrapujte údaje o hustotě, rizicích skladování a bodech tání.
- Aktualizujte centralizovanou laboratorní databázi přes API.
- Generujte automatická bezpečnostní varování pro vysoce rizikové prvky.
Zrychlete svuj workflow s AI automatizaci
Automatio kombinuje silu AI agentu, webove automatizace a chytrych integraci, aby vam pomohl dosahnout vice za kratsi cas.
Profesionální Tipy Pro Scrapování WebElements
Odborné rady pro úspěšnou extrakci dat z WebElements.
Respektujte Crawl-delay
1 specifikovaný v souboru robots.txt webu.
Pro konzistenci databáze použijte jako primární klíč Atomové číslo.
Pro získání kompletní datové sady každého prvku procházejte i podstránky 'history' a 'compounds'.
Zaměřte se na selektory založené na tabulkách, protože struktura webu je velmi tradiční a stabilní.
Pokud data používáte pro kritický výzkum, ověřte je podle standardů IUPAC.
Číselné hodnoty, jako je hustota nebo body tání, ukládejte jako floats pro snazší analýzu.
Reference
Co rikaji nasi uzivatele
Pridejte se k tisicum spokojenych uzivatelu, kteri transformovali svuj workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Souvisejici Web Scraping

How to Scrape GitHub | The Ultimate 2025 Technical Guide

How to Scrape Pollen.com: Local Allergy Data Extraction Guide

How to Scrape Britannica: Educational Data Web Scraper

How to Scrape RethinkEd: A Technical Data Extraction Guide

How to Scrape Wikipedia: The Ultimate Web Scraping Guide

How to Scrape Weather.com: A Guide to Weather Data Extraction

How to Scrape Worldometers for Real-Time Global Statistics

How to Scrape American Museum of Natural History (AMNH)
Casto kladene dotazy o WebElements
Najdete odpovedi na bezne otazky o WebElements