Sådan scraper du WebElements: Guide til data fra det periodiske system
Udtræk præcise kemiske grundstofdata fra WebElements. Scrape atomvægte, fysiske egenskaber og opdagelseshistorik til forskning og AI-applikationer.
Om WebElements
Opdag hvad WebElements tilbyder og hvilke værdifulde data der kan udtrækkes.
WebElements er et førende online periodisk system vedligeholdt af Mark Winter ved University of Sheffield. Siden blev lanceret i 1993 og var det første periodiske system på World Wide Web, og det er siden blevet en autoritativ ressource for studerende, akademikere og professionelle kemikere. Siden tilbyder dybdegående, struktureret data om alle kendte kemiske grundstoffer, fra standard atomvægte til komplekse elektronkonfigurationer.
Værdien af at scrape WebElements ligger i de videnskabelige data af høj kvalitet, som er peer-reviewed. For udviklere, der bygger uddannelsesværktøjer, forskere, der udfører trendanalyser på tværs af det periodiske system, eller materialeforskere, der træner machine learning-modeller, udgør WebElements en pålidelig og teknisk rig kilde til sandhed, som er svær at aggregere manuelt.
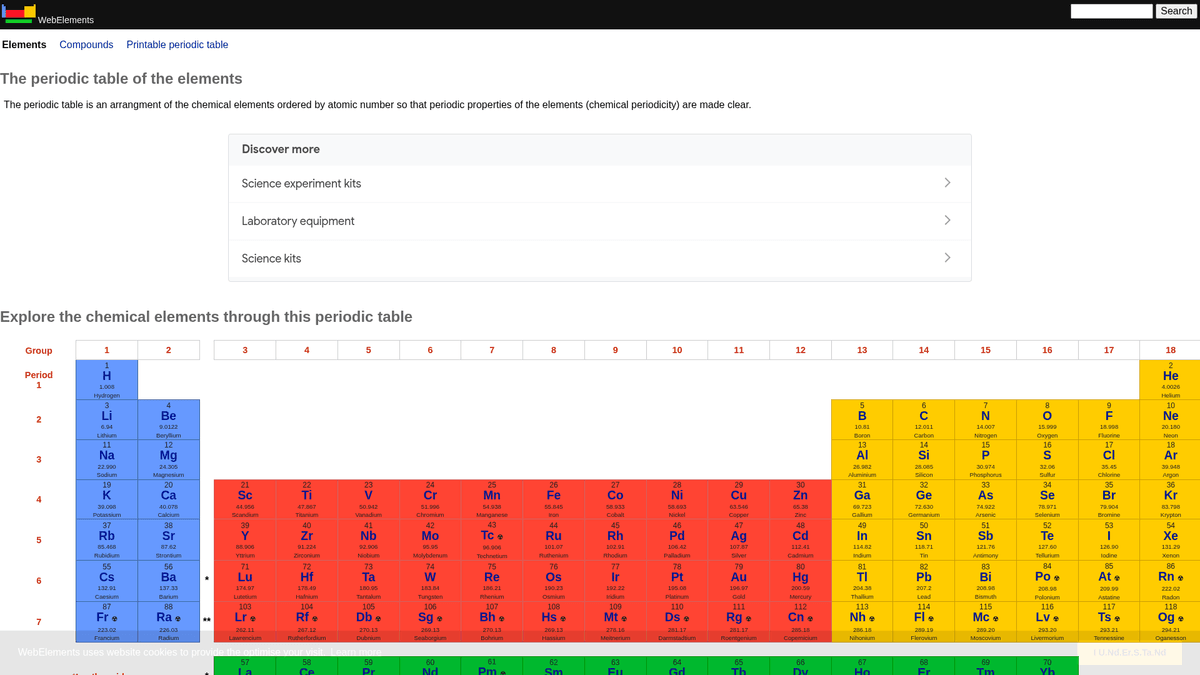
Hvorfor Skrabe WebElements?
Opdag forretningsværdien og brugsscenarier for dataudtrækning fra WebElements.
Indsamling af videnskabelige data af høj kvalitet til udvikling af uddannelsesværktøjer.
Aggregering af grundstofegenskaber til forskning i materialevidenskab og machine learning-modeller.
Automatiseret udfyldelse af laboratorie-lagersystemer med kemiske specifikationer.
Historisk analyse af grundstofopdagelser og videnskabelige fremskridt.
Oprettelse af omfattende datasæt med kemiske egenskaber til akademiske publikationer.
Skrabningsudfordringer
Tekniske udfordringer du kan støde på når du skraber WebElements.
Data er spredt over flere undersider pr. grundstof (f.eks. /history, /compounds).
Ældre tabelbaserede HTML-layouts kræver præcis selektionslogik.
Forvirring omkring domænenavnet med Seleniums 'WebElement'-klasse, når der søges efter support.
Skrab WebElements med AI
Ingen kode nødvendig. Udtræk data på minutter med AI-drevet automatisering.
Sådan fungerer det
Beskriv hvad du har brug for
Fortæl AI'en hvilke data du vil udtrække fra WebElements. Skriv det bare på almindeligt sprog — ingen kode eller selektorer nødvendige.
AI udtrækker dataene
Vores kunstige intelligens navigerer WebElements, håndterer dynamisk indhold og udtrækker præcis det du bad om.
Få dine data
Modtag rene, strukturerede data klar til eksport som CSV, JSON eller send direkte til dine apps og workflows.
Hvorfor bruge AI til skrabning
AI gør det nemt at skrabe WebElements uden at skrive kode. Vores AI-drevne platform bruger kunstig intelligens til at forstå hvilke data du ønsker — beskriv det på almindeligt sprog, og AI udtrækker dem automatisk.
How to scrape with AI:
- Beskriv hvad du har brug for: Fortæl AI'en hvilke data du vil udtrække fra WebElements. Skriv det bare på almindeligt sprog — ingen kode eller selektorer nødvendige.
- AI udtrækker dataene: Vores kunstige intelligens navigerer WebElements, håndterer dynamisk indhold og udtrækker præcis det du bad om.
- Få dine data: Modtag rene, strukturerede data klar til eksport som CSV, JSON eller send direkte til dine apps og workflows.
Why use AI for scraping:
- No-code-navigation gennem hierarkiske grundstofstrukturer.
- Håndterer automatisk udtrækning af komplekse videnskabelige tabeller.
- Cloud-afvikling giver mulighed for udtrækning af fulde datasæt uden lokal nedetid.
- Nem eksport til CSV/JSON til direkte brug i videnskabelige analyseværktøjer.
- Planlagt overvågning kan registrere opdateringer af bekræftede grundstofdata.
No-code webscrapere til WebElements
Point-and-click alternativer til AI-drevet scraping
Flere no-code værktøjer som Browse.ai, Octoparse, Axiom og ParseHub kan hjælpe dig med at scrape WebElements uden at skrive kode. Disse værktøjer bruger typisk visuelle interfaces til at vælge data, selvom de kan have problemer med komplekst dynamisk indhold eller anti-bot foranstaltninger.
Typisk workflow med no-code værktøjer
Almindelige udfordringer
Indlæringskurve
At forstå selektorer og ekstraktionslogik tager tid
Selektorer går i stykker
Webstedsændringer kan ødelægge hele din arbejdsgang
Problemer med dynamisk indhold
JavaScript-tunge sider kræver komplekse løsninger
CAPTCHA-begrænsninger
De fleste værktøjer kræver manuel indgriben for CAPTCHAs
IP-blokering
Aggressiv scraping kan føre til blokering af din IP
No-code webscrapere til WebElements
Flere no-code værktøjer som Browse.ai, Octoparse, Axiom og ParseHub kan hjælpe dig med at scrape WebElements uden at skrive kode. Disse værktøjer bruger typisk visuelle interfaces til at vælge data, selvom de kan have problemer med komplekst dynamisk indhold eller anti-bot foranstaltninger.
Typisk workflow med no-code værktøjer
- Installer browserudvidelse eller tilmeld dig platformen
- Naviger til målwebstedet og åbn værktøjet
- Vælg dataelementer med point-and-click
- Konfigurer CSS-selektorer for hvert datafelt
- Opsæt pagineringsregler til at scrape flere sider
- Håndter CAPTCHAs (kræver ofte manuel løsning)
- Konfigurer planlægning for automatiske kørsler
- Eksporter data til CSV, JSON eller forbind via API
Almindelige udfordringer
- Indlæringskurve: At forstå selektorer og ekstraktionslogik tager tid
- Selektorer går i stykker: Webstedsændringer kan ødelægge hele din arbejdsgang
- Problemer med dynamisk indhold: JavaScript-tunge sider kræver komplekse løsninger
- CAPTCHA-begrænsninger: De fleste værktøjer kræver manuel indgriben for CAPTCHAs
- IP-blokering: Aggressiv scraping kan føre til blokering af din IP
Kodeeksempler
import requests
from bs4 import BeautifulSoup
import time
# Mål-URL for et specifikt grundstof (f.eks. Guld)
url = 'https://www.webelements.com/gold/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
def scrape_element(element_url):
try:
response = requests.get(element_url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Udtrækker grundstofnavnet fra H1-tagget
name = soup.find('h1').get_text().strip()
# Udtrækker atomnummer ved hjælp af tabellabel-logik
atomic_number = soup.find('th', string=lambda s: s and 'Atomic number' in s).find_next('td').text.strip()
print(f'Grundstof: {name}, Atomnummer: {atomic_number}')
except Exception as e:
print(f'Der opstod en fejl: {e}')
# Overholder robots.txt-anbefalinger
time.sleep(1)
scrape_element(url)Hvornår skal det bruges
Bedst til statiske HTML-sider med minimal JavaScript. Ideel til blogs, nyhedssider og simple e-handelsprodukt sider.
Fordele
- ●Hurtigste udførelse (ingen browser overhead)
- ●Laveste ressourceforbrug
- ●Let at parallelisere med asyncio
- ●Fremragende til API'er og statiske sider
Begrænsninger
- ●Kan ikke køre JavaScript
- ●Fejler på SPA'er og dynamisk indhold
- ●Kan have problemer med komplekse anti-bot systemer
Sådan scraper du WebElements med kode
Python + Requests
import requests
from bs4 import BeautifulSoup
import time
# Mål-URL for et specifikt grundstof (f.eks. Guld)
url = 'https://www.webelements.com/gold/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
def scrape_element(element_url):
try:
response = requests.get(element_url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Udtrækker grundstofnavnet fra H1-tagget
name = soup.find('h1').get_text().strip()
# Udtrækker atomnummer ved hjælp af tabellabel-logik
atomic_number = soup.find('th', string=lambda s: s and 'Atomic number' in s).find_next('td').text.strip()
print(f'Grundstof: {name}, Atomnummer: {atomic_number}')
except Exception as e:
print(f'Der opstod en fejl: {e}')
# Overholder robots.txt-anbefalinger
time.sleep(1)
scrape_element(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Grundstoffer er linket fra det primære periodiske system
page.goto('https://www.webelements.com/iron/')
# Vent på at egenskabstabellen er til stede
page.wait_for_selector('table')
element_data = {
'name': page.inner_text('h1'),
'density': page.locator('th:has-text("Density") + td').inner_text().strip()
}
print(element_data)
browser.close()
run()Python + Scrapy
import scrapy
class ElementsSpider(scrapy.Spider):
name = 'elements'
start_urls = ['https://www.webelements.com/']
def parse(self, response):
# Følg hvert link til et grundstof i det periodiske system
for link in response.css('table a[title]::attr(href)'):
yield response.follow(link, self.parse_element)
def parse_element(self, response):
yield {
'name': response.css('h1::text').get().strip(),
'symbol': response.xpath('//th[contains(text(), "Symbol")]/following-sibling::td/text()').get().strip(),
'atomic_number': response.xpath('//th[contains(text(), "Atomic number")]/following-sibling::td/text()').get().strip(),
}Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.webelements.com/silver/');
const data = await page.evaluate(() => {
const name = document.querySelector('h1').innerText;
const meltingPoint = Array.from(document.querySelectorAll('th'))
.find(el => el.textContent.includes('Melting point'))
?.nextElementSibling.innerText;
return { name, meltingPoint };
});
console.log('Ekstraheret data:', data);
await browser.close();
})();Hvad Du Kan Gøre Med WebElements-Data
Udforsk praktiske anvendelser og indsigter fra WebElements-data.
AI-træning til materialevidenskab
Træning af machine learning-modeller til at forudsige egenskaber for nye legeringer baseret på grundstoffernes attributter.
Sådan implementeres:
- 1Udtræk fysiske egenskaber for alle metalliske grundstoffer.
- 2Rens og normaliser værdier som massefylde og smeltepunkter.
- 3Indlæs data i regressions- eller prædiktive materialemodeller.
- 4Verificer forudsigelser mod eksisterende eksperimentelle legeringsdata.
Brug Automatio til at udtrække data fra WebElements og bygge disse applikationer uden at skrive kode.
Hvad Du Kan Gøre Med WebElements-Data
- AI-træning til materialevidenskab
Træning af machine learning-modeller til at forudsige egenskaber for nye legeringer baseret på grundstoffernes attributter.
- Udtræk fysiske egenskaber for alle metalliske grundstoffer.
- Rens og normaliser værdier som massefylde og smeltepunkter.
- Indlæs data i regressions- eller prædiktive materialemodeller.
- Verificer forudsigelser mod eksisterende eksperimentelle legeringsdata.
- Indhold til uddannelsesapps
Udfyldelse af interaktive periodiske systemer til kemistuderende med peer-reviewed data.
- Scrape atomnumre, symboler og grundstofbeskrivelser.
- Udtræk historisk kontekst og detaljer om opdagelser.
- Organiser data efter periodisk gruppe og blok.
- Integrer i en brugerflade med visuelle krystalstrukturer.
- Kemisk trendanalyse
Visualisering af periodiske tendenser som ioniseringsenergi eller atomradius på tværs af perioder og grupper.
- Indsaml egenskabsdata for hvert grundstof i numerisk rækkefølge.
- Kategoriser grundstoffer i deres respektive grupper.
- Brug grafbiblioteker til at visualisere tendenser.
- Identificer og analyser anomale datapunkter i specifikke blokke.
- Lagerstyring i laboratorier
Automatisk udfyldelse af kemiske styringssystemer med data om fysisk sikkerhed og massefylde.
- Forbind intern lagerliste med WebElements-indgange.
- Scrape massefylde, opbevaringsrisici og smeltepunktsdata.
- Opdater den centraliserede laboratoriedatabase via API.
- Generer automatiserede sikkerhedsadvarsler for højrisikogrundstoffer.
Supercharg din arbejdsgang med AI-automatisering
Automatio kombinerer kraften fra AI-agenter, webautomatisering og smarte integrationer for at hjælpe dig med at udrette mere på kortere tid.
Professionelle Tips til Skrabning af WebElements
Ekspertråd til succesfuld dataudtrækning fra WebElements.
Overhold Crawl-delay
1, som er angivet i sidens robots.txt-fil.
Brug atomnummer som din primærnøgle for at sikre databasekonsistens.
Crawl undersiderne 'history' og 'compounds' for at få et komplet datasæt pr. grundstof.
Fokuser på tabelbaserede selectorer, da sidestrukturen er meget traditionel og stabil.
Verificer data mod IUPAC-standarder, hvis de bruges til kritisk forskning.
Gem numeriske værdier som massefylde eller smeltepunkter som floats for nemmere analyse.
Anmeldelser
Hvad vores brugere siger
Slut dig til tusindvis af tilfredse brugere, der har transformeret deres arbejdsgang
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relateret Web Scraping

How to Scrape GitHub | The Ultimate 2025 Technical Guide

How to Scrape Pollen.com: Local Allergy Data Extraction Guide

How to Scrape Britannica: Educational Data Web Scraper

How to Scrape RethinkEd: A Technical Data Extraction Guide

How to Scrape Wikipedia: The Ultimate Web Scraping Guide

How to Scrape Weather.com: A Guide to Weather Data Extraction

How to Scrape Worldometers for Real-Time Global Statistics

How to Scrape American Museum of Natural History (AMNH)
Ofte stillede spørgsmål om WebElements
Find svar på almindelige spørgsmål om WebElements