BetaList Scraping-Leitfaden | So extrahieren Sie Startup-Daten
Erfahren Sie, wie Sie BetaList scrapen, um Startup-Leads, Gründerdaten und Tech-Trends zu extrahieren. Meistern Sie die Umgehung von Cloudflare und dynamischen...
Anti-Bot-Schutz erkannt
- Cloudflare
- Enterprise-WAF und Bot-Management. Nutzt JavaScript-Challenges, CAPTCHAs und Verhaltensanalyse. Erfordert Browser-Automatisierung mit Stealth-Einstellungen.
- Rate Limiting
- Begrenzt Anfragen pro IP/Sitzung über Zeit. Kann mit rotierenden Proxys, Anfrageverzögerungen und verteiltem Scraping umgangen werden.
- IP-Blockierung
- Blockiert bekannte Rechenzentrums-IPs und markierte Adressen. Erfordert Residential- oder Mobile-Proxys zur effektiven Umgehung.
- Browser-Fingerprinting
- Identifiziert Bots anhand von Browser-Eigenschaften: Canvas, WebGL, Schriftarten, Plugins. Erfordert Spoofing oder echte Browser-Profile.
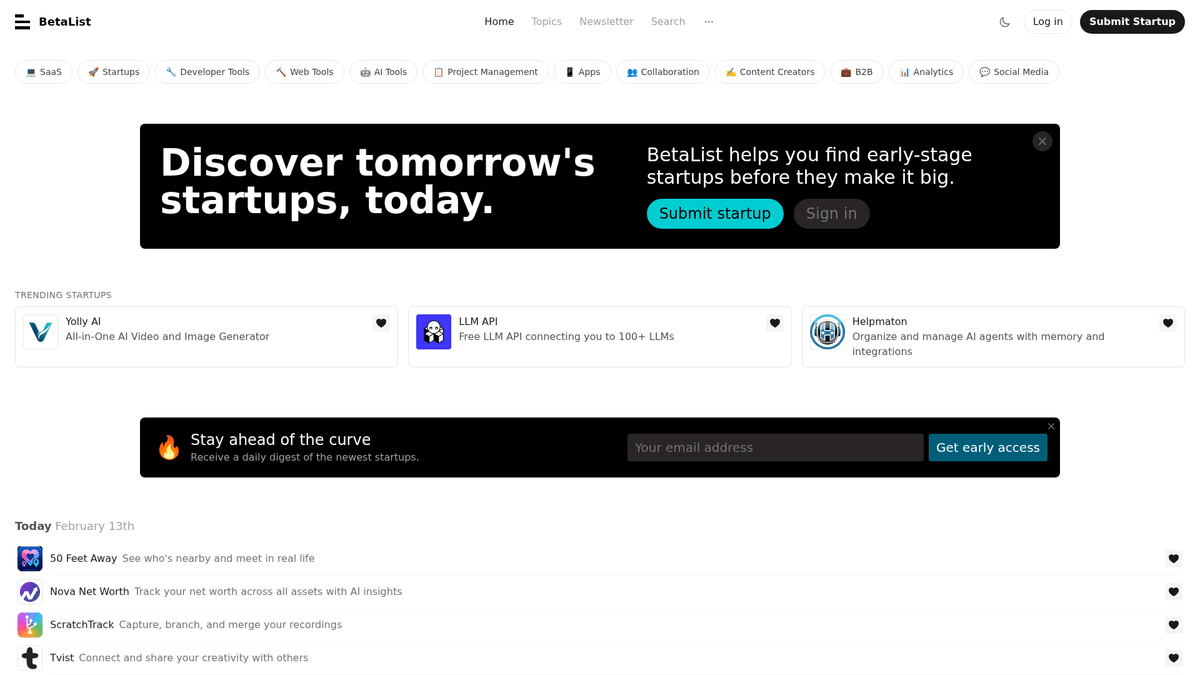
Über BetaList
Entdecken Sie, was BetaList bietet und welche wertvollen Daten extrahiert werden können.
Die führende Plattform zur Startup-Entdeckung
BetaList ist eine weithin anerkannte Entdeckungsplattform, die sich frühen Internet-Startups widmet. Sie wurde von Marc Köhlbrugge gegründet und dient Gründern als Launchpad, um mit Early Adopters in Kontakt zu treten, Feedback zu sammeln und erste Traktion aufzubauen, bevor sie in Mainstream-Märkte wie Product Hunt oder den App Store eintreten.
Datenreiche Startup-Profile
Die Plattform bietet ein umfangreiches Verzeichnis von Einträgen aus Sektoren wie SaaS, Artificial Intelligence, Fintech und E-Commerce. Jeder Eintrag enthält reichhaltige Metadaten, einschließlich Startup-Slogans, detaillierter Produktbeschreibungen, hochauflösender Screenshots, Gründerprofile und Social-Media-Links. Diese Daten bieten eine Momentaufnahme der neuesten Innovationen im Tech-Ökosystem.
Strategischer Wert für das Web Scraping
Für Forscher und Unternehmen ist das Scraping von BetaList unerlässlich, um aufkommende Trends zu identifizieren und hochwertige B2B-Leads zu gewinnen. Investoren nutzen die Plattform, um Startups mit hohem Potenzial in ihrer Frühphase zu entdecken, während Dienstleister (Agenturen, Entwickler und Marketer) sie nutzen, um Gründer anzusprechen, die aktiv nach Wachstums- und Support-Tools suchen.
Warum BetaList Scrapen?
Entdecken Sie den Geschäftswert und die Anwendungsfälle für die Datenextraktion von BetaList.
B2B Sales Lead-Generierung
BetaList erfasst Startups in ihrer frühesten Phase und ist damit eine ideale Quelle für Agenturen und Dienstleister, um neue Unternehmen zu finden, die Unterstützung in den Bereichen Marketing, Recht oder Entwicklung benötigen.
Venture Capital Deal Flow
Investoren und VCs nutzen BetaList-Daten, um aufstrebende Tech-Unternehmen zu entdecken, bevor sie auf größeren Plattformen wie Product Hunt oder Crunchbase allgemeine Bekanntheit erlangen.
Markttrend-Analyse
Durch das Scrapen von Kategorie-Tags und Einreichungsdaten können Forscher identifizieren, welche Tech-Nischen, wie Generative AI oder Web3, aktuell die höchste unternehmerische Aktivität aufweisen.
Wettbewerbsanalyse
SaaS-Unternehmen können neue Marktteilnehmer in ihrer spezifischen Nische überwachen, um innovative Features und die Marktpositionierung potenzieller Wettbewerber im Auge zu behalten.
Gründer-Networking und Outreach
Das Scrapen von Gründernamen und deren Twitter-Handles ermöglicht es Recruitern und Beratern, direkt Kontakt zu Unternehmern aufzunehmen, die aktiv neue Produkte entwickeln und launchen.
Scraping-Herausforderungen
Technische Herausforderungen beim Scrapen von BetaList.
Cloudflare Bot-Schutz
BetaList nutzt Cloudflare zum Schutz seines Verzeichnisses, was Standard-Automatisierungsskripte oft blockiert und ein ausgefeiltes Header-Management oder browserbasierte Tools erfordert.
Infinite Scroll Laden
Die Startup-Liste nutzt dynamisches Laden via Infinite Scroll. Das bedeutet, dass die Daten nicht im initialen HTML vorhanden sind und ein Scraper erforderlich ist, der Benutzerinteraktionen simulieren und JavaScript ausführen kann.
Dynamische DOM-Struktur
Die Website verwendet moderne Frontend-Frameworks, bei denen Elemente dynamisch injiziert werden. Der Scraper muss warten, bis spezifische Selektoren erscheinen, bevor er versucht, Daten zu extrahieren.
Aggressives Rate Limiting
Das schnelle Senden von Anfragen an Startup-Detailseiten kann temporäre IP-Sperren auslösen, weshalb zufällige Verzögerungen und eine hochwertige Proxy-Rotation unerlässlich sind.
Scrape BetaList mit KI
Kein Code erforderlich. Extrahiere Daten in Minuten mit KI-gestützter Automatisierung.
So funktioniert's
Beschreibe, was du brauchst
Sag der KI, welche Daten du von BetaList extrahieren möchtest. Tippe es einfach in natürlicher Sprache ein — kein Code oder Selektoren nötig.
KI extrahiert die Daten
Unsere künstliche Intelligenz navigiert BetaList, verarbeitet dynamische Inhalte und extrahiert genau das, was du angefordert hast.
Erhalte deine Daten
Erhalte saubere, strukturierte Daten, bereit zum Export als CSV, JSON oder zum direkten Senden an deine Apps und Workflows.
Warum KI zum Scraping nutzen
KI macht es einfach, BetaList zu scrapen, ohne Code zu schreiben. Unsere KI-gestützte Plattform nutzt künstliche Intelligenz, um zu verstehen, welche Daten du möchtest — beschreibe es einfach in natürlicher Sprache und die KI extrahiert sie automatisch.
How to scrape with AI:
- Beschreibe, was du brauchst: Sag der KI, welche Daten du von BetaList extrahieren möchtest. Tippe es einfach in natürlicher Sprache ein — kein Code oder Selektoren nötig.
- KI extrahiert die Daten: Unsere künstliche Intelligenz navigiert BetaList, verarbeitet dynamische Inhalte und extrahiert genau das, was du angefordert hast.
- Erhalte deine Daten: Erhalte saubere, strukturierte Daten, bereit zum Export als CSV, JSON oder zum direkten Senden an deine Apps und Workflows.
Why use AI for scraping:
- Visuelles No-Code Scraping: Automatio ermöglicht es Ihnen, einen BetaList-Scraper zu erstellen, indem Sie einfach auf Startup-Karten und Social Links klicken. Das Schreiben von komplexem Python- oder Node.js-Code entfällt.
- Automatisierte Anti-Bot-Handhabung: Die Plattform verwaltet automatisch Browser-Fingerprints und Proxies, um Cloudflare-Challenges zu umgehen, die herkömmliche, selbst programmierte Scraper oft blockieren.
- Geplante Lead-Extraktion: Stellen Sie Ihren Scraper so ein, dass er täglich oder wöchentlich läuft, um neu eingereichte Startups automatisch zu erfassen und sie für den direkten Outreach an Ihr CRM oder Google Sheets zu senden.
- Handhabung von Infinite Scroll: Automatio beherrscht von Haus aus Infinite Scroll und 'Load More'-Aktionen. So stellen Sie sicher, dass Sie tausende historische Startup-Einträge ohne manuelles Eingreifen extrahieren können.
No-Code Web Scraper für BetaList
Point-and-Click-Alternativen zum KI-gestützten Scraping
Verschiedene No-Code-Tools wie Browse.ai, Octoparse, Axiom und ParseHub können Ihnen beim Scrapen von BetaList helfen. Diese Tools verwenden visuelle Oberflächen zur Elementauswahl, haben aber Kompromisse im Vergleich zu KI-gestützten Lösungen.
Typischer Workflow mit No-Code-Tools
Häufige Herausforderungen
Lernkurve
Das Verständnis von Selektoren und Extraktionslogik braucht Zeit
Selektoren brechen
Website-Änderungen können den gesamten Workflow zerstören
Probleme mit dynamischen Inhalten
JavaScript-lastige Seiten erfordern komplexe Workarounds
CAPTCHA-Einschränkungen
Die meisten Tools erfordern manuelle Eingriffe bei CAPTCHAs
IP-Sperrung
Aggressives Scraping kann zur Sperrung Ihrer IP führen
No-Code Web Scraper für BetaList
Verschiedene No-Code-Tools wie Browse.ai, Octoparse, Axiom und ParseHub können Ihnen beim Scrapen von BetaList helfen. Diese Tools verwenden visuelle Oberflächen zur Elementauswahl, haben aber Kompromisse im Vergleich zu KI-gestützten Lösungen.
Typischer Workflow mit No-Code-Tools
- Browser-Erweiterung installieren oder auf der Plattform registrieren
- Zur Zielwebseite navigieren und das Tool öffnen
- Per Point-and-Click die zu extrahierenden Datenelemente auswählen
- CSS-Selektoren für jedes Datenfeld konfigurieren
- Paginierungsregeln zum Scrapen mehrerer Seiten einrichten
- CAPTCHAs lösen (erfordert oft manuelle Eingabe)
- Zeitplanung für automatische Ausführungen konfigurieren
- Daten als CSV, JSON exportieren oder per API verbinden
Häufige Herausforderungen
- Lernkurve: Das Verständnis von Selektoren und Extraktionslogik braucht Zeit
- Selektoren brechen: Website-Änderungen können den gesamten Workflow zerstören
- Probleme mit dynamischen Inhalten: JavaScript-lastige Seiten erfordern komplexe Workarounds
- CAPTCHA-Einschränkungen: Die meisten Tools erfordern manuelle Eingriffe bei CAPTCHAs
- IP-Sperrung: Aggressives Scraping kann zur Sperrung Ihrer IP führen
Code-Beispiele
import requests
from bs4 import BeautifulSoup
# Hinweis: BetaList nutzt Cloudflare; Requests allein kann einen 403 Forbidden Fehler verursachen.
# Normalerweise benötigen Sie einen Bypass oder eine Session mit realistischen Headern.
url = 'https://betalist.com/topics/saas'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Die Container der Startup-Cards anvisieren
for card in soup.select('.startupCard'):
name = card.select_one('.startupCard__name').get_text(strip=True)
tagline = card.select_one('.startupCard__tagline').get_text(strip=True)
print(f'Scraped: {name} - {tagline}')
except Exception as e:
print(f'Anfrage fehlgeschlagen: {e}')Wann verwenden
Am besten für statische HTML-Seiten, bei denen Inhalte serverseitig geladen werden. Der schnellste und einfachste Ansatz, wenn kein JavaScript-Rendering erforderlich ist.
Vorteile
- ●Schnellste Ausführung (kein Browser-Overhead)
- ●Geringster Ressourcenverbrauch
- ●Einfach zu parallelisieren mit asyncio
- ●Ideal für APIs und statische Seiten
Einschränkungen
- ●Kann kein JavaScript ausführen
- ●Scheitert bei SPAs und dynamischen Inhalten
- ●Kann bei komplexen Anti-Bot-Systemen Probleme haben
Wie man BetaList mit Code scrapt
Python + Requests
import requests
from bs4 import BeautifulSoup
# Hinweis: BetaList nutzt Cloudflare; Requests allein kann einen 403 Forbidden Fehler verursachen.
# Normalerweise benötigen Sie einen Bypass oder eine Session mit realistischen Headern.
url = 'https://betalist.com/topics/saas'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Die Container der Startup-Cards anvisieren
for card in soup.select('.startupCard'):
name = card.select_one('.startupCard__name').get_text(strip=True)
tagline = card.select_one('.startupCard__tagline').get_text(strip=True)
print(f'Scraped: {name} - {tagline}')
except Exception as e:
print(f'Anfrage fehlgeschlagen: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
# Einen echten Browser starten, um JavaScript und Anti-Bot-Maßnahmen zu handhaben
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://betalist.com/', wait_until='networkidle')
# Nach unten scrollen, um Lazy Loading auszulösen
page.evaluate('window.scrollTo(0, document.body.scrollHeight)')
page.wait_for_timeout(2000)
# Startup-Daten extrahieren
startups = page.query_selector_all('.startupCard')
for item in startups:
name = item.query_selector('.startupCard__name').inner_text()
tagline = item.query_selector('.startupCard__tagline').inner_text()
print({'startup': name.strip(), 'tagline': tagline.strip()})
browser.close()
run()Python + Scrapy
import scrapy
class BetalistSpider(scrapy.Spider):
name = 'betalist_spider'
start_urls = ['https://betalist.com/topics/ai']
def parse(self, response):
# Scrapy ist schnell, benötigt aber möglicherweise eine Middleware für Cloudflare
for startup in response.css('.startupCard'):
yield {
'name': startup.css('.startupCard__name::text').get().strip(),
'tagline': startup.css('.startupCard__tagline::text').get().strip(),
'link': response.urljoin(startup.css('a::attr(href)').get())
}
# Einfache nummerierte Paginierung handhaben
next_page = response.css('a.pagination__next::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
// Einen echten Browser-Nutzer imitieren, um sofortige Erkennung zu vermeiden
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/110.0.0.0 Safari/537.36');
await page.goto('https://betalist.com/');
// Warten, bis der Inhalt per JS gerendert wurde
await page.waitForSelector('.startupCard');
const results = await page.evaluate(() => {
const cards = Array.from(document.querySelectorAll('.startupCard'));
return cards.map(c => ({
title: c.querySelector('.startupCard__name').innerText.trim(),
description: c.querySelector('.startupCard__tagline').innerText.trim()
}));
});
console.log(results);
await browser.close();
})();Was Sie mit BetaList-Daten machen können
Entdecken Sie praktische Anwendungen und Erkenntnisse aus BetaList-Daten.
Lead-Anreicherung für Sales-Teams
B2B-Agenturen nutzen BetaList-Daten, um eine Pipeline von neu gestarteten Startups aufzubauen, die Marketing- oder Wachstumsdienstleistungen benötigen.
So implementieren Sie es:
- 1Startup-Namen und Gründer-Profil-Links aus dem Bereich 'Today' scrapen.
- 2Gründerprofile besuchen, um Twitter/X-Handles zu extrahieren.
- 3Eine Drittanbieter-API (wie Clay oder Apollo) verwenden, um die E-Mail des Gründers zu finden.
- 4Eine personalisierte E-Mail-Sequenz starten, die sich auf den aktuellen BetaList-Launch bezieht.
Verwenden Sie Automatio, um Daten von BetaList zu extrahieren und diese Anwendungen ohne Code zu erstellen.
Was Sie mit BetaList-Daten machen können
- Lead-Anreicherung für Sales-Teams
B2B-Agenturen nutzen BetaList-Daten, um eine Pipeline von neu gestarteten Startups aufzubauen, die Marketing- oder Wachstumsdienstleistungen benötigen.
- Startup-Namen und Gründer-Profil-Links aus dem Bereich 'Today' scrapen.
- Gründerprofile besuchen, um Twitter/X-Handles zu extrahieren.
- Eine Drittanbieter-API (wie Clay oder Apollo) verwenden, um die E-Mail des Gründers zu finden.
- Eine personalisierte E-Mail-Sequenz starten, die sich auf den aktuellen BetaList-Launch bezieht.
- VC-Investment-Signal-Monitoring
Venture Capitalists verfolgen das Wachstum der Upvotes für neue Startups, um frühzeitig virale Erfolge zu erkennen.
- Wöchentliches Scraping der BetaList-Kategorien, um alle Neueinreichungen zu erfassen.
- Speichern der Heart/Upvote-Anzahl in einer Datenbank.
- Vergleich der Upvote-Zahlen über einen Zeitraum von 7 Tagen, um 'Breakout'-Startups zu identifizieren.
- Zuweisung eines Analysten, um Gründer mit hohen Wachstumsmetriken zu kontaktieren.
- SaaS-Wettbewerbsanalyse
Produktmanager überwachen BetaList, um zu sehen, wann neue Wettbewerber in ihre spezifische Nische eintreten.
- Einträge scrapen, die mit relevanten Themen getaggt sind (z. B. 'Project Management').
- Produktbeschreibung und Screenshots extrahieren.
- KI (wie GPT-4) nutzen, um das Alleinstellungsmerkmal (USP) des Wettbewerbers zusammenzufassen.
- Das interne Dokument zur Wettbewerbslandschaft monatlich aktualisieren.
- Berichte über Technologietrends
Journalisten und Analysten erstellen datengestützte Berichte darüber, welche Branchen die meiste Startup-Aktivität verzeichnen.
- Startup-Daten der letzten 6 Monate von BetaList scrapen.
- Anzahl der Startups pro Kategorie-Tag quantifizieren.
- Anstieg spezifischer Keywords (z. B. 'LLM', 'Sustainability') visualisieren.
- Einen 'State of Startups'-Bericht für Abonnenten oder Stakeholder veröffentlichen.
Optimieren Sie Ihren Workflow mit KI-Automatisierung
Automatio kombiniert die Kraft von KI-Agenten, Web-Automatisierung und intelligenten Integrationen, um Ihnen zu helfen, mehr in weniger Zeit zu erreichen.
Profi-Tipps für das Scrapen von BetaList
Expertentipps für die erfolgreiche Datenextraktion von BetaList.
Detailseiten für Gründerdaten scrapen
Die Hauptliste zeigt nur Zusammenfassungen; konfigurieren Sie Ihren Scraper so, dass er auf die URL jedes Startups klickt, um wertvolle Daten wie Twitter-Handles der Gründer und Social Links zu extrahieren.
Themenspezifische URLs gezielt ansteuern
Um die Effizienz und Datenqualität zu verbessern, sollten Sie gezielt Kategorie-URLs wie /topics/saas oder /topics/ai scrapen, anstatt die gesamte Website zu crawlen.
Residential Proxies verwenden
Um 403 Forbidden-Fehler durch die Sicherheitsfilter von BetaList zu vermeiden, sollten Sie Residential Proxies einsetzen. Diese erscheinen als echte Privatanwender und nicht als Rechenzentrum-Bots.
Zufällige Wartezeiten implementieren
Simulieren Sie menschliches Verhalten, indem Sie zufällige Verzögerungen zwischen 3 und 8 Sekunden zwischen den Aktionen einbauen, um die Wahrscheinlichkeit von Rate Limits zu verringern.
Seiten-Metadaten prüfen
Untersuchen Sie den Quellcode der Seite nach Hydration-Skripten oder JSON-LD-Blöcken, da diese oft strukturierte Daten enthalten, die zuverlässiger zu scrapen sind als reine HTML-Elemente.
Erfahrungsberichte
Was Unsere Nutzer Sagen
Schliessen Sie sich Tausenden zufriedener Nutzer an, die ihren Workflow transformiert haben
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Verwandte Web Scraping

How to Scrape The AA (theaa.com): A Technical Guide for Car & Insurance Data

How to Scrape CSS Author: A Comprehensive Web Scraping Guide

How to Scrape Bilregistret.ai: Swedish Vehicle Data Extraction Guide

How to Scrape Biluppgifter.se: Vehicle Data Extraction Guide

How to Scrape Car.info | Vehicle Data & Valuation Extraction Guide

How to Scrape GoAbroad Study Abroad Programs

How to Scrape ResearchGate: Publication and Researcher Data

How to Scrape Statista: The Ultimate Guide to Market Data Extraction
Häufig gestellte Fragen zu BetaList
Finden Sie Antworten auf häufige Fragen zu BetaList