Comment scraper WebElements : Guide des données du tableau périodique
Extrayez des données précises sur les éléments chimiques de WebElements. Scrapez les masses atomiques, les propriétés physiques et l'historique des découvertes...
À Propos de WebElements
Découvrez ce que WebElements offre et quelles données précieuses peuvent être extraites.
WebElements est un tableau périodique en ligne de référence maintenu par Mark Winter à l'Université de Sheffield. Lancé en 1993, il fut le premier tableau périodique sur le World Wide Web et est devenu depuis une ressource de haute autorité pour les étudiants, les universitaires et les chimistes professionnels. Le site propose des données approfondies et structurées sur chaque élément chimique connu, des masses atomiques standard aux configurations électroniques complexes.
L'intérêt de scraper WebElements réside dans ses données scientifiques de haute qualité, revues par des pairs. Pour les développeurs créant des outils éducatifs, les chercheurs effectuant des analyses de tendances sur le tableau périodique ou les scientifiques des matériaux entraînant des modèles de machine learning, WebElements constitue une source de vérité fiable et techniquement riche qu'il est difficile d'agréger manuellement.
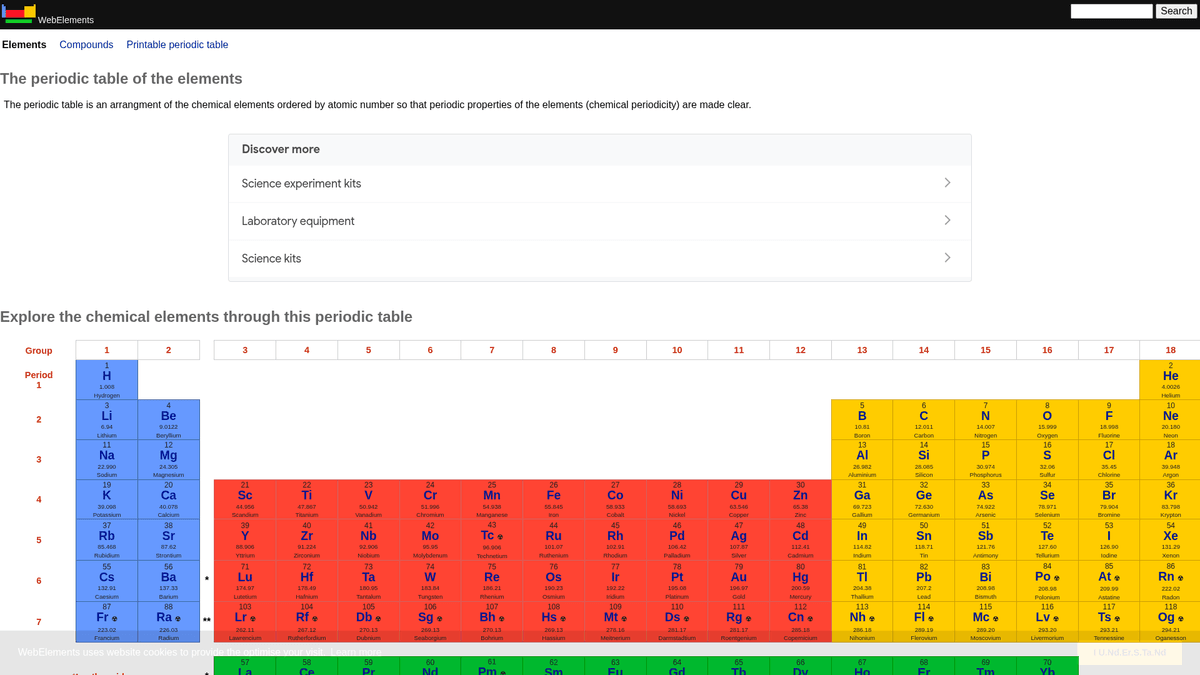
Pourquoi Scraper WebElements?
Découvrez la valeur commerciale et les cas d'utilisation pour l'extraction de données de WebElements.
Alimentation de bases de données scientifiques
Regrouper des données atomiques et chimiques révisées par des pairs dans des bases de données centralisées pour la recherche académique et l'analyse de matériaux à grande échelle.
Développement d'outils éducatifs
Extraire des faits structurés pour alimenter des applications de tableau périodique personnalisées, des plateformes d'apprentissage mobiles et des fiches de révision interactives.
Modélisation prédictive des matériaux
Collecter des propriétés numériques telles que les rayons atomiques et l'électronégativité comme caractéristiques d'entraînement pour des model de machine learning en science des matériaux.
Intégration en informatique chimique
Intégrer des données complètes sur les isotopes et la thermodynamique directement dans les systèmes de gestion de laboratoire et les logiciels de calcul de stœchiométrie.
Chronologies scientifiques historiques
Rassembler les dates de découverte, l'origine des noms et le contexte historique des 118 éléments pour créer des chronologies scientifiques numériques.
Défis du Scraping
Défis techniques que vous pouvez rencontrer lors du scraping de WebElements.
Structure de sous-pages fragmentée
Les données d'un seul élément sont souvent réparties sur plusieurs sous-URL spécifiques comme /atoms, /history ou /compounds, nécessitant un crawl en plusieurs étapes.
Encodage de symboles spéciaux
L'analyse et le stockage corrects de la notation scientifique, des exposants, des indices et des caractères grecs nécessitent une gestion stricte de l'UTF-8 pour éviter la corruption des données.
Exigences de normalisation des unités
L'extraction de données numériques brutes nécessite de supprimer par programmation les unités telles que 'pm', 'K' ou 'g cm-3' et de convertir la notation scientifique en nombres flottants (floats) standards.
Variations des tableaux basées sur les libellés
Les données sont stockées dans des tableaux génériques sans ID uniques, ce qui signifie que les scrapers doivent identifier les champs en vérifiant le contenu textuel des libellés plutôt que les classes CSS.
Scrapez WebElements avec l'IA
Aucun code requis. Extrayez des données en minutes avec l'automatisation par IA.
Comment ça marche
Décrivez ce dont vous avez besoin
Dites à l'IA quelles données vous souhaitez extraire de WebElements. Tapez simplement en langage naturel — pas de code ni de sélecteurs.
L'IA extrait les données
Notre intelligence artificielle navigue sur WebElements, gère le contenu dynamique et extrait exactement ce que vous avez demandé.
Obtenez vos données
Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Pourquoi utiliser l'IA pour le scraping
L'IA facilite le scraping de WebElements sans écrire de code. Notre plateforme alimentée par l'intelligence artificielle comprend quelles données vous voulez — décrivez-les en langage naturel et l'IA les extrait automatiquement.
How to scrape with AI:
- Décrivez ce dont vous avez besoin: Dites à l'IA quelles données vous souhaitez extraire de WebElements. Tapez simplement en langage naturel — pas de code ni de sélecteurs.
- L'IA extrait les données: Notre intelligence artificielle navigue sur WebElements, gère le contenu dynamique et extrait exactement ce que vous avez demandé.
- Obtenez vos données: Recevez des données propres et structurées, prêtes à exporter en CSV, JSON ou à envoyer directement à vos applications.
Why use AI for scraping:
- Mapping visuel des données: Utilisez une interface point-and-click pour mapper des propriétés chimiques complexes à des champs de données spécifiques sans écrire de sélecteurs CSS ou de XPaths personnalisés.
- Suivi récursif des liens: Configurez facilement l'outil pour visiter le tableau périodique principal et suivre automatiquement les liens vers chaque élément et ses sous-pages correspondantes.
- Nettoyage automatique des données: Utilisez les outils de formatage intégrés pour supprimer automatiquement les unités et symboles scientifiques pendant le processus d'extraction, garantissant des sorties numériques propres.
- Surveillance planifiée: Programmez le scraper pour qu'il s'exécute automatiquement à intervalles réguliers afin de capturer les mises à jour des poids atomiques ou les nouvelles propriétés confirmées par l'IUPAC.
Scrapers Web No-Code pour WebElements
Alternatives pointer-cliquer au scraping alimenté par l'IA
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper WebElements sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
Défis Courants
Courbe d'apprentissage
Comprendre les sélecteurs et la logique d'extraction prend du temps
Les sélecteurs cassent
Les modifications du site web peuvent casser tout le workflow
Problèmes de contenu dynamique
Les sites riches en JavaScript nécessitent des solutions complexes
Limitations des CAPTCHAs
La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
Blocage d'IP
Le scraping agressif peut entraîner le blocage de votre IP
Scrapers Web No-Code pour WebElements
Plusieurs outils no-code comme Browse.ai, Octoparse, Axiom et ParseHub peuvent vous aider à scraper WebElements sans écrire de code. Ces outils utilisent généralement des interfaces visuelles pour sélectionner les données, bien qu'ils puissent avoir des difficultés avec le contenu dynamique complexe ou les mesures anti-bot.
Workflow Typique avec les Outils No-Code
- Installer l'extension de navigateur ou s'inscrire sur la plateforme
- Naviguer vers le site web cible et ouvrir l'outil
- Sélectionner en point-and-click les éléments de données à extraire
- Configurer les sélecteurs CSS pour chaque champ de données
- Configurer les règles de pagination pour scraper plusieurs pages
- Gérer les CAPTCHAs (nécessite souvent une résolution manuelle)
- Configurer la planification pour les exécutions automatiques
- Exporter les données en CSV, JSON ou se connecter via API
Défis Courants
- Courbe d'apprentissage: Comprendre les sélecteurs et la logique d'extraction prend du temps
- Les sélecteurs cassent: Les modifications du site web peuvent casser tout le workflow
- Problèmes de contenu dynamique: Les sites riches en JavaScript nécessitent des solutions complexes
- Limitations des CAPTCHAs: La plupart des outils nécessitent une intervention manuelle pour les CAPTCHAs
- Blocage d'IP: Le scraping agressif peut entraîner le blocage de votre IP
Exemples de Code
import requests
from bs4 import BeautifulSoup
import time
# Target URL for a specific element (e.g., Gold)
url = 'https://www.webelements.com/gold/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
def scrape_element(element_url):
try:
response = requests.get(element_url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Extracting the element name from the H1 tag
name = soup.find('h1').get_text().strip()
# Extracting Atomic Number using table label logic
atomic_number = soup.find('th', string=lambda s: s and 'Atomic number' in s).find_next('td').text.strip()
print(f'Element: {name}, Atomic Number: {atomic_number}')
except Exception as e:
print(f'An error occurred: {e}')
# Following robots.txt recommendations
time.sleep(1)
scrape_element(url)Quand Utiliser
Idéal pour les pages HTML statiques avec peu de JavaScript. Parfait pour les blogs, sites d'actualités et pages e-commerce simples.
Avantages
- ●Exécution la plus rapide (sans surcharge navigateur)
- ●Consommation de ressources minimale
- ●Facile à paralléliser avec asyncio
- ●Excellent pour les APIs et pages statiques
Limitations
- ●Ne peut pas exécuter JavaScript
- ●Échoue sur les SPAs et contenu dynamique
- ●Peut avoir des difficultés avec les systèmes anti-bot complexes
Comment Scraper WebElements avec du Code
Python + Requests
import requests
from bs4 import BeautifulSoup
import time
# Target URL for a specific element (e.g., Gold)
url = 'https://www.webelements.com/gold/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
def scrape_element(element_url):
try:
response = requests.get(element_url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Extracting the element name from the H1 tag
name = soup.find('h1').get_text().strip()
# Extracting Atomic Number using table label logic
atomic_number = soup.find('th', string=lambda s: s and 'Atomic number' in s).find_next('td').text.strip()
print(f'Element: {name}, Atomic Number: {atomic_number}')
except Exception as e:
print(f'An error occurred: {e}')
# Following robots.txt recommendations
time.sleep(1)
scrape_element(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Elements are linked from the main periodic table
page.goto('https://www.webelements.com/iron/')
# Wait for the property table to be present
page.wait_for_selector('table')
element_data = {
'name': page.inner_text('h1'),
'density': page.locator('th:has-text("Density") + td').inner_text().strip()
}
print(element_data)
browser.close()
run()Python + Scrapy
import scrapy
class ElementsSpider(scrapy.Spider):
name = 'elements'
start_urls = ['https://www.webelements.com/']
def parse(self, response):
# Follow every element link in the periodic table
for link in response.css('table a[title]::attr(href)'):
yield response.follow(link, self.parse_element)
def parse_element(self, response):
yield {
'name': response.css('h1::text').get().strip(),
'symbol': response.xpath('//th[contains(text(), "Symbol")]/following-sibling::td/text()').get().strip(),
'atomic_number': response.xpath('//th[contains(text(), "Atomic number")]/following-sibling::td/text()').get().strip(),
}Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.webelements.com/silver/');
const data = await page.evaluate(() => {
const name = document.querySelector('h1').innerText;
const meltingPoint = Array.from(document.querySelectorAll('th'))
.find(el => el.textContent.includes('Melting point'))
?.nextElementSibling.innerText;
return { name, meltingPoint };
});
console.log('Extracted Data:', data);
await browser.close();
})();Que Pouvez-Vous Faire Avec Les Données de WebElements
Explorez les applications pratiques et les insights des données de WebElements.
Entraînement d'IA en science des matériaux
Entraînement de modèles de machine learning pour prédire les propriétés de nouveaux alliages en fonction des attributs des éléments.
Comment implémenter :
- 1Extraire les propriétés physiques de tous les éléments métalliques.
- 2Nettoyer et normaliser les valeurs telles que la densité et les points de fusion.
- 3Intégrer les données dans des modèles de régression ou de prédiction de matériaux.
- 4Vérifier les prédictions par rapport aux données expérimentales d'alliages existantes.
Utilisez Automatio pour extraire des données de WebElements et créer ces applications sans écrire de code.
Que Pouvez-Vous Faire Avec Les Données de WebElements
- Entraînement d'IA en science des matériaux
Entraînement de modèles de machine learning pour prédire les propriétés de nouveaux alliages en fonction des attributs des éléments.
- Extraire les propriétés physiques de tous les éléments métalliques.
- Nettoyer et normaliser les valeurs telles que la densité et les points de fusion.
- Intégrer les données dans des modèles de régression ou de prédiction de matériaux.
- Vérifier les prédictions par rapport aux données expérimentales d'alliages existantes.
- Contenu d'application éducative
Alimentation de tableaux périodiques interactifs pour les étudiants en chimie avec des données vérifiées par des pairs.
- Scraper les numéros atomiques, les symboles et les descriptions des éléments.
- Extraire le contexte historique et les détails de la découverte.
- Organiser les données par groupe et bloc périodique.
- Intégrer le tout dans une interface utilisateur avec des structures cristallines visuelles.
- Analyse des tendances chimiques
Visualisation des tendances périodiques comme l'énergie d'ionisation ou le rayon atomique à travers les périodes et les groupes.
- Rassembler les données de propriété pour chaque élément par ordre numérique.
- Catégoriser les éléments dans leurs groupes respectifs.
- Utiliser des bibliothèques graphiques pour visualiser les tendances.
- Identifier et analyser les points de données anormaux dans des blocs spécifiques.
- Gestion d'inventaire de laboratoire
Auto-remplissage des systèmes de gestion chimique avec des données de sécurité physique et de densité.
- Faire correspondre la liste d'inventaire interne aux entrées de WebElements.
- Scraper la densité, les risques de stockage et les données de point de fusion.
- Mettre à jour la base de données centrale du laboratoire via API.
- Générer des alertes de sécurité automatisées pour les éléments à haut risque.
Optimisez votre flux de travail avec l'Automatisation IA
Automatio combine la puissance des agents IA, de l'automatisation web et des integrations intelligentes pour vous aider a accomplir plus en moins de temps.
Conseils Pro pour Scraper WebElements
Conseils d'experts pour extraire avec succès les données de WebElements.
Exploiter des structures d'URL prévisibles
Les éléments suivent une structure /nom_element/ cohérente, vous permettant de générer les URL cibles par programmation pour les 118 éléments au lieu de crawler la page d'accueil.
Identifier les données via des sélecteurs de type 'sibling'
Le site manquant d'ID d'éléments uniques, identifiez les points de données en localisant le texte de la cellule de libellé (ex: 'Melting point') et en sélectionnant la balise 'td' immédiatement suivante (sibling).
Garantir le support de l'UTF-8
Configurez toujours votre environnement de scraping en UTF-8 pour capturer correctement les caractères scientifiques comme Å, ±, et les lettres grecques courantes dans la notation chimique.
Mettre en œuvre des délais de crawl
En tant que ressource académique hébergée par l'Université de Sheffield, il est recommandé de respecter le délai d'une seconde indiqué dans le fichier robots.txt pour éviter de surcharger le serveur.
Cibler des sous-pages granulaires
Pour des données de haute précision telles que les demi-vies d'isotopes spécifiques, scrapez les sous-pages dédiées /isotopes.html plutôt que les pages de résumé pour une meilleure exactitude.
Témoignages
Ce Que Disent Nos Utilisateurs
Rejoignez des milliers d'utilisateurs satisfaits qui ont transforme leur flux de travail
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Associés Web Scraping

How to Scrape GitHub | The Ultimate 2025 Technical Guide

How to Scrape Pollen.com: Local Allergy Data Extraction Guide

How to Scrape Britannica: Educational Data Web Scraper

How to Scrape RethinkEd: A Technical Data Extraction Guide

How to Scrape Wikipedia: The Ultimate Web Scraping Guide

How to Scrape Weather.com: A Guide to Weather Data Extraction

How to Scrape Worldometers for Real-Time Global Statistics

How to Scrape American Museum of Natural History (AMNH)
Questions Fréquentes sur WebElements
Trouvez des réponses aux questions courantes sur WebElements