Come estrarre dati da WebElements: Guida ai dati della Tavola Periodica
Estrai dati precisi sugli elementi chimici da WebElements. Esegui lo scraping di pesi atomici, proprietà fisiche e cronologia delle scoperte per ricerca e...
Informazioni Su WebElements
Scopri cosa offre WebElements e quali dati preziosi possono essere estratti.
WebElements è la principale tavola periodica online, gestita da Mark Winter presso l'Università di Sheffield. Lanciata nel 1993, è stata la prima tavola periodica sul World Wide Web e da allora è diventata una risorsa autorevole per studenti, accademici e chimici professionisti. Il sito offre dati strutturati e approfonditi su ogni elemento chimico conosciuto, dai pesi atomici standard alle complesse configurazioni elettroniche.
Il valore dello scraping di WebElements risiede nei suoi dati scientifici di alta qualità e sottoposti a revisione paritaria. Per gli sviluppatori che creano strumenti didattici, i ricercatori che conducono analisi delle tendenze nella tavola periodica o gli scienziati dei materiali che addestrano model di machine learning, WebElements fornisce una fonte di verità affidabile e tecnicamente ricca, difficile da aggregare manualmente.
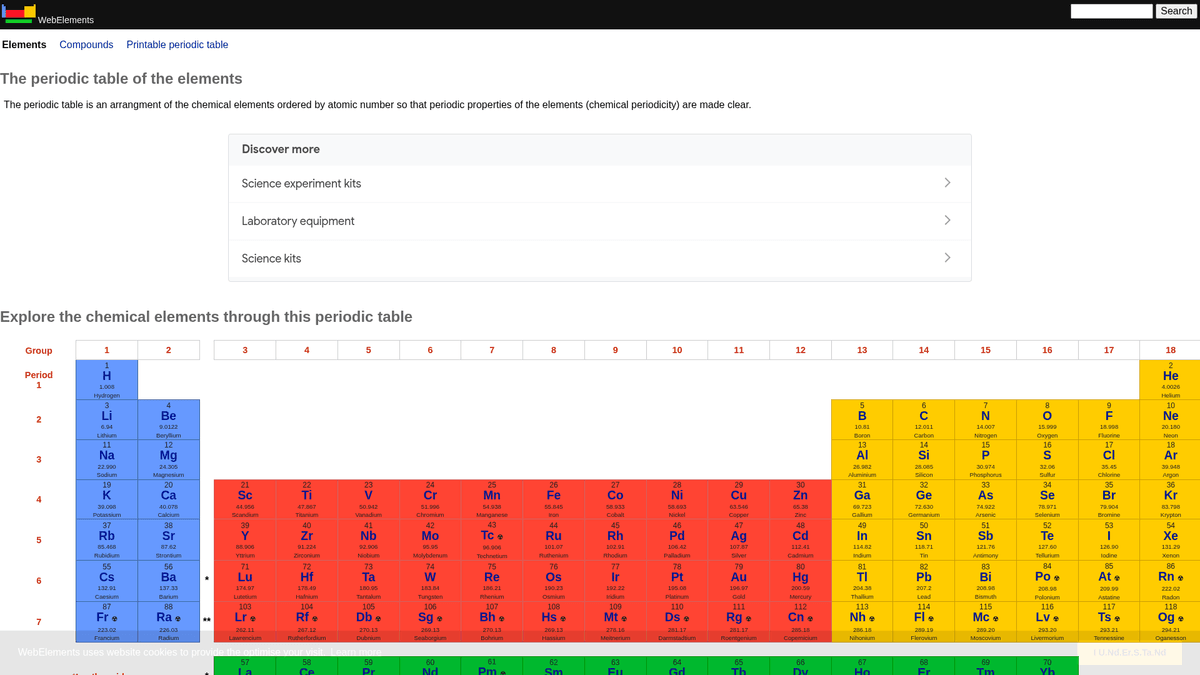
Perché Fare Scraping di WebElements?
Scopri il valore commerciale e i casi d'uso per l'estrazione dati da WebElements.
Popolamento di database scientifici
Aggrega dati atomici e chimici sottoposti a peer-review in database centralizzati per la ricerca accademica e l'analisi dei materiali su larga scala.
Sviluppo di strumenti didattici
Estrai fatti strutturati per alimentare applicazioni personalizzate della tavola periodica, piattaforme di apprendimento mobile e flashcard interattive per la classe.
Modellazione predittiva dei materiali
Raccogli proprietà numeriche come raggi atomici ed elettronegatività come feature di addestramento per modelli di machine learning nella scienza dei materiali.
Integrazione nella chimica informatica
Integra dati completi su isotopi e termodinamica direttamente nei sistemi di gestione di laboratorio e nei software di calcolo stechiometrico.
Cronologie scientifiche storiche
Raccogli date di scoperta, origine dei nomi e contesto storico per tutti i 118 elementi per creare cronologie scientifiche digitali.
Sfide dello Scraping
Sfide tecniche che potresti incontrare durante lo scraping di WebElements.
Struttura delle sottopagine frammentata
I dati per un singolo elemento sono spesso suddivisi in più sotto-URL specifici come /atoms, /history o /compounds, richiedendo una scansione a più fasi.
Codifica dei simboli speciali
Il parsing e la memorizzazione corretta della notazione scientifica, degli apici, dei pedici e dei caratteri greci richiedono una gestione rigorosa di UTF-8 per evitare la corruzione dei dati.
Requisiti di normalizzazione delle unità
L'estrazione di dati numerici grezzi richiede la rimozione programmatica di unità come 'pm', 'K' o 'g cm-3' e la conversione della notazione scientifica in float standard.
Variazioni delle tabelle basate su etichette
I dati sono archiviati in tabelle generiche senza ID univoci, il che significa che gli scraper devono identificare i campi controllando il contenuto testuale delle etichette anziché le classi CSS.
Scraping di WebElements con l'IA
Nessun codice richiesto. Estrai dati in minuti con l'automazione basata sull'IA.
Come Funziona
Descrivi ciò di cui hai bisogno
Di' all'IA quali dati vuoi estrarre da WebElements. Scrivi semplicemente in linguaggio naturale — nessun codice o selettore necessario.
L'IA estrae i dati
La nostra intelligenza artificiale naviga WebElements, gestisce contenuti dinamici ed estrae esattamente ciò che hai richiesto.
Ottieni i tuoi dati
Ricevi dati puliti e strutturati pronti per l'esportazione in CSV, JSON o da inviare direttamente alle tue applicazioni.
Perché Usare l'IA per lo Scraping
L'IA rende facile lo scraping di WebElements senza scrivere codice. La nostra piattaforma basata sull'intelligenza artificiale capisce quali dati vuoi — descrivili in linguaggio naturale e l'IA li estrae automaticamente.
How to scrape with AI:
- Descrivi ciò di cui hai bisogno: Di' all'IA quali dati vuoi estrarre da WebElements. Scrivi semplicemente in linguaggio naturale — nessun codice o selettore necessario.
- L'IA estrae i dati: La nostra intelligenza artificiale naviga WebElements, gestisce contenuti dinamici ed estrae esattamente ciò che hai richiesto.
- Ottieni i tuoi dati: Ricevi dati puliti e strutturati pronti per l'esportazione in CSV, JSON o da inviare direttamente alle tue applicazioni.
Why use AI for scraping:
- Mappatura visuale dei dati: Utilizza un'interfaccia punta-e-clicca per mappare proprietà chimiche complesse a campi dati specifici senza scrivere selettori CSS o XPath personalizzati.
- Segnalazione ricorsiva dei link: Configura facilmente lo strumento per visitare la tavola periodica principale e seguire automaticamente i link di ogni elemento e delle relative sottopagine.
- Pulizia automatica dei dati: Utilizza strumenti di formattazione integrati per rimuovere automaticamente unità scientifiche e simboli durante il processo di estrazione, garantendo output numerici puliti.
- Monitoraggio pianificato: Imposta lo scraper per l'esecuzione automatica a intervalli per acquisire aggiornamenti sui pesi atomici o nuove proprietà scoperte non appena confermate dalla IUPAC.
Scraper Web No-Code per WebElements
Alternative point-and-click allo scraping alimentato da IA
Diversi strumenti no-code come Browse.ai, Octoparse, Axiom e ParseHub possono aiutarti a fare scraping di WebElements senza scrivere codice. Questi strumenti usano interfacce visive per selezionare i dati, anche se possono avere difficoltà con contenuti dinamici complessi o misure anti-bot.
Workflow Tipico con Strumenti No-Code
Sfide Comuni
Curva di apprendimento
Comprendere selettori e logica di estrazione richiede tempo
I selettori si rompono
Le modifiche al sito web possono rompere l'intero flusso di lavoro
Problemi con contenuti dinamici
I siti con molto JavaScript richiedono soluzioni complesse
Limitazioni CAPTCHA
La maggior parte degli strumenti richiede intervento manuale per i CAPTCHA
Blocco IP
Lo scraping aggressivo può portare al blocco del tuo IP
Scraper Web No-Code per WebElements
Diversi strumenti no-code come Browse.ai, Octoparse, Axiom e ParseHub possono aiutarti a fare scraping di WebElements senza scrivere codice. Questi strumenti usano interfacce visive per selezionare i dati, anche se possono avere difficoltà con contenuti dinamici complessi o misure anti-bot.
Workflow Tipico con Strumenti No-Code
- Installare l'estensione del browser o registrarsi sulla piattaforma
- Navigare verso il sito web target e aprire lo strumento
- Selezionare con point-and-click gli elementi dati da estrarre
- Configurare i selettori CSS per ogni campo dati
- Impostare le regole di paginazione per lo scraping di più pagine
- Gestire i CAPTCHA (spesso richiede risoluzione manuale)
- Configurare la pianificazione per le esecuzioni automatiche
- Esportare i dati in CSV, JSON o collegare tramite API
Sfide Comuni
- Curva di apprendimento: Comprendere selettori e logica di estrazione richiede tempo
- I selettori si rompono: Le modifiche al sito web possono rompere l'intero flusso di lavoro
- Problemi con contenuti dinamici: I siti con molto JavaScript richiedono soluzioni complesse
- Limitazioni CAPTCHA: La maggior parte degli strumenti richiede intervento manuale per i CAPTCHA
- Blocco IP: Lo scraping aggressivo può portare al blocco del tuo IP
Esempi di Codice
import requests
from bs4 import BeautifulSoup
import time
# Target URL for a specific element (e.g., Gold)
url = 'https://www.webelements.com/gold/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
def scrape_element(element_url):
try:
response = requests.get(element_url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Extracting the element name from the H1 tag
name = soup.find('h1').get_text().strip()
# Extracting Atomic Number using table label logic
atomic_number = soup.find('th', string=lambda s: s and 'Atomic number' in s).find_next('td').text.strip()
print(f'Element: {name}, Atomic Number: {atomic_number}')
except Exception as e:
print(f'An error occurred: {e}')
# Following robots.txt recommendations
time.sleep(1)
scrape_element(url)Quando Usare
Ideale per pagine HTML statiche con JavaScript minimo. Perfetto per blog, siti di notizie e pagine prodotto e-commerce semplici.
Vantaggi
- ●Esecuzione più veloce (senza overhead del browser)
- ●Consumo risorse minimo
- ●Facile da parallelizzare con asyncio
- ●Ottimo per API e pagine statiche
Limitazioni
- ●Non può eseguire JavaScript
- ●Fallisce su SPA e contenuti dinamici
- ●Può avere difficoltà con sistemi anti-bot complessi
Come Fare Scraping di WebElements con Codice
Python + Requests
import requests
from bs4 import BeautifulSoup
import time
# Target URL for a specific element (e.g., Gold)
url = 'https://www.webelements.com/gold/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
def scrape_element(element_url):
try:
response = requests.get(element_url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Extracting the element name from the H1 tag
name = soup.find('h1').get_text().strip()
# Extracting Atomic Number using table label logic
atomic_number = soup.find('th', string=lambda s: s and 'Atomic number' in s).find_next('td').text.strip()
print(f'Element: {name}, Atomic Number: {atomic_number}')
except Exception as e:
print(f'An error occurred: {e}')
# Following robots.txt recommendations
time.sleep(1)
scrape_element(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Elements are linked from the main periodic table
page.goto('https://www.webelements.com/iron/')
# Wait for the property table to be present
page.wait_for_selector('table')
element_data = {
'name': page.inner_text('h1'),
'density': page.locator('th:has-text("Density") + td').inner_text().strip()
}
print(element_data)
browser.close()
run()Python + Scrapy
import scrapy
class ElementsSpider(scrapy.Spider):
name = 'elements'
start_urls = ['https://www.webelements.com/']
def parse(self, response):
# Follow every element link in the periodic table
for link in response.css('table a[title]::attr(href)'):
yield response.follow(link, self.parse_element)
def parse_element(self, response):
yield {
'name': response.css('h1::text').get().strip(),
'symbol': response.xpath('//th[contains(text(), "Symbol")]/following-sibling::td/text()').get().strip(),
'atomic_number': response.xpath('//th[contains(text(), "Atomic number")]/following-sibling::td/text()').get().strip(),
}Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.webelements.com/silver/');
const data = await page.evaluate(() => {
const name = document.querySelector('h1').innerText;
const meltingPoint = Array.from(document.querySelectorAll('th'))
.find(el => el.textContent.includes('Melting point'))
?.nextElementSibling.innerText;
return { name, meltingPoint };
});
console.log('Extracted Data:', data);
await browser.close();
})();Cosa Puoi Fare Con I Dati di WebElements
Esplora applicazioni pratiche e insight dai dati di WebElements.
Addestramento AI per la Scienza dei Materiali
Addestramento di model di machine learning per prevedere le proprietà di nuove leghe basandosi sugli attributi elementari.
Come implementare:
- 1Estrai le proprietà fisiche di tutti gli elementi metallici.
- 2Pulisci e normalizza i valori come densità e punti di fusione.
- 3Inserisci i dati in model di regressione o predittivi per i materiali.
- 4Verifica le previsioni rispetto ai dati sperimentali esistenti sulle leghe.
Usa Automatio per estrarre dati da WebElements e costruire queste applicazioni senza scrivere codice.
Cosa Puoi Fare Con I Dati di WebElements
- Addestramento AI per la Scienza dei Materiali
Addestramento di model di machine learning per prevedere le proprietà di nuove leghe basandosi sugli attributi elementari.
- Estrai le proprietà fisiche di tutti gli elementi metallici.
- Pulisci e normalizza i valori come densità e punti di fusione.
- Inserisci i dati in model di regressione o predittivi per i materiali.
- Verifica le previsioni rispetto ai dati sperimentali esistenti sulle leghe.
- Contenuti per App Didattiche
Popolamento di tavole periodiche interattive per studenti di chimica con dati sottoposti a revisione paritaria.
- Estrai numeri atomici, simboli e descrizioni degli elementi.
- Estrai il contesto storico e i dettagli della scoperta.
- Organizza i dati per gruppo periodico e blocco.
- Integrali in un'interfaccia utente con strutture cristalline visuali.
- Analisi delle Tendenze Chimiche
Visualizzazione delle tendenze periodiche come l'energia di ionizzazione o il raggio atomico attraverso periodi e gruppi.
- Raccogli i dati sulle proprietà di ogni elemento in ordine numerico.
- Categorizza gli elementi nei rispettivi gruppi.
- Usa librerie grafiche per visualizzare le tendenze.
- Identifica e analizza i punti dati anomali in blocchi specifici.
- Gestione dell'Inventario di Laboratorio
Popolamento automatico dei sistemi di gestione chimica con dati sulla sicurezza fisica e sulla densità.
- Mappa l'elenco dell'inventario interno con le voci di WebElements.
- Estrai dati su densità, rischi di stoccaggio e punti di fusione.
- Aggiorna il database centralizzato del laboratorio tramite API.
- Genera avvisi di sicurezza automatizzati per gli elementi ad alto rischio.
Potenzia il tuo workflow con l'automazione AI
Automatio combina la potenza degli agenti AI, dell'automazione web e delle integrazioni intelligenti per aiutarti a fare di piu in meno tempo.
Consigli Pro per lo Scraping di WebElements
Consigli esperti per estrarre con successo i dati da WebElements.
Sfrutta pattern di URL prevedibili
Gli elementi seguono una struttura /element_name/ coerente, che consente di generare gli URL di destinazione programmaticamente per tutti i 118 elementi invece di scansionare l'intera homepage.
Identifica i dati tramite selettori sibling
Poiché il sito manca di ID univoci per gli elementi, identifica i punti dati individuando il testo della cella dell'etichetta (es. 'Melting point') e selezionando il tag 'td' immediatamente successivo.
Garantisci il supporto UTF-8
Imposta sempre il tuo ambiente di scraping su UTF-8 per acquisire correttamente i caratteri scientifici come Å, ± e le lettere greche comuni nella notazione chimica.
Implementa dei crawl delay
Essendo una risorsa accademica ospitata dalla University of Sheffield, è buona norma seguire il delay di 1 secondo indicato nel file robots.txt per evitare di sovraccaricare il server.
Punta a sottopagine granulari
Per dati ad alta precisione, come l'emivita di specifici isotopi, esegui lo scraping delle sottopagine dedicate /isotopes.html anziché delle pagine di riepilogo per una migliore accuratezza.
Testimonianze
Cosa dicono i nostri utenti
Unisciti a migliaia di utenti soddisfatti che hanno trasformato il loro workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Correlati Web Scraping

How to Scrape GitHub | The Ultimate 2025 Technical Guide

How to Scrape Pollen.com: Local Allergy Data Extraction Guide

How to Scrape Britannica: Educational Data Web Scraper

How to Scrape RethinkEd: A Technical Data Extraction Guide

How to Scrape Wikipedia: The Ultimate Web Scraping Guide

How to Scrape Weather.com: A Guide to Weather Data Extraction

How to Scrape Worldometers for Real-Time Global Statistics

How to Scrape American Museum of Natural History (AMNH)
Domande frequenti su WebElements
Trova risposte alle domande comuni su WebElements