OnTheMarketのスクレイピング方法 | OnTheMarket Web Scraper
OnTheMarketをスクレイピングして、英国の不動産掲載情報、価格、エージェントデータを抽出する方法を学びましょう。不動産投資家や市場アナリストに不可欠なガイドです。
ボット対策検出
- Cloudflare
- エンタープライズ級のWAFとボット管理。JavaScriptチャレンジ、CAPTCHA、行動分析を使用。ステルス設定でのブラウザ自動化が必要。
- CloudFront
- レート制限
- 時間あたりのIP/セッションごとのリクエストを制限。ローテーションプロキシ、リクエスト遅延、分散スクレイピングで回避可能。
- IPブロック
- 既知のデータセンターIPとフラグ付きアドレスをブロック。効果的に回避するにはレジデンシャルまたはモバイルプロキシが必要。
- Google reCAPTCHA
- GoogleのCAPTCHAシステム。v2はユーザー操作が必要、v3はリスクスコアリングでサイレント動作。CAPTCHAサービスで解決可能。
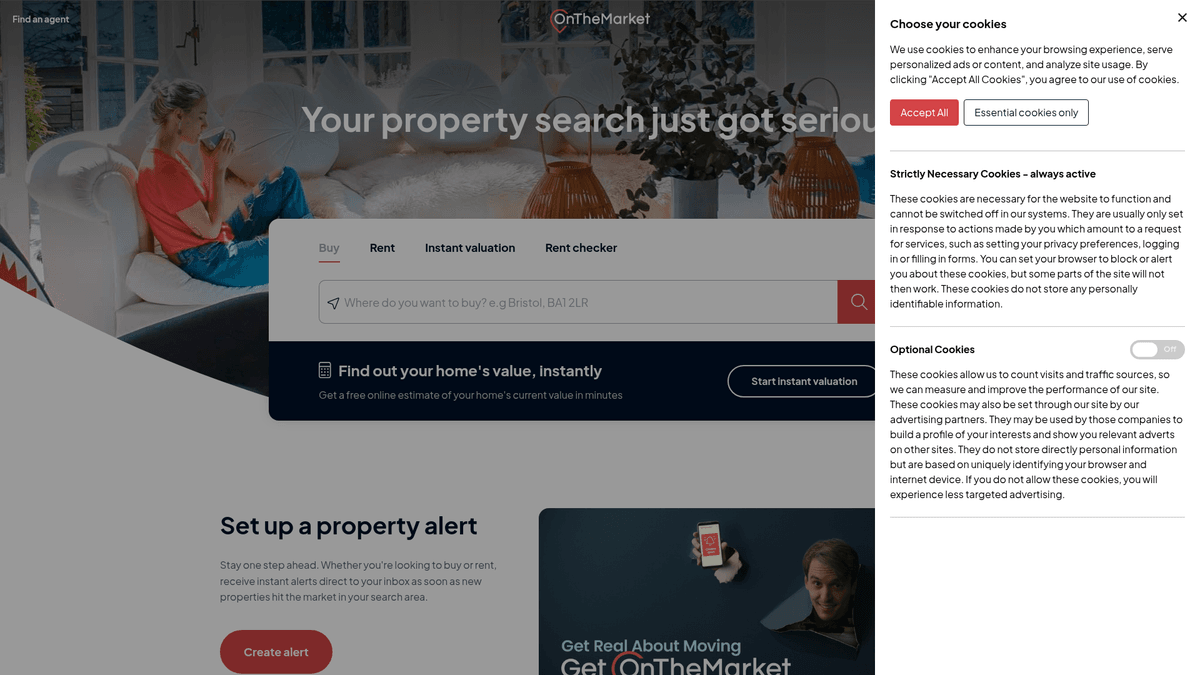
OnTheMarketについて
OnTheMarketが提供するものと抽出可能な貴重なデータを発見してください。
マーケットプレイスの概要
OnTheMarketは、2015年に設立され、現在はCoStar Groupが過半数の株式を保有する英国有数の不動産ポータルサイトです。不動産エージェントが英国全土の住宅および商業物件の売買・賃貸情報を掲載するための重要なプラットフォームとなっています。RightmoveやZooplaの主要な競合であり、独自の掲載条件が特徴です。
データの可用性
このプラットフォームには、販売価格、詳細な物件仕様、高解像度の画像、間取り図など、構造化された不動産情報の膨大なリポジトリがあります。大きな特徴は "Only With Us" ラベルで、他の主要ポータルに掲載される24時間以上前にOnTheMarketに掲載されるため、データ収集において明確な時間的優位性を提供します。
スクレイピングの可能性
不動産専門家や投資家にとって、このプラットフォームをスクレイピングすることは、市場分析やトレンド追跡において非常に価値があります。このデータに大規模にアクセスすることで、手作業なしで自動査定モデル(AVM)の構築、競合在庫の監視、価格下落検知による意欲的な売り手の特定が可能になります。
なぜOnTheMarketをスクレイピングするのか?
OnTheMarketからのデータ抽出のビジネス価値とユースケースを発見してください。
早期公開物件 'Only With Us' のリアルタイム監視
正確な物件査定と投資先の探索
不動産エージェンシーの市場シェアに関する競合インテリジェンス
引越しやリフォームサービスの lead generation
意欲的な売り手を特定するための過去の価格追跡
machine learning モデルのための物件属性の集約
スクレイピングの課題
OnTheMarketのスクレイピング時に遭遇する可能性のある技術的課題。
CloudFrontおよびCloudflareによる強力なアンチボット保護
JavaScriptレンダリング(React/Next.js)への高い依存度
動的なCSSクラス名やDOM構造の頻繁な変更
厳格なレート制限とIPベースのセッショントラッキング
動的なURLパラメータを含む複雑なページネーションロジック
OnTheMarketをAIでスクレイピング
コーディング不要。AI搭載の自動化で数分でデータを抽出。
仕組み
必要なものを記述
OnTheMarketから抽出したいデータをAIに伝えてください。自然言語で入力するだけ — コードやセレクターは不要です。
AIがデータを抽出
人工知能がOnTheMarketをナビゲートし、動的コンテンツを処理し、あなたが求めたものを正確に抽出します。
データを取得
CSV、JSONでエクスポートしたり、アプリやワークフローに直接送信できる、クリーンで構造化されたデータを受け取ります。
なぜスクレイピングにAIを使うのか
AIを使えば、コードを書かずにOnTheMarketを簡単にスクレイピングできます。人工知能搭載のプラットフォームが必要なデータを理解します — 自然言語で記述するだけで、AIが自動的に抽出します。
How to scrape with AI:
- 必要なものを記述: OnTheMarketから抽出したいデータをAIに伝えてください。自然言語で入力するだけ — コードやセレクターは不要です。
- AIがデータを抽出: 人工知能がOnTheMarketをナビゲートし、動的コンテンツを処理し、あなたが求めたものを正確に抽出します。
- データを取得: CSV、JSONでエクスポートしたり、アプリやワークフローに直接送信できる、クリーンで構造化されたデータを受け取ります。
Why use AI for scraping:
- 複雑なJavaScriptやhydrationの問題を自動的に回避
- クラウドベースのresidential proxiesを使用してIPブロックを防止
- スケジュール機能により、24時間先行の掲載情報を即座に取得
- 複数ページの物件結果を抽出するためのノーコード設定
- リアルタイム分析のためのGoogle Sheetsへの直接連携
OnTheMarket用ノーコードWebスクレイパー
AI搭載スクレイピングのポイント&クリック代替手段
Browse.ai、Octoparse、Axiom、ParseHubなどのノーコードツールは、コードを書かずにOnTheMarketをスクレイピングするのに役立ちます。これらのツールは視覚的なインターフェースを使用してデータを選択しますが、複雑な動的コンテンツやアンチボット対策には苦戦する場合があります。
ノーコードツールでの一般的なワークフロー
一般的な課題
学習曲線
セレクタと抽出ロジックの理解に時間がかかる
セレクタの破損
Webサイトの変更によりワークフロー全体が壊れる可能性がある
動的コンテンツの問題
JavaScript多用サイトは複雑な回避策が必要
CAPTCHAの制限
ほとんどのツールはCAPTCHAに手動介入が必要
IPブロック
過度なスクレイピングはIPのブロックにつながる可能性がある
OnTheMarket用ノーコードWebスクレイパー
Browse.ai、Octoparse、Axiom、ParseHubなどのノーコードツールは、コードを書かずにOnTheMarketをスクレイピングするのに役立ちます。これらのツールは視覚的なインターフェースを使用してデータを選択しますが、複雑な動的コンテンツやアンチボット対策には苦戦する場合があります。
ノーコードツールでの一般的なワークフロー
- ブラウザ拡張機能をインストールするかプラットフォームに登録する
- ターゲットWebサイトに移動してツールを開く
- ポイント&クリックで抽出するデータ要素を選択する
- 各データフィールドのCSSセレクタを設定する
- 複数ページをスクレイピングするためのページネーションルールを設定する
- CAPTCHAに対処する(多くの場合手動解決が必要)
- 自動実行のスケジュールを設定する
- データをCSV、JSONにエクスポートするかAPIで接続する
一般的な課題
- 学習曲線: セレクタと抽出ロジックの理解に時間がかかる
- セレクタの破損: Webサイトの変更によりワークフロー全体が壊れる可能性がある
- 動的コンテンツの問題: JavaScript多用サイトは複雑な回避策が必要
- CAPTCHAの制限: ほとんどのツールはCAPTCHAに手動介入が必要
- IPブロック: 過度なスクレイピングはIPのブロックにつながる可能性がある
コード例
import requests
from bs4 import BeautifulSoup
# OnTheMarketはCloudflareを使用しており、標準のrequestsでは403 Forbiddenになることが多いです
url = 'https://www.onthemarket.com/for-sale/property/london/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# セレクターは変更される可能性があります。結果を含むリストアイテムを探します
listings = soup.select('li[id^="result-"]')
for item in listings:
price = item.select_one('a.text-xl').text.strip() if item.select_one('a.text-xl') else 'N/A'
address = item.select_one('address').text.strip() if item.select_one('address') else 'N/A'
print(f'Price: {price} | Address: {address}')
except Exception as e:
print(f'Scraping failed: {e}')いつ使うか
JavaScriptが最小限の静的HTMLページに最適。ブログ、ニュースサイト、シンプルなEコマース製品ページに理想的。
メリット
- ●最速の実行(ブラウザオーバーヘッドなし)
- ●最小限のリソース消費
- ●asyncioで簡単に並列化
- ●APIと静的ページに最適
制限事項
- ●JavaScriptを実行できない
- ●SPAや動的コンテンツで失敗
- ●複雑なアンチボットシステムで苦戦する可能性
コードでOnTheMarketをスクレイピングする方法
Python + Requests
import requests
from bs4 import BeautifulSoup
# OnTheMarketはCloudflareを使用しており、標準のrequestsでは403 Forbiddenになることが多いです
url = 'https://www.onthemarket.com/for-sale/property/london/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# セレクターは変更される可能性があります。結果を含むリストアイテムを探します
listings = soup.select('li[id^="result-"]')
for item in listings:
price = item.select_one('a.text-xl').text.strip() if item.select_one('a.text-xl') else 'N/A'
address = item.select_one('address').text.strip() if item.select_one('address') else 'N/A'
print(f'Price: {price} | Address: {address}')
except Exception as e:
print(f'Scraping failed: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def scrape_otm():
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
# ステルスに近いコンテキストを使用
context = browser.new_context(user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36')
page = context.new_page()
page.goto('https://www.onthemarket.com/for-sale/property/london/', wait_until='networkidle')
# 結果がレンダリングされるのを待機
page.wait_for_selector('li[id^="result-"]')
listings = page.query_selector_all('li[id^="result-"]')
for prop in listings:
title = prop.query_selector('.text-sm.text-denim').inner_text()
price = prop.query_selector('.text-xl.font-bold').inner_text()
print({'title': title, 'price': price})
browser.close()
scrape_otm()Python + Scrapy
import scrapy
class OnTheMarketSpider(scrapy.Spider):
name = 'otm'
start_urls = ['https://www.onthemarket.com/for-sale/property/london/']
def parse(self, response):
# メインのリストコンテナ内の各アイテムをターゲットにする
for item in response.css('li[id^="result-"]'):
yield {
'price': item.css('.text-xl.font-bold::text').get(),
'address': item.css('address span::text').get(),
'agency': item.css('img::attr(alt)').get(),
'link': response.urljoin(item.css('a::attr(href)').get())
}
next_page = response.css('link[rel="next"]::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36');
await page.goto('https://www.onthemarket.com/for-sale/property/london/', { waitUntil: 'networkidle2' });
const data = await page.evaluate(() => {
return Array.from(document.querySelectorAll('li[id^="result-"]')).map(li => ({
price: li.querySelector('.text-xl')?.innerText.trim(),
address: li.querySelector('address')?.innerText.trim()
}));
});
console.log(data);
await browser.close();
})();OnTheMarketデータで何ができるか
OnTheMarketデータからの実用的なアプリケーションとインサイトを探索してください。
英国の高利回り賃貸物件の探索
Buy-to-let(貸付用物件購入)投資家は、賃貸データと販売データを比較することで、ROIの高い物件を特定できます。
実装方法:
- 1同じ郵便番号(postcode)の販売物件と賃貸物件をスクレイピングする。
- 2物件タイプと寝室数を照合して利回りを算出する。
- 3価格対賃料の比率が最も有利なエリアを特定する。
- 4'Only With Us' の物件をフィルタリングして、市場に出回る前に案件を確保する。
Automatioを使用してOnTheMarketからデータを抽出し、コードを書かずにこれらのアプリケーションを構築しましょう。
OnTheMarketデータで何ができるか
- 英国の高利回り賃貸物件の探索
Buy-to-let(貸付用物件購入)投資家は、賃貸データと販売データを比較することで、ROIの高い物件を特定できます。
- 同じ郵便番号(postcode)の販売物件と賃貸物件をスクレイピングする。
- 物件タイプと寝室数を照合して利回りを算出する。
- 価格対賃料の比率が最も有利なエリアを特定する。
- 'Only With Us' の物件をフィルタリングして、市場に出回る前に案件を確保する。
- 市場在庫レポートの自動化
アナリストは、新規掲載数と成約物件数を追跡することで、市場の過熱度を判断できます。
- 英国の主要都市の物件リストを毎日スクレイピングする。
- 'New' と 'Sold STC'(売却合意済み)または 'Under Offer'(交渉中)のラベル数をカウントする。
- 価格帯別の平均市場滞留日数を計算する。
- 在庫トレンドをダッシュボードで可視化する。
- エージェンシーの市場シェア分析
不動産エージェントは、競合他社の掲載ボリュームを追跡し、地域のマーケティング戦略を調整できます。
- 特定の地方自治体内のすべての物件リストから 'Agent Name' を抽出する。
- データを集計して、どのエージェンシーが最も多くの掲載物件を持っているかを確認する。
- エージェンシーの価格戦略や手数料ベースの価格改定を監視する。
- 競合他社のパフォーマンスに基づいてベンダーへのアプローチを調整する。
- Proptech 査定 API
スタートアップは、ライブの市場データを主要な学習ソースとして使用し、査定ツールを構築できます。
- 延べ床面積を含む過去および現在の物件データをスクレイピングする。
- データをクレンジングし、価格やサイズの異常値を処理する。
- 地域の属性に基づいて物件価値を予測する regression model を学習させる。
- 外部 API を介してユーザーにリアルタイムの推定値を提供する。
ワークフローを強化する AI自動化
AutomatioはAIエージェント、ウェブ自動化、スマート統合のパワーを組み合わせ、より短時間でより多くのことを達成するお手伝いをします。
OnTheMarketスクレイピングのプロのヒント
OnTheMarketからデータを正常に抽出するための専門家のアドバイス。
HTMLソース内の __OTM_DATA__ scriptタグをターゲットにすることで、複雑なCSSクラスをパースすることなくクリーンなJSONデータを取得できます。
residential proxiesを専用に使用してください。データセンターのIPは、CloudFrontによってほぼ即座にフラグを立てられます。
headless browserでは、Reactコンポーネントが完全にhydrationされるまで、常に 'wait_until' 条件を設定してください。
'Only With Us' とラベル付けされた物件を早朝にスクレイピングすることで、他のポータルサイトよりも24時間早く情報を入手できます。
人間のブラウジング行動を模倣するために、3秒から10秒のランダムなスリープ間隔を実装してください。
データベースでの重複処理を避け、帯域幅を節約するために 'Date Added' フィールドを確認してください。
お客様の声
ユーザーの声
ワークフローを変革した何千人もの満足したユーザーに加わりましょう
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
関連 Web Scraping
How to Scrape Century 21 Property Listings
How to Scrape Sacramento Delta Property Management
How to Scrape LivePiazza: Philadelphia Real Estate Scraper
How to Scrape HotPads: A Complete Guide to Extracting Rental Data
How to Scrape Locations Hawaii | Locations Hawaii Web Scraper
How to Scrape RE/MAX (remax.com) Real Estate Listings
How to Scrape Century 21: A Technical Real Estate Guide
How to Scrape Homes.com: Real Estate Data Extraction Guide
OnTheMarketについてのよくある質問
OnTheMarketに関するよくある質問への回答を見つけてください