Jak pobierać dane z WebElements: Przewodnik po danych układu okresowego
Wyodrębniaj precyzyjne dane o pierwiastkach chemicznych z WebElements. Pobieraj masy atomowe, właściwości fizyczne i historię odkryć dla badań i zastosowań AI.
O WebElements
Odkryj, co oferuje WebElements i jakie cenne dane można wyodrębnić.
WebElements to czołowy internetowy układ okresowy prowadzony przez Marka Wintera na Uniwersytecie w Sheffield. Uruchomiony w 1993 roku, był pierwszym układem okresowym w sieci World Wide Web i od tego czasu stał się wysoko cenionym zasobem dla studentów, pracowników akademickich i profesjonalnych chemików. Witryna oferuje szczegółowe, ustrukturyzowane dane o każdym znanym pierwiastku chemicznym, od standardowych mas atomowych po złożone konfiguracje elektronowe.
Wartość scrapowania WebElements leży w wysokiej jakości, recenzowanych danych naukowych. Dla deweloperów budujących narzędzia edukacyjne, naukowców prowadzących analizę trendów w układzie okresowym czy inżynierów materiałowych trenujących modele machine learning, WebElements stanowi wiarygodne i technicznie bogate źródło prawdy, które trudno jest zagregować ręcznie.
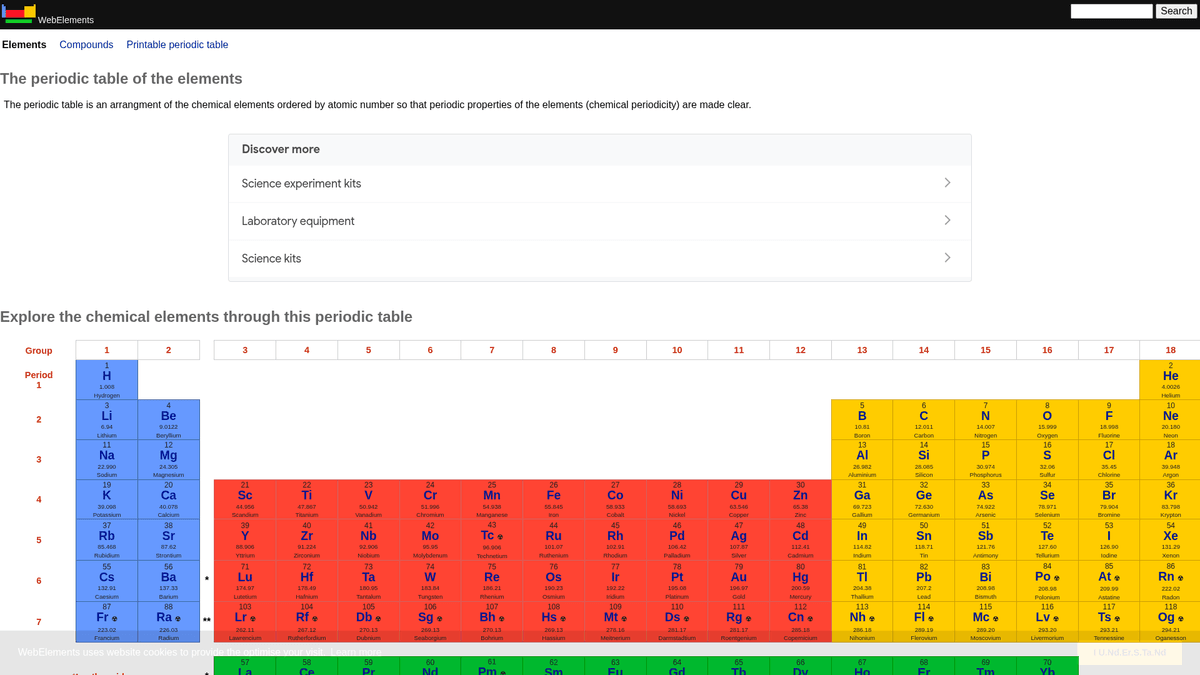
Dlaczego Scrapować WebElements?
Odkryj wartość biznesową i przypadki użycia ekstrakcji danych z WebElements.
Zbieranie wysokiej jakości danych naukowych do tworzenia narzędzi edukacyjnych.
Agregowanie właściwości pierwiastków na potrzeby badań w inżynierii materiałowej i modeli machine learning.
Automatyczne zasilanie systemów inwentaryzacji laboratoryjnej specyfikacjami chemicznymi.
Analiza historyczna odkryć pierwiastków i postępu naukowego.
Tworzenie kompleksowych zestawów danych o właściwościach chemicznych do publikacji akademickich.
Wyzwania Scrapowania
Wyzwania techniczne, które możesz napotkać podczas scrapowania WebElements.
Dane są rozproszone na wielu podstronach dla każdego pierwiastka (np. /history, /compounds).
Starsze układy HTML oparte na tabelach wymagają precyzyjnej logiki selektorów.
Pomylenie nazwy domeny z klasą „WebElement” w Selenium podczas szukania wsparcia.
Scrapuj WebElements z AI
Bez kodowania. Wyodrębnij dane w kilka minut dzięki automatyzacji opartej na AI.
Jak to działa
Opisz, czego potrzebujesz
Powiedz AI, jakie dane chcesz wyodrębnić z WebElements. Po prostu wpisz to w języku naturalnym — bez kodu czy selektorów.
AI wyodrębnia dane
Nasza sztuczna inteligencja nawiguje po WebElements, obsługuje dynamiczną treść i wyodrębnia dokładnie to, o co prosiłeś.
Otrzymaj swoje dane
Otrzymaj czyste, ustrukturyzowane dane gotowe do eksportu jako CSV, JSON lub do bezpośredniego przesłania do twoich aplikacji.
Dlaczego warto używać AI do scrapowania
AI ułatwia scrapowanie WebElements bez pisania kodu. Nasza platforma oparta na sztucznej inteligencji rozumie, jakich danych potrzebujesz — po prostu opisz je w języku naturalnym, a AI wyodrębni je automatycznie.
How to scrape with AI:
- Opisz, czego potrzebujesz: Powiedz AI, jakie dane chcesz wyodrębnić z WebElements. Po prostu wpisz to w języku naturalnym — bez kodu czy selektorów.
- AI wyodrębnia dane: Nasza sztuczna inteligencja nawiguje po WebElements, obsługuje dynamiczną treść i wyodrębnia dokładnie to, o co prosiłeś.
- Otrzymaj swoje dane: Otrzymaj czyste, ustrukturyzowane dane gotowe do eksportu jako CSV, JSON lub do bezpośredniego przesłania do twoich aplikacji.
Why use AI for scraping:
- Nawigacja bez kodu przez hierarchiczne struktury pierwiastków.
- Automatyczna obsługa ekstrakcji złożonych tabel naukowych.
- Wykonywanie w chmurze pozwala na ekstrakcję pełnego zbioru danych bez lokalnych przestojów.
- Łatwy eksport do CSV/JSON do bezpośredniego użycia w narzędziach analizy naukowej.
- Zaplanowane monitorowanie może wykrywać aktualizacje danych potwierdzonych pierwiastków.
Scrapery No-Code dla WebElements
Alternatywy point-and-click dla scrapingu opartego na AI
Różne narzędzia no-code jak Browse.ai, Octoparse, Axiom i ParseHub mogą pomóc w scrapowaniu WebElements bez pisania kodu. Te narzędzia używają wizualnych interfejsów do wyboru danych, choć mogą mieć problemy ze złożoną dynamiczną zawartością lub zabezpieczeniami anti-bot.
Typowy Workflow z Narzędziami No-Code
Częste Wyzwania
Krzywa uczenia
Zrozumienie selektorów i logiki ekstrakcji wymaga czasu
Selektory się psują
Zmiany na stronie mogą zepsuć cały przepływ pracy
Problemy z dynamiczną treścią
Strony bogate w JavaScript wymagają złożonych obejść
Ograniczenia CAPTCHA
Większość narzędzi wymaga ręcznej interwencji przy CAPTCHA
Blokowanie IP
Agresywne scrapowanie może prowadzić do zablokowania IP
Scrapery No-Code dla WebElements
Różne narzędzia no-code jak Browse.ai, Octoparse, Axiom i ParseHub mogą pomóc w scrapowaniu WebElements bez pisania kodu. Te narzędzia używają wizualnych interfejsów do wyboru danych, choć mogą mieć problemy ze złożoną dynamiczną zawartością lub zabezpieczeniami anti-bot.
Typowy Workflow z Narzędziami No-Code
- Zainstaluj rozszerzenie przeglądarki lub zarejestruj się na platformie
- Przejdź do docelowej strony i otwórz narzędzie
- Wybierz elementy danych do wyodrębnienia metodą point-and-click
- Skonfiguruj selektory CSS dla każdego pola danych
- Ustaw reguły paginacji do scrapowania wielu stron
- Obsłuż CAPTCHA (często wymaga ręcznego rozwiązywania)
- Skonfiguruj harmonogram automatycznych uruchomień
- Eksportuj dane do CSV, JSON lub połącz przez API
Częste Wyzwania
- Krzywa uczenia: Zrozumienie selektorów i logiki ekstrakcji wymaga czasu
- Selektory się psują: Zmiany na stronie mogą zepsuć cały przepływ pracy
- Problemy z dynamiczną treścią: Strony bogate w JavaScript wymagają złożonych obejść
- Ograniczenia CAPTCHA: Większość narzędzi wymaga ręcznej interwencji przy CAPTCHA
- Blokowanie IP: Agresywne scrapowanie może prowadzić do zablokowania IP
Przykłady kodu
import requests
from bs4 import BeautifulSoup
import time
# Docelowy URL dla konkretnego pierwiastka (np. Złoto)
url = 'https://www.webelements.com/gold/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
def scrape_element(element_url):
try:
response = requests.get(element_url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Wyodrębnienie nazwy pierwiastka z tagu H1
name = soup.find('h1').get_text().strip()
# Wyodrębnienie liczby atomowej przy użyciu logiki etykiet tabeli
atomic_number = soup.find('th', string=lambda s: s and 'Atomic number' in s).find_next('td').text.strip()
print(f'Element: {name}, Atomic Number: {atomic_number}')
except Exception as e:
print(f'Wystąpił błąd: {e}')
# Zgodnie z rekomendacjami robots.txt
time.sleep(1)
scrape_element(url)Kiedy Używać
Najlepsze dla statycznych stron HTML z minimalnym JavaScript. Idealne dla blogów, serwisów informacyjnych i prostych stron produktowych e-commerce.
Zalety
- ●Najszybsze wykonanie (bez narzutu przeglądarki)
- ●Najniższe zużycie zasobów
- ●Łatwe do zrównoleglenia z asyncio
- ●Świetne dla API i stron statycznych
Ograniczenia
- ●Nie może wykonywać JavaScript
- ●Zawodzi na SPA i dynamicznej zawartości
- ●Może mieć problemy ze złożonymi systemami anti-bot
Jak scrapować WebElements za pomocą kodu
Python + Requests
import requests
from bs4 import BeautifulSoup
import time
# Docelowy URL dla konkretnego pierwiastka (np. Złoto)
url = 'https://www.webelements.com/gold/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
def scrape_element(element_url):
try:
response = requests.get(element_url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Wyodrębnienie nazwy pierwiastka z tagu H1
name = soup.find('h1').get_text().strip()
# Wyodrębnienie liczby atomowej przy użyciu logiki etykiet tabeli
atomic_number = soup.find('th', string=lambda s: s and 'Atomic number' in s).find_next('td').text.strip()
print(f'Element: {name}, Atomic Number: {atomic_number}')
except Exception as e:
print(f'Wystąpił błąd: {e}')
# Zgodnie z rekomendacjami robots.txt
time.sleep(1)
scrape_element(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Linki do pierwiastków znajdują się w głównym układzie okresowym
page.goto('https://www.webelements.com/iron/')
# Czekaj na obecność tabeli właściwości
page.wait_for_selector('table')
element_data = {
'name': page.inner_text('h1'),
'density': page.locator('th:has-text("Density") + td').inner_text().strip()
}
print(element_data)
browser.close()
run()Python + Scrapy
import scrapy
class ElementsSpider(scrapy.Spider):
name = 'elements'
start_urls = ['https://www.webelements.com/']
def parse(self, response):
# Podążaj za każdym linkiem do pierwiastka w układzie okresowym
for link in response.css('table a[title]::attr(href)'):
yield response.follow(link, self.parse_element)
def parse_element(self, response):
yield {
'name': response.css('h1::text').get().strip(),
'symbol': response.xpath('//th[contains(text(), "Symbol")]/following-sibling::td/text()').get().strip(),
'atomic_number': response.xpath('//th[contains(text(), "Atomic number")]/following-sibling::td/text()').get().strip(),
}Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.webelements.com/silver/');
const data = await page.evaluate(() => {
const name = document.querySelector('h1').innerText;
const meltingPoint = Array.from(document.querySelectorAll('th'))
.find(el => el.textContent.includes('Melting point'))
?.nextElementSibling.innerText;
return { name, meltingPoint };
});
console.log('Extracted Data:', data);
await browser.close();
})();Co Możesz Zrobić Z Danymi WebElements
Poznaj praktyczne zastosowania i wnioski z danych WebElements.
Trening AI w inżynierii materiałowej
Trenowanie modeli machine learning w celu przewidywania właściwości nowych stopów na podstawie cech pierwiastków.
Jak wdrożyć:
- 1Wyodrębnij właściwości fizyczne dla wszystkich elementów metalicznych.
- 2Wyczyść i znormalizuj wartości, takie jak gęstość i temperatura topnienia.
- 3Wprowadź dane do modeli regresji lub predykcyjnych modeli materiałowych.
- 4Zweryfikuj prognozy względem istniejących eksperymentalnych danych o stopach.
Użyj Automatio do wyodrębnienia danych z WebElements i budowania tych aplikacji bez pisania kodu.
Co Możesz Zrobić Z Danymi WebElements
- Trening AI w inżynierii materiałowej
Trenowanie modeli machine learning w celu przewidywania właściwości nowych stopów na podstawie cech pierwiastków.
- Wyodrębnij właściwości fizyczne dla wszystkich elementów metalicznych.
- Wyczyść i znormalizuj wartości, takie jak gęstość i temperatura topnienia.
- Wprowadź dane do modeli regresji lub predykcyjnych modeli materiałowych.
- Zweryfikuj prognozy względem istniejących eksperymentalnych danych o stopach.
- Zawartość aplikacji edukacyjnych
Zasilanie interaktywnych układów okresowych dla studentów chemii recenzowanymi danymi.
- Pobierz liczby atomowe, symbole i opisy pierwiastków.
- Wyodrębnij kontekst historyczny i szczegóły odkrycia.
- Uporządkuj dane według grup i bloków okresowych.
- Zintegruj z interfejsem użytkownika z wizualizacjami struktur krystalicznych.
- Analiza trendów chemicznych
Wizualizacja trendów okresowych, takich jak energia jonizacji czy promień atomowy w okresach i grupach.
- Zbierz dane o właściwościach każdego pierwiastka w kolejności numerycznej.
- Skategoryzuj pierwiastki do odpowiednich grup.
- Użyj bibliotek do wykresów, aby zwizualizować trendy.
- Zidentyfikuj i przeanalizuj nietypowe punkty danych w określonych blokach.
- Zarządzanie zapasami laboratoryjnymi
Automatyczne uzupełnianie systemów zarządzania chemikaliami o dane dotyczące bezpieczeństwa fizycznego i gęstości.
- Dopasuj wewnętrzną listę zapasów do wpisów w WebElements.
- Pobierz dane o gęstości, zagrożeniach związanych z przechowywaniem i temperaturze topnienia.
- Zaktualizuj scentralizowaną bazę danych laboratorium przez API.
- Generuj automatyczne ostrzeżenia o bezpieczeństwie dla pierwiastków wysokiego ryzyka.
Przyspiesz swoj workflow z automatyzacja AI
Automatio laczy moc agentow AI, automatyzacji web i inteligentnych integracji, aby pomoc Ci osiagnac wiecej w krotszym czasie.
Profesjonalne Porady dla Scrapowania WebElements
Porady ekspertów dotyczące skutecznej ekstrakcji danych z WebElements.
Przestrzegaj dyrektywy Crawl-delay
1 określonej w pliku robots.txt witryny.
Używaj liczby atomowej (Atomic Number) jako klucza głównego dla zachowania spójności bazy danych.
Pobieraj dane z podstron „history” i „compounds”, aby uzyskać pełny zestaw danych dla każdego pierwiastka.
Skoncentruj się na selektorach opartych na tabelach, ponieważ struktura strony jest bardzo tradycyjna i stabilna.
Weryfikuj dane z normami IUPAC, jeśli są używane do krytycznych badań naukowych.
Przechowuj wartości numeryczne, takie jak gęstość czy temperatura topnienia, jako typy float w celu łatwiejszej analizy.
Opinie
Co mowia nasi uzytkownicy
Dolacz do tysiecy zadowolonych uzytkownikow, ktorzy przeksztalcili swoj workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Powiazane Web Scraping

How to Scrape GitHub | The Ultimate 2025 Technical Guide

How to Scrape Pollen.com: Local Allergy Data Extraction Guide

How to Scrape Britannica: Educational Data Web Scraper

How to Scrape RethinkEd: A Technical Data Extraction Guide

How to Scrape Wikipedia: The Ultimate Web Scraping Guide

How to Scrape Weather.com: A Guide to Weather Data Extraction

How to Scrape Worldometers for Real-Time Global Statistics

How to Scrape American Museum of Natural History (AMNH)
Często Zadawane Pytania o WebElements
Znajdź odpowiedzi na częste pytania o WebElements