Como fazer Scraping do WebElements: Guia de Dados da Tabela Periódica
Extraia dados precisos de elementos químicos do WebElements. Faça scraping de pesos atômicos, propriedades físicas e histórico de descobertas para pesquisa e...
Sobre WebElements
Descubra o que WebElements oferece e quais dados valiosos podem ser extraídos.
O WebElements é uma tabela periódica online de excelência mantida por Mark Winter na Universidade de Sheffield. Lançado em 1993, foi a primeira tabela periódica na World Wide Web e, desde então, tornou-se um recurso de alta autoridade para estudantes, acadêmicos e químicos profissionais. O site oferece dados profundos e estruturados sobre cada elemento químico conhecido, desde pesos atômicos padrão até configurações eletrônicas complexas.
O valor de fazer scraping do WebElements reside em seus dados científicos de alta qualidade e revisados por pares. Para desenvolvedores que criam ferramentas educacionais, pesquisadores que realizam análises de tendências na tabela periódica ou cientistas de materiais que treinam machine learning model, o WebElements fornece uma fonte de verdade confiável e tecnicamente rica que é difícil de agregar manualmente.
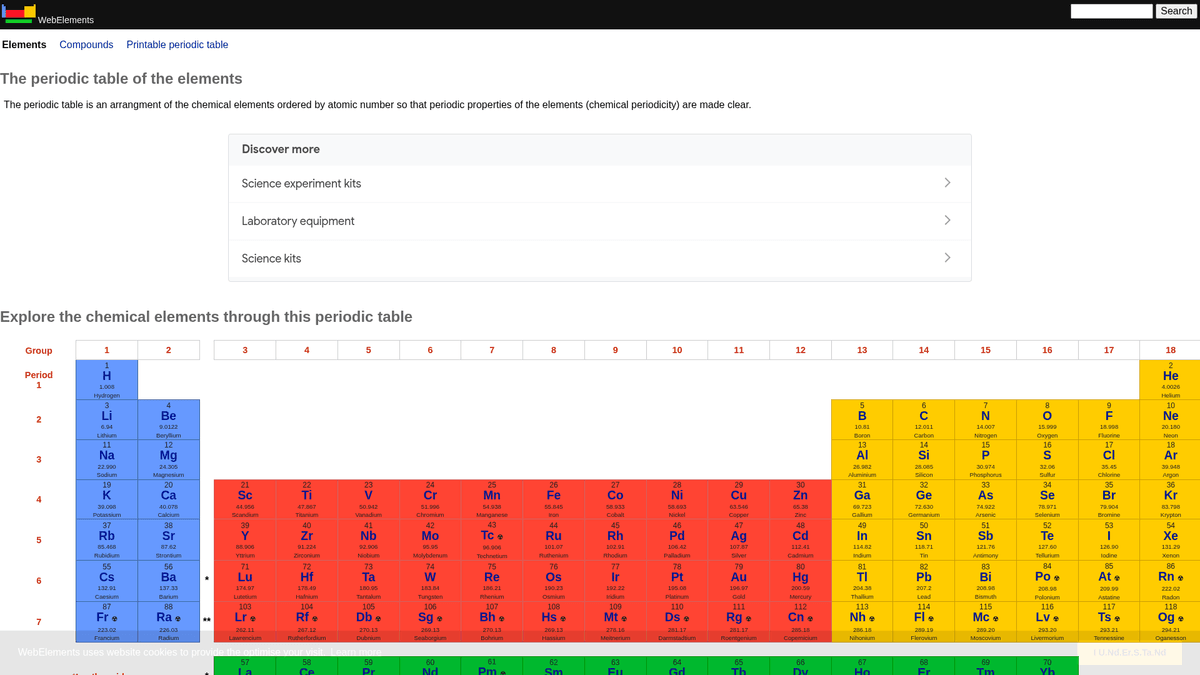
Por Que Fazer Scraping de WebElements?
Descubra o valor comercial e os casos de uso para extração de dados de WebElements.
População de Bancos de Dados Científicos
Agregue dados atômicos e químicos revisados por pares em bancos de dados centralizados para pesquisa acadêmica e análise de materiais em larga escala.
Desenvolvimento de Ferramentas Educacionais
Extraia fatos estruturados para alimentar aplicativos de tabela periódica personalizados, plataformas de aprendizagem móvel e flashcards interativos para salas de aula.
Modelagem Preditiva de Materiais
Colete propriedades numéricas como raios atômicos e eletronegatividade como recursos de treinamento para modelos de machine learning em ciência dos materiais.
Integração em Informática Química
Integre dados abrangentes de isótopos e termodinâmica diretamente em sistemas de gestão de laboratório e softwares de cálculo de estequiometria.
Linhas do Tempo Histórico-Científicas
Colete datas de descoberta, origem dos nomes e contexto histórico para todos os 118 elementos para criar cronologias científicas digitais.
Desafios do Scraping
Desafios técnicos que você pode encontrar ao fazer scraping de WebElements.
Estrutura de Subpáginas Fragmentada
Os dados de um único elemento são frequentemente divididos em múltiplas sub-URLs específicas como /atoms, /history ou /compounds, exigindo um rastreamento em múltiplas etapas.
Codificação de Símbolos Especiais
Analisar e armazenar corretamente notações científicas, sobrescritos, subscritos e caracteres gregos requer um manuseio rigoroso de UTF-8 para evitar corrupção de dados.
Requisitos de Normalização de Unidades
A extração de dados numéricos brutos exige a remoção programática de unidades como 'pm', 'K' ou 'g cm-3' e a conversão de notação científica em floats padrão.
Variações de Tabela Baseadas em Rótulos
Os dados são armazenados em tabelas genéricas sem IDs únicos, o que significa que os scrapers devem identificar os campos verificando o conteúdo de texto dos rótulos em vez de classes CSS.
Scrape WebElements com IA
Sem código necessário. Extraia dados em minutos com automação por IA.
Como Funciona
Descreva o que você precisa
Diga à IA quais dados você quer extrair de WebElements. Apenas digite em linguagem natural — sem código ou seletores.
A IA extrai os dados
Nossa inteligência artificial navega WebElements, lida com conteúdo dinâmico e extrai exatamente o que você pediu.
Obtenha seus dados
Receba dados limpos e estruturados prontos para exportar como CSV, JSON ou enviar diretamente para seus aplicativos.
Por Que Usar IA para Scraping
A IA facilita o scraping de WebElements sem escrever código. Nossa plataforma com inteligência artificial entende quais dados você quer — apenas descreva em linguagem natural e a IA os extrai automaticamente.
How to scrape with AI:
- Descreva o que você precisa: Diga à IA quais dados você quer extrair de WebElements. Apenas digite em linguagem natural — sem código ou seletores.
- A IA extrai os dados: Nossa inteligência artificial navega WebElements, lida com conteúdo dinâmico e extrai exatamente o que você pediu.
- Obtenha seus dados: Receba dados limpos e estruturados prontos para exportar como CSV, JSON ou enviar diretamente para seus aplicativos.
Why use AI for scraping:
- Mapeamento Visual de Dados: Use uma interface de apontar e clicar para mapear propriedades químicas complexas para campos de dados específicos sem escrever seletores CSS ou XPaths personalizados.
- Seguimento Recursivo de Links: Easily configure a ferramenta para visitar a tabela periódica principal e seguir automaticamente os links para cada elemento e suas subpáginas correspondentes.
- Limpeza Automática de Dados: Utilize ferramentas de formatação integradas para remover automaticamente unidades e símbolos científicos durante o processo de extração, garantindo saídas numéricas limpas.
- Monitoramento Agendado: Configure o scraper para rodar automaticamente em intervalos para capturar atualizações de pesos atômicos ou propriedades recém-descobertas conforme a IUPAC as confirma.
Scrapers Web No-Code para WebElements
Alternativas point-and-click ao scraping com IA
Várias ferramentas no-code como Browse.ai, Octoparse, Axiom e ParseHub podem ajudá-lo a fazer scraping de WebElements sem escrever código. Essas ferramentas usam interfaces visuais para selecionar dados, embora possam ter dificuldades com conteúdo dinâmico complexo ou medidas anti-bot.
Workflow Típico com Ferramentas No-Code
Desafios Comuns
Curva de aprendizado
Compreender seletores e lógica de extração leva tempo
Seletores quebram
Mudanças no site podem quebrar todo o fluxo de trabalho
Problemas com conteúdo dinâmico
Sites com muito JavaScript requerem soluções complexas
Limitações de CAPTCHA
A maioria das ferramentas requer intervenção manual para CAPTCHAs
Bloqueio de IP
Scraping agressivo pode resultar no bloqueio do seu IP
Scrapers Web No-Code para WebElements
Várias ferramentas no-code como Browse.ai, Octoparse, Axiom e ParseHub podem ajudá-lo a fazer scraping de WebElements sem escrever código. Essas ferramentas usam interfaces visuais para selecionar dados, embora possam ter dificuldades com conteúdo dinâmico complexo ou medidas anti-bot.
Workflow Típico com Ferramentas No-Code
- Instalar extensão do navegador ou registrar-se na plataforma
- Navegar até o site alvo e abrir a ferramenta
- Selecionar com point-and-click os elementos de dados a extrair
- Configurar seletores CSS para cada campo de dados
- Configurar regras de paginação para scraping de múltiplas páginas
- Resolver CAPTCHAs (frequentemente requer intervenção manual)
- Configurar agendamento para execuções automáticas
- Exportar dados para CSV, JSON ou conectar via API
Desafios Comuns
- Curva de aprendizado: Compreender seletores e lógica de extração leva tempo
- Seletores quebram: Mudanças no site podem quebrar todo o fluxo de trabalho
- Problemas com conteúdo dinâmico: Sites com muito JavaScript requerem soluções complexas
- Limitações de CAPTCHA: A maioria das ferramentas requer intervenção manual para CAPTCHAs
- Bloqueio de IP: Scraping agressivo pode resultar no bloqueio do seu IP
Exemplos de Código
import requests
from bs4 import BeautifulSoup
import time
# URL alvo para um elemento específico (ex: Ouro)
url = 'https://www.webelements.com/gold/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
def scrape_element(element_url):
try:
response = requests.get(element_url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Extraindo o nome do elemento da tag H1
name = soup.find('h1').get_text().strip()
# Extraindo o Número Atômico usando a lógica de rótulo da tabela
atomic_number = soup.find('th', string=lambda s: s and 'Atomic number' in s).find_next('td').text.strip()
print(f'Elemento: {name}, Número Atômico: {atomic_number}')
except Exception as e:
print(f'Ocorreu um erro: {e}')
# Seguindo as recomendações do robots.txt
time.sleep(1)
scrape_element(url)Quando Usar
Ideal para páginas HTML estáticas com JavaScript mínimo. Perfeito para blogs, sites de notícias e páginas de produtos e-commerce simples.
Vantagens
- ●Execução mais rápida (sem overhead do navegador)
- ●Menor consumo de recursos
- ●Fácil de paralelizar com asyncio
- ●Ótimo para APIs e páginas estáticas
Limitações
- ●Não pode executar JavaScript
- ●Falha em SPAs e conteúdo dinâmico
- ●Pode ter dificuldades com sistemas anti-bot complexos
Como Fazer Scraping de WebElements com Código
Python + Requests
import requests
from bs4 import BeautifulSoup
import time
# URL alvo para um elemento específico (ex: Ouro)
url = 'https://www.webelements.com/gold/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
def scrape_element(element_url):
try:
response = requests.get(element_url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Extraindo o nome do elemento da tag H1
name = soup.find('h1').get_text().strip()
# Extraindo o Número Atômico usando a lógica de rótulo da tabela
atomic_number = soup.find('th', string=lambda s: s and 'Atomic number' in s).find_next('td').text.strip()
print(f'Elemento: {name}, Número Atômico: {atomic_number}')
except Exception as e:
print(f'Ocorreu um erro: {e}')
# Seguindo as recomendações do robots.txt
time.sleep(1)
scrape_element(url)Python + Playwright
from playwright.sync_api import sync_playwright
def run():
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Elementos estão vinculados a partir da tabela periódica principal
page.goto('https://www.webelements.com/iron/')
# Aguarda a tabela de propriedades estar presente
page.wait_for_selector('table')
element_data = {
'name': page.inner_text('h1'),
'density': page.locator('th:has-text("Density") + td').inner_text().strip()
}
print(element_data)
browser.close()
run()Python + Scrapy
import scrapy
class ElementsSpider(scrapy.Spider):
name = 'elements'
start_urls = ['https://www.webelements.com/']
def parse(self, response):
# Segue cada link de elemento na tabela periódica
for link in response.css('table a[title]::attr(href)'):
yield response.follow(link, self.parse_element)
def parse_element(self, response):
yield {
'name': response.css('h1::text').get().strip(),
'symbol': response.xpath('//th[contains(text(), "Symbol")]/following-sibling::td/text()').get().strip(),
'atomic_number': response.xpath('//th[contains(text(), "Atomic number")]/following-sibling::td/text()').get().strip(),
}Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.webelements.com/silver/');
const data = await page.evaluate(() => {
const name = document.querySelector('h1').innerText;
const meltingPoint = Array.from(document.querySelectorAll('th'))
.find(el => el.textContent.includes('Melting point'))
?.nextElementSibling.innerText;
return { name, meltingPoint };
});
console.log('Dados Extraídos:', data);
await browser.close();
})();O Que Você Pode Fazer Com Os Dados de WebElements
Explore aplicações práticas e insights dos dados de WebElements.
Treinamento de AI em Ciência dos Materiais
Treinamento de machine learning model para prever as propriedades de novas ligas com base em atributos elementares.
Como implementar:
- 1Extrair propriedades físicas para todos os elementos metálicos.
- 2Limpar e normalizar valores como densidade e pontos de fusão.
- 3Inserir os dados em model de regressão ou preditivos de materiais.
- 4Verificar as previsões em relação aos dados experimentais de ligas existentes.
Use Automatio para extrair dados de WebElements e construir essas aplicações sem escrever código.
O Que Você Pode Fazer Com Os Dados de WebElements
- Treinamento de AI em Ciência dos Materiais
Treinamento de machine learning model para prever as propriedades de novas ligas com base em atributos elementares.
- Extrair propriedades físicas para todos os elementos metálicos.
- Limpar e normalizar valores como densidade e pontos de fusão.
- Inserir os dados em model de regressão ou preditivos de materiais.
- Verificar as previsões em relação aos dados experimentais de ligas existentes.
- Conteúdo para Aplicativos Educacionais
Popular tabelas periódicas interativas para estudantes de química com dados revisados por pares.
- Fazer o scraping de números atômicos, símbolos e descrições de elementos.
- Extrair o contexto histórico e detalhes da descoberta.
- Organizar os dados por grupo periódico e bloco.
- Integrar em uma interface de usuário com estruturas de cristal visuais.
- Análise de Tendências Químicas
Visualização de tendências periódicas como energia de ionização ou raio atômico através de períodos e grupos.
- Reunir dados de propriedades para cada elemento em ordem numérica.
- Categorizar os elementos em seus respectivos grupos.
- Usar bibliotecas de gráficos para visualizar tendências.
- Identificar e analisar pontos de dados anômalos em blocos específicos.
- Gestão de Inventário de Laboratório
População automática de sistemas de gestão química com dados de segurança física e densidade.
- Mapear a lista de inventário interno para as entradas do WebElements.
- Extrair dados de densidade, riscos de armazenamento e ponto de fusão.
- Atualizar o banco de dados centralizado do laboratório via API.
- Gerar avisos de segurança automatizados para elementos de alto risco.
Potencialize seu fluxo de trabalho com Automacao de IA
Automatio combina o poder de agentes de IA, automacao web e integracoes inteligentes para ajuda-lo a realizar mais em menos tempo.
Dicas Pro para Scraping de WebElements
Dicas de especialistas para extrair dados com sucesso de WebElements.
Aproveite Padrões de URL Previsíveis
Os elementos seguem uma estrutura /element_name/ consistente, permitindo gerar URLs de destino programaticamente para todos os 118 elementos em vez de fazer o crawling da página inicial.
Identifique Dados via Sibling Selectors
Como o site carece de IDs de elementos únicos, identifique os pontos de dados localizando o texto da célula de rótulo (ex: 'Melting point') e selecionando o 'td' sibling imediato.
Garanta Suporte a UTF-8
Sempre configure seu ambiente de scraping para UTF-8 para capturar corretamente caracteres científicos como Å, ± e letras gregas comuns em notação química.
Implemente Crawl Delays
Como este é um recurso acadêmico hospedado pela University of Sheffield, a melhor prática é seguir o delay de 1 segundo do robots.txt para evitar sobrecarregar o servidor.
Foque em Subpáginas Granulares
Para dados de alta precisão, como a meia-vida de isótopos específicos, faça o scraping das subpáginas dedicadas /isotopes.html em vez das páginas de resumo para melhor acurácia.
Depoimentos
O Que Nossos Usuarios Dizem
Junte-se a milhares de usuarios satisfeitos que transformaram seu fluxo de trabalho
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relacionados Web Scraping

How to Scrape GitHub | The Ultimate 2025 Technical Guide

How to Scrape Pollen.com: Local Allergy Data Extraction Guide

How to Scrape Britannica: Educational Data Web Scraper

How to Scrape RethinkEd: A Technical Data Extraction Guide

How to Scrape Wikipedia: The Ultimate Web Scraping Guide

How to Scrape Weather.com: A Guide to Weather Data Extraction

How to Scrape Worldometers for Real-Time Global Statistics

How to Scrape American Museum of Natural History (AMNH)
Perguntas Frequentes Sobre WebElements
Encontre respostas para perguntas comuns sobre WebElements