วิธีสแครป Pollen.com: คู่มือการดึงข้อมูลภูมิแพ้ในท้องถิ่น
เรียนรู้วิธีสแครป Pollen.com เพื่อดึงข้อมูลพยากรณ์ภูมิแพ้ในท้องถิ่น ระดับละอองเกสร และสารก่อภูมิแพ้อันดับต้นๆ รับข้อมูลสุขภาพรายวันเพื่อการวิจัยและแอปพลิเคชันตร...
ตรวจพบการป้องกันบอท
- Cloudflare
- WAF และการจัดการบอทระดับองค์กร ใช้ JavaScript challenges, CAPTCHAs และการวิเคราะห์พฤติกรรม ต้องมีระบบอัตโนมัติของเบราว์เซอร์พร้อมการตั้งค่าซ่อนตัว
- การจำกัดอัตรา
- จำกัดคำขอต่อ IP/เซสชันตามเวลา สามารถหลีกเลี่ยงได้ด้วยพร็อกซีหมุนเวียน การหน่วงเวลาคำขอ และการสแกรปแบบกระจาย
- การบล็อก IP
- บล็อก IP ของศูนย์ข้อมูลที่รู้จักและที่อยู่ที่ถูกทำเครื่องหมาย ต้องใช้พร็อกซีที่อยู่อาศัยหรือมือถือเพื่อหลีกเลี่ยงอย่างมีประสิทธิภาพ
- AngularJS Rendering
เกี่ยวกับ Pollen.com
ค้นพบสิ่งที่ Pollen.com นำเสนอและข้อมูลที่มีค่าที่สามารถดึงได้
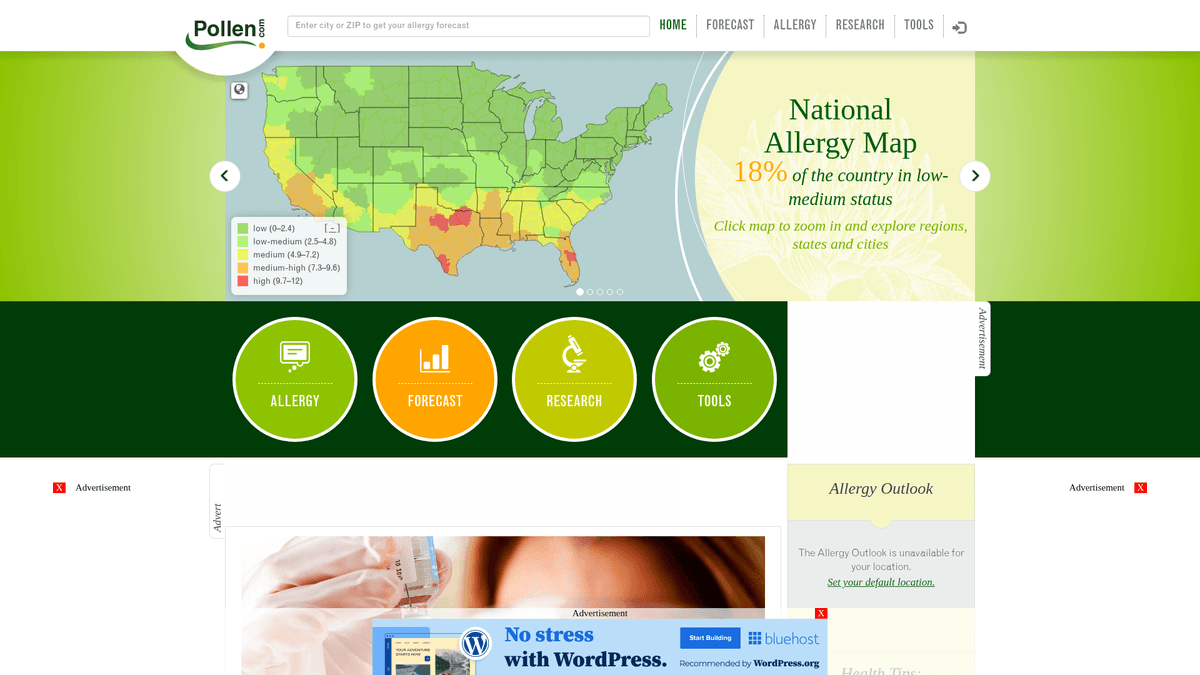
ข้อมูลภูมิแพ้ที่ครอบคลุมสำหรับสหรัฐอเมริกา
Pollen.com เป็นพอร์ทัลสุขภาพสิ่งแวดล้อมชั้นนำที่ให้ข้อมูลภูมิแพ้และการพยากรณ์ที่เจาะจงในแต่ละพื้นที่ทั่วสหรัฐอเมริกา เว็บไซต์นี้เป็นเจ้าของและดำเนินการโดย IQVIA ซึ่งเป็นบริษัทวิเคราะห์ข้อมูลด้านสุขภาพที่มีชื่อเสียง แพลตฟอร์มนี้แสดงจำนวนละอองเกสรและประเภทของสารก่อภูมิแพ้ตามรหัสไปรษณีย์ โดยถือเป็นทรัพยากรที่สำคัญสำหรับบุคคลที่จัดการกับภาวะทางเดินหายใจตามฤดูกาลและบุคลากรทางการแพทย์ที่ติดตามแนวโน้มด้านสุขภาพสิ่งแวดล้อม
ข้อมูลที่มีคุณค่าต่อสาธารณสุข
เว็บไซต์ประกอบด้วยข้อมูลที่มีโครงสร้างซึ่งรวมถึงดัชนีละอองเกสรตั้งแต่ 0 ถึง 12 หมวดหมู่ของสารก่อภูมิแพ้อันดับต้นๆ เช่น ต้นไม้ วัชพืช และหญ้า รวมถึงการพยากรณ์ล่วงหน้า 5 วันอย่างละเอียด สำหรับนักพัฒนาและนักวิจัย ข้อมูลนี้จะช่วยให้เข้าใจถึงตัวกระตุ้นทางสิ่งแวดล้อมในแต่ละภูมิภาคและรูปแบบภูมิแพ้ในอดีต ซึ่งยากต่อการรวบรวมจากเว็บไซต์พยากรณ์อากาศทั่วไป
ประโยชน์ทางธุรกิจและการวิจัย
การสแครป Pollen.com มีประโยชน์ในการสร้างแอปพลิเคชันตรวจสอบสุขภาพ การเพิ่มประสิทธิภาพซัพพลายเชนเภสัชกรรมสำหรับยาแก้แพ้ และการวิจัยทางวิชาการเกี่ยวกับผลกระทบของการเปลี่ยนแปลงสภาพภูมิอากาศต่อรอบการผสมเกสร ด้วยการดึงข้อมูลเหล่านี้โดยอัตโนมัติ องค์กรต่างๆ จะสามารถมอบคุณค่าแบบเรียลไทม์ให้กับผู้ที่ประสบปัญหาภูมิแพ้ทั่วประเทศได้
ทำไมต้อง Scrape Pollen.com?
ค้นพบคุณค่าทางธุรกิจและกรณีการใช้งานสำหรับการดึงข้อมูลจาก Pollen.com
สร้างระบบแจ้งเตือนภูมิแพ้ส่วนบุคคลสำหรับแอปพลิเคชันด้านสุขภาพ
คาดการณ์แนวโน้มความต้องการยารักษาโรคภูมิแพ้ในระดับท้องถิ่น
ดำเนินการวิจัยด้านสิ่งแวดล้อมเกี่ยวกับฤดูกาลผสมเกสรในแต่ละภูมิภาค
รวบรวมข้อมูลสุขภาพระดับท้องถิ่นสำหรับพอร์ทัลข่าวและสภาพอากาศ
วิเคราะห์รูปแบบภูมิแพ้ในอดีตเพื่อการวางแผนสาธารณสุขในเขตเมือง
ความท้าทายในการ Scrape
ความท้าทายทางเทคนิคที่คุณอาจพบเมื่อ Scrape Pollen.com
การแสดงผลเนื้อหาแบบไดนามิกโดยใช้ AngularJS จำเป็นต้องมี browser automation หรือเครื่องมือสแครปแบบ headless
ข้อมูลพยากรณ์หลักถูกโหลดผ่านการเรียกใช้ internal API แบบอะซิงโครนัสที่มีการป้องกันเซสชัน
มีการจำกัดอัตรา (rate limiting) ที่เข้มงวดสำหรับการค้นหารหัสไปรษณีย์ทางภูมิศาสตร์ซ้ำๆ ซึ่งอาจนำไปสู่การแบน IP ชั่วคราว
การป้องกันบอทของ Cloudflare มักจะสร้างความท้าทายให้กับ user agents ที่ไม่ใช่เบราว์เซอร์
สกัดข้อมูลจาก Pollen.com ด้วย AI
ไม่ต้องเขียนโค้ด สกัดข้อมูลภายในไม่กี่นาทีด้วยระบบอัตโนมัติที่ขับเคลื่อนด้วย AI
วิธีการทำงาน
อธิบายสิ่งที่คุณต้องการ
บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก Pollen.com แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
AI สกัดข้อมูล
ปัญญาประดิษฐ์ของเรานำทาง Pollen.com จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
รับข้อมูลของคุณ
รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
ทำไมต้องใช้ AI ในการสกัดข้อมูล
AI ทำให้การสกัดข้อมูลจาก Pollen.com เป็นเรื่องง่ายโดยไม่ต้องเขียนโค้ด แพลตฟอร์มที่ขับเคลื่อนด้วยปัญญาประดิษฐ์ของเราเข้าใจว่าคุณต้องการข้อมูลอะไร — แค่อธิบายเป็นภาษาธรรมชาติ แล้ว AI จะสกัดให้โดยอัตโนมัติ
How to scrape with AI:
- อธิบายสิ่งที่คุณต้องการ: บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก Pollen.com แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
- AI สกัดข้อมูล: ปัญญาประดิษฐ์ของเรานำทาง Pollen.com จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
- รับข้อมูลของคุณ: รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
Why use AI for scraping:
- การแสดงผล JavaScript อัตโนมัติช่วยจัดการข้อมูลแผนภูมิ AngularJS ที่ซับซ้อนโดยไม่ต้องเขียนโค้ดเพิ่มเติม
- การหมุนเวียนพร็อกซี่ในตัวช่วยข้ามการรักษาความปลอดภัยของ Cloudflare และการจำกัดอัตราตาม IP ได้สำเร็จ
- การตั้งเวลาทำงานช่วยให้สามารถรวบรวมข้อมูลรายวันได้โดยอัตโนมัติจากรหัสไปรษณีย์นับพันแห่ง
- อินเทอร์เฟซแบบ no-code ทำให้ง่ายต่อการตั้งค่าการดึงข้อมูลสำหรับภูมิภาคที่ต้องการ
No-code web scrapers สำหรับ Pollen.com
ทางเลือกแบบ point-and-click สำหรับการ scraping ด้วย AI
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape Pollen.com โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
ความท้าทายทั่วไป
เส้นโค้งการเรียนรู้
การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
Selectors เสีย
การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
ปัญหาเนื้อหาไดนามิก
เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
ข้อจำกัด CAPTCHA
เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
การบล็อก IP
การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
No-code web scrapers สำหรับ Pollen.com
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape Pollen.com โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
- ติดตั้งส่วนขยายเบราว์เซอร์หรือสมัครใช้งานแพลตฟอร์ม
- นำทางไปยังเว็บไซต์เป้าหมายและเปิดเครื่องมือ
- เลือกองค์ประกอบข้อมูลที่ต้องการดึงด้วยการชี้และคลิก
- กำหนดค่า CSS selectors สำหรับแต่ละฟิลด์ข้อมูล
- ตั้งค่ากฎการแบ่งหน้าเพื่อ scrape หลายหน้า
- จัดการ CAPTCHA (มักต้องแก้ไขด้วยตนเอง)
- กำหนดค่าการตั้งเวลาสำหรับการรันอัตโนมัติ
- ส่งออกข้อมูลเป็น CSV, JSON หรือเชื่อมต่อผ่าน API
ความท้าทายทั่วไป
- เส้นโค้งการเรียนรู้: การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
- Selectors เสีย: การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
- ปัญหาเนื้อหาไดนามิก: เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
- ข้อจำกัด CAPTCHA: เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
- การบล็อก IP: การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
ตัวอย่างโค้ด
import requests
from bs4 import BeautifulSoup
# หมายเหตุ: โค้ดนี้จะดึงเฉพาะข้อมูลเมตาของข่าวที่เป็นแบบสถิต (static)
# ข้อมูลพยากรณ์หลักจำเป็นต้องใช้การแสดงผล JavaScript หรือการเข้าถึง internal API โดยตรง
url = 'https://www.pollen.com/forecast/current/pollen/20001'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# ดึงหัวข้อข่าวเบื้องต้นจากแถบด้านข้าง
news = [a.text.strip() for a in soup.select('article h2 a')]
print(f'Latest Allergy News: {news}')
except Exception as e:
print(f'Error occurred: {e}')เมื่อไหร่ควรใช้
เหมาะที่สุดสำหรับหน้า HTML แบบ static ที่มี JavaScript น้อย เหมาะสำหรับบล็อก ไซต์ข่าว และหน้าสินค้า e-commerce ธรรมดา
ข้อดี
- ●ประมวลผลเร็วที่สุด (ไม่มี overhead ของเบราว์เซอร์)
- ●ใช้ทรัพยากรน้อยที่สุด
- ●ง่ายต่อการทำงานแบบขนานด้วย asyncio
- ●เหมาะมากสำหรับ API และหน้า static
ข้อจำกัด
- ●ไม่สามารถรัน JavaScript ได้
- ●ล้มเหลวใน SPA และเนื้อหาไดนามิก
- ●อาจมีปัญหากับระบบ anti-bot ที่ซับซ้อน
วิธีสเครปข้อมูล Pollen.com ด้วยโค้ด
Python + Requests
import requests
from bs4 import BeautifulSoup
# หมายเหตุ: โค้ดนี้จะดึงเฉพาะข้อมูลเมตาของข่าวที่เป็นแบบสถิต (static)
# ข้อมูลพยากรณ์หลักจำเป็นต้องใช้การแสดงผล JavaScript หรือการเข้าถึง internal API โดยตรง
url = 'https://www.pollen.com/forecast/current/pollen/20001'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# ดึงหัวข้อข่าวเบื้องต้นจากแถบด้านข้าง
news = [a.text.strip() for a in soup.select('article h2 a')]
print(f'Latest Allergy News: {news}')
except Exception as e:
print(f'Error occurred: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def run(playwright):
browser = playwright.chromium.launch(headless=True)
page = browser.new_page()
# ไปที่หน้าพยากรณ์ของรหัสไปรษณีย์เฉพาะ
page.goto('https://www.pollen.com/forecast/current/pollen/20001')
# รอให้ AngularJS แสดงผลดัชนีละอองเกสรแบบไดนามิก
page.wait_for_selector('.forecast-level')
data = {
'pollen_index': page.inner_text('.forecast-level'),
'status': page.inner_text('.forecast-level-desc'),
'allergens': [el.inner_text() for el in page.query_selector_all('.top-allergen-item span')]
}
print(f'Data for 20001: {data}')
browser.close()
with sync_playwright() as playwright:
run(playwright)Python + Scrapy
import scrapy
class PollenSpider(scrapy.Spider):
name = 'pollen_spider'
start_urls = ['https://www.pollen.com/forecast/current/pollen/20001']
def parse(self, response):
# สำหรับเนื้อหาแบบไดนามิก ให้ใช้ Scrapy-Playwright หรือมิดเดิลแวร์ที่ใกล้เคียงกัน
# วิธี parse มาตรฐานนี้จะจัดการกับองค์ประกอบคงที่ เช่น หัวข้อข่าว
yield {
'url': response.url,
'page_title': response.css('title::text').get(),
'news_headlines': response.css('article h2 a::text').getall()
}Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
// ตั้งค่า User-Agent เพื่อเลียนแบบเบราว์เซอร์จริง
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64)');
await page.goto('https://www.pollen.com/forecast/current/pollen/20001');
// รอให้ระดับพยากรณ์แบบไดนามิกปรากฏขึ้น
await page.waitForSelector('.forecast-level');
const data = await page.evaluate(() => ({
pollenIndex: document.querySelector('.forecast-level')?.innerText,
description: document.querySelector('.forecast-level-desc')?.innerText,
location: document.querySelector('h1')?.innerText
}));
console.log(data);
await browser.close();
})();คุณสามารถทำอะไรกับข้อมูล Pollen.com
สำรวจการใช้งานจริงและข้อมูลเชิงลึกจากข้อมูล Pollen.com
การแจ้งเตือนภูมิแพ้ส่วนบุคคล
แอปพลิเคชันสุขภาพบนมือถือสามารถให้การแจ้งเตือนแบบเรียลไทม์แก่ผู้ใช้เมื่อจำนวนละอองเกสรถึงระดับสูงในพื้นที่เฉพาะของตน
วิธีการนำไปใช้:
- 1สแครปข้อมูลพยากรณ์รายวันสำหรับรหัสไปรษณีย์ที่ผู้ใช้ส่งเข้ามา
- 2ระบุเมื่อดัชนีละอองเกสรเกินเกณฑ์ 'High' (7.3+)
- 3ส่งการแจ้งเตือนแบบพุชอัตโนมัติหรือ SMS แจ้งเตือนไปยังผู้ใช้
ใช้ Automatio เพื่อดึงข้อมูลจาก Pollen.com และสร้างแอปพลิเคชันเหล่านี้โดยไม่ต้องเขียนโค้ด
คุณสามารถทำอะไรกับข้อมูล Pollen.com
- การแจ้งเตือนภูมิแพ้ส่วนบุคคล
แอปพลิเคชันสุขภาพบนมือถือสามารถให้การแจ้งเตือนแบบเรียลไทม์แก่ผู้ใช้เมื่อจำนวนละอองเกสรถึงระดับสูงในพื้นที่เฉพาะของตน
- สแครปข้อมูลพยากรณ์รายวันสำหรับรหัสไปรษณีย์ที่ผู้ใช้ส่งเข้ามา
- ระบุเมื่อดัชนีละอองเกสรเกินเกณฑ์ 'High' (7.3+)
- ส่งการแจ้งเตือนแบบพุชอัตโนมัติหรือ SMS แจ้งเตือนไปยังผู้ใช้
- การพยากรณ์ความต้องการยา
ผู้ค้าปลีกยาสามารถปรับระดับสต็อกสินค้าให้เหมาะสมโดยการเชื่อมโยงการพุ่งสูงขึ้นของละอองเกสรในท้องถิ่นเข้ากับความต้องการยาแก้แพ้ที่คาดการณ์ไว้
- ดึงข้อมูลพยากรณ์ล่วงหน้า 5 วันจากภูมิภาคหลักๆ ทั่วประเทศ
- ระบุช่วงเวลาที่กำลังจะมาถึงซึ่งมีกิจกรรมของสารก่อภูมิแพ้สูง
- ประสานงานการกระจายสินค้าไปยังร้านขายยาในท้องถิ่นก่อนที่จะถึงช่วงพีค
- การให้คะแนนด้านสิ่งแวดล้อมของอสังหาริมทรัพย์
เว็บไซต์ประกาศขายบ้านสามารถเพิ่ม 'ระดับภูมิแพ้' เพื่อช่วยให้ผู้ซื้อที่ไวต่อสภาพอากาศประเมินคุณภาพอากาศในย่านนั้นๆ ได้
- รวบรวมข้อมูลละอองเกสรย้อนหลังสำหรับย่านต่างๆ ในเมือง
- คำนวณคะแนนความเข้มข้นของละอองเกสรเฉลี่ยต่อปี
- แสดงคะแนนเป็นฟีเจอร์ที่กำหนดเองบนหน้าข้อมูลรายละเอียดอสังหาริมทรัพย์
- การวิจัยด้านการเปลี่ยนแปลงสภาพภูมิอากาศ
นักวิทยาศาสตร์สิ่งแวดล้อมสามารถติดตามระยะเวลาและความเข้มข้นของฤดูกาลผสมเกสรเมื่อเวลาผ่านไปเพื่อศึกษาผลกระทบของสภาพภูมิอากาศ
- สแครปชนิดและดัชนีละอองเกสรรายวันตลอดฤดูใบไม้ผลิและฤดูใบไม้ร่วง
- เปรียบเทียบวันที่เริ่มต้นและสิ้นสุดของการแพร่กระจายเกสรกับค่าเฉลี่ยในอดีต
- วิเคราะห์ข้อมูลเพื่อหาแนวโน้มที่บ่งชี้ถึงฤดูกาลภูมิแพ้ที่ยาวนานขึ้นหรือรุนแรงขึ้น
เพิ่มพลังให้เวิร์กโฟลว์ของคุณด้วย ระบบอัตโนมัติ AI
Automatio รวมพลังของ AI agents การอัตโนมัติเว็บ และการผสานรวมอัจฉริยะเพื่อช่วยให้คุณทำงานได้มากขึ้นในเวลาน้อยลง
เคล็ดลับมืออาชีพสำหรับการ Scrape Pollen.com
คำแนะนำจากผู้เชี่ยวชาญสำหรับการดึงข้อมูลจาก Pollen.com อย่างประสบความสำเร็จ
มุ่งเป้าไปที่จุดเชื่อมต่อ API ภายในที่พบในทราฟฟิกเครือข่ายเพื่อเข้าถึงข้อมูล JSON โดยตรง
ใช้ residential proxies เพื่อหมุนเวียนที่อยู่ IP ของคุณและหลีกเลี่ยงการเปิดใช้งานระบบป้องกันบอทของ Cloudflare
สแครปข้อมูลทุกวันในช่วงเช้าตรู่ (ประมาณ 7
00 น. EST) เพื่อรับข้อมูลการพยากรณ์ที่อัปเดตล่าสุด
ตรวจสอบให้แน่ใจว่าเครื่องมือสแครปข้อมูลของคุณสามารถรัน JavaScript ได้ เนื่องจาก Pollen.com ใช้ AngularJS ในการแสดงตัวเลขดัชนี
กำหนดให้มีการหน่วงเวลาแบบสุ่ม (random sleep delay) ระหว่าง 3-10 วินาทีในระหว่างการส่งคำขอรหัสไปรษณีย์ที่แตกต่างกัน
หมุนเวียนการตรวจสอบโครงสร้างเว็บไซต์อย่างสม่ำเสมอ เนื่องจากชื่อคลาสของ AngularJS อาจเปลี่ยนแปลงระหว่างการอัปเดตไซต์
คำรับรอง
ผู้ใช้ของเราพูดอย่างไร
เข้าร่วมกับผู้ใช้ที่พึงพอใจนับพันที่ได้เปลี่ยนแปลงเวิร์กโฟลว์ของพวกเขา
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
ที่เกี่ยวข้อง Web Scraping

How to Scrape GitHub | The Ultimate 2025 Technical Guide

How to Scrape RethinkEd: A Technical Data Extraction Guide

How to Scrape Britannica: Educational Data Web Scraper

How to Scrape Worldometers for Real-Time Global Statistics

How to Scrape Wikipedia: The Ultimate Web Scraping Guide

How to Scrape Weather.com: A Guide to Weather Data Extraction

How to Scrape American Museum of Natural History (AMNH)

How to Scrape Poll-Maker: A Comprehensive Web Scraping Guide
คำถามที่พบบ่อยเกี่ยวกับ Pollen.com
ค้นหาคำตอบสำหรับคำถามทั่วไปเกี่ยวกับ Pollen.com