วิธี Scrape We Work Remotely: คู่มือฉบับสมบูรณ์
เรียนรู้วิธี scrape รายการประกาศรับสมัครงานจาก We Work Remotely ดึงข้อมูลชื่อตำแหน่ง, บริษัท, เงินเดือน และอื่นๆ เพื่อการวิจัยตลาดหรือสร้างระบบรวบรวมงานของคุณเอ...
ตรวจพบการป้องกันบอท
- Cloudflare
- WAF และการจัดการบอทระดับองค์กร ใช้ JavaScript challenges, CAPTCHAs และการวิเคราะห์พฤติกรรม ต้องมีระบบอัตโนมัติของเบราว์เซอร์พร้อมการตั้งค่าซ่อนตัว
- การบล็อก IP
- บล็อก IP ของศูนย์ข้อมูลที่รู้จักและที่อยู่ที่ถูกทำเครื่องหมาย ต้องใช้พร็อกซีที่อยู่อาศัยหรือมือถือเพื่อหลีกเลี่ยงอย่างมีประสิทธิภาพ
- การจำกัดอัตรา
- จำกัดคำขอต่อ IP/เซสชันตามเวลา สามารถหลีกเลี่ยงได้ด้วยพร็อกซีหมุนเวียน การหน่วงเวลาคำขอ และการสแกรปแบบกระจาย
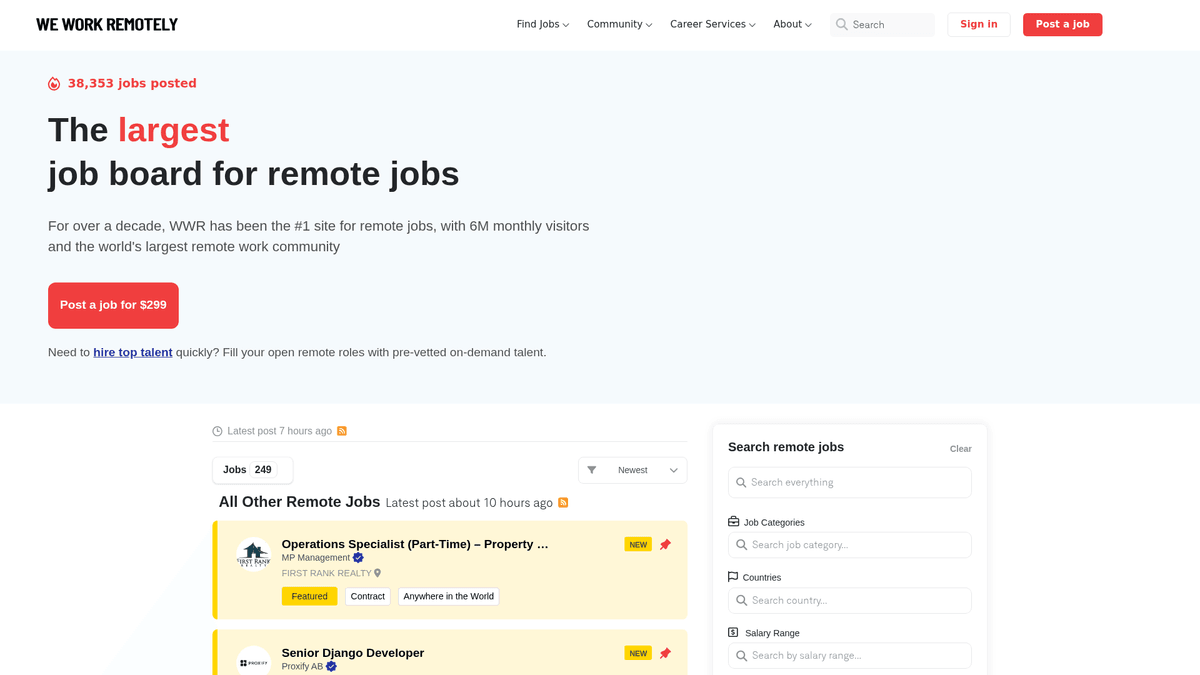
เกี่ยวกับ We Work Remotely
ค้นพบสิ่งที่ We Work Remotely นำเสนอและข้อมูลที่มีค่าที่สามารถดึงได้
ศูนย์รวมบุคลากรที่ทำงานทางไกลจากทั่วโลก
We Work Remotely (WWR) เป็นชุมชนการทำงานทางไกลที่ก่อตั้งมานานที่สุดในโลก โดยมีผู้เข้าชมมากกว่า 6 ล้านคนต่อเดือน เป็นจุดหมายปลายทางหลักสำหรับบริษัทที่กำลังเปลี่ยนผ่านจากโมเดลการทำงานในออฟฟิศแบบเดิม มาเป็นการนำเสนอตำแหน่งงานที่หลากหลายทั้งในด้าน software development, การออกแบบ, การตลาด และส่วนงานสนับสนุนลูกค้า
ข้อมูลที่มีโครงสร้างคุณภาพสูง
แพลตฟอร์มนี้ขึ้นชื่อเรื่องข้อมูลที่มีโครงสร้างสูง แต่ละรายการประกาศมักประกอบด้วยข้อกำหนดเฉพาะของภูมิภาค ช่วงเงินเดือน และโปรไฟล์บริษัทที่ละเอียด โครงสร้างนี้ทำให้ที่นี่เป็นเป้าหมายที่เหมาะสมที่สุดสำหรับ web scraping เนื่องจากข้อมูลมีความสม่ำเสมอและง่ายต่อการจัดหมวดหมู่เพื่อนำไปใช้งานต่อ
มูลค่าเชิงกลยุทธ์สำหรับผู้เชี่ยวชาญด้านข้อมูล
สำหรับผู้สรรหาบุคลากรและนักวิจัยตลาด WWR คือขุมทรัพย์ข้อมูล การ scrape ไซต์นี้ช่วยให้สามารถติดตามเทรนด์การจ้างงานแบบเรียลไทม์ การทำ benchmark เงินเดือนในภาคเทคโนโลยีต่างๆ และการสร้างลีด (lead generation) สำหรับบริการ B2B ที่เน้นกลุ่มบริษัท remote-first โดยให้มุมมองที่โปร่งใสของตลาดแรงงานทางไกลทั่วโลก
ทำไมต้อง Scrape We Work Remotely?
ค้นพบคุณค่าทางธุรกิจและกรณีการใช้งานสำหรับการดึงข้อมูลจาก We Work Remotely
สร้างระบบรวบรวมงานทางไกลเฉพาะกลุ่มหรือพอร์ทัลหางาน
วิเคราะห์เปรียบเทียบเงินเดือนในอุตสาหกรรมต่างๆ
ระบุบริษัทที่กำลังขยายทีมทางไกลอย่างรวดเร็ว
ติดตามความต้องการทักษะทางเทคนิคเฉพาะด้านทั่วโลก
สร้างลีดสำหรับผู้ให้บริการเทคโนโลยีด้าน HR และสวัสดิการ
ความท้าทายในการ Scrape
ความท้าทายทางเทคนิคที่คุณอาจพบเมื่อ Scrape We Work Remotely
การตรวจจับของระบบป้องกัน anti-bot ของ Cloudflare
ความไม่สม่ำเสมอของการใส่ Tag สถานที่
การแยกข้อมูลเงินเดือนที่มีรูปแบบหลากหลายในคำอธิบาย
การจัดการ IP rate limits ระหว่างการ crawl หน้ารายละเอียดปริมาณมาก
สกัดข้อมูลจาก We Work Remotely ด้วย AI
ไม่ต้องเขียนโค้ด สกัดข้อมูลภายในไม่กี่นาทีด้วยระบบอัตโนมัติที่ขับเคลื่อนด้วย AI
วิธีการทำงาน
อธิบายสิ่งที่คุณต้องการ
บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก We Work Remotely แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
AI สกัดข้อมูล
ปัญญาประดิษฐ์ของเรานำทาง We Work Remotely จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
รับข้อมูลของคุณ
รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
ทำไมต้องใช้ AI ในการสกัดข้อมูล
AI ทำให้การสกัดข้อมูลจาก We Work Remotely เป็นเรื่องง่ายโดยไม่ต้องเขียนโค้ด แพลตฟอร์มที่ขับเคลื่อนด้วยปัญญาประดิษฐ์ของเราเข้าใจว่าคุณต้องการข้อมูลอะไร — แค่อธิบายเป็นภาษาธรรมชาติ แล้ว AI จะสกัดให้โดยอัตโนมัติ
How to scrape with AI:
- อธิบายสิ่งที่คุณต้องการ: บอก AI ว่าคุณต้องการสกัดข้อมูลอะไรจาก We Work Remotely แค่พิมพ์เป็นภาษาธรรมชาติ — ไม่ต้องเขียนโค้ดหรือตัวเลือก
- AI สกัดข้อมูล: ปัญญาประดิษฐ์ของเรานำทาง We Work Remotely จัดการเนื้อหาแบบไดนามิก และสกัดข้อมูลตรงตามที่คุณต้องการ
- รับข้อมูลของคุณ: รับข้อมูลที่สะอาดและมีโครงสร้างพร้อมส่งออกเป็น CSV, JSON หรือส่งตรงไปยังแอปของคุณ
Why use AI for scraping:
- ตั้งค่าการ scrape แบบ no-code ผ่านอินเทอร์เฟซแบบภาพ
- จัดการมาตรการ anti-bot และ proxies โดยอัตโนมัติ
- ตั้งเวลาทำงานเพื่ออัปเดตบอร์ดงานแบบเรียลไทม์
- ส่งออกข้อมูลไปยัง JSON, CSV หรือ Google Sheets โดยตรง
- รันบนคลาวด์โดยไม่ใช้ทรัพยากรเครื่องโลคอล
No-code web scrapers สำหรับ We Work Remotely
ทางเลือกแบบ point-and-click สำหรับการ scraping ด้วย AI
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape We Work Remotely โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
ความท้าทายทั่วไป
เส้นโค้งการเรียนรู้
การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
Selectors เสีย
การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
ปัญหาเนื้อหาไดนามิก
เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
ข้อจำกัด CAPTCHA
เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
การบล็อก IP
การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
No-code web scrapers สำหรับ We Work Remotely
เครื่องมือ no-code หลายตัวเช่น Browse.ai, Octoparse, Axiom และ ParseHub สามารถช่วยคุณ scrape We Work Remotely โดยไม่ต้องเขียนโค้ด เครื่องมือเหล่านี้มักใช้อินเทอร์เฟซแบบภาพเพื่อเลือกข้อมูล แม้ว่าอาจมีปัญหากับเนื้อหาไดนามิกที่ซับซ้อนหรือมาตรการ anti-bot
ขั้นตอนการทำงานทั่วไปกับเครื่องมือ no-code
- ติดตั้งส่วนขยายเบราว์เซอร์หรือสมัครใช้งานแพลตฟอร์ม
- นำทางไปยังเว็บไซต์เป้าหมายและเปิดเครื่องมือ
- เลือกองค์ประกอบข้อมูลที่ต้องการดึงด้วยการชี้และคลิก
- กำหนดค่า CSS selectors สำหรับแต่ละฟิลด์ข้อมูล
- ตั้งค่ากฎการแบ่งหน้าเพื่อ scrape หลายหน้า
- จัดการ CAPTCHA (มักต้องแก้ไขด้วยตนเอง)
- กำหนดค่าการตั้งเวลาสำหรับการรันอัตโนมัติ
- ส่งออกข้อมูลเป็น CSV, JSON หรือเชื่อมต่อผ่าน API
ความท้าทายทั่วไป
- เส้นโค้งการเรียนรู้: การทำความเข้าใจ selectors และตรรกะการดึงข้อมูลต้องใช้เวลา
- Selectors เสีย: การเปลี่ยนแปลงเว็บไซต์อาจทำให้เวิร์กโฟลว์ทั้งหมดเสียหาย
- ปัญหาเนื้อหาไดนามิก: เว็บไซต์ที่ใช้ JavaScript มากต้องการวิธีแก้ไขที่ซับซ้อน
- ข้อจำกัด CAPTCHA: เครื่องมือส่วนใหญ่ต้องการการแทรกแซงด้วยตนเองสำหรับ CAPTCHA
- การบล็อก IP: การ scrape อย่างรุนแรงอาจส่งผลให้ IP ถูกบล็อก
ตัวอย่างโค้ด
import requests
from bs4 import BeautifulSoup
url = 'https://weworkremotely.com/'
headers = {'User-Agent': 'Mozilla/5.0'}
try:
# Send request with custom headers
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# Target job listings
jobs = soup.find_all('li', class_='feature')
for job in jobs:
title = job.find('span', class_='title').text.strip()
company = job.find('span', class_='company').text.strip()
print(f'Job: {title} | Company: {company}')
except Exception as e:
print(f'Error: {e}')เมื่อไหร่ควรใช้
เหมาะที่สุดสำหรับหน้า HTML แบบ static ที่มี JavaScript น้อย เหมาะสำหรับบล็อก ไซต์ข่าว และหน้าสินค้า e-commerce ธรรมดา
ข้อดี
- ●ประมวลผลเร็วที่สุด (ไม่มี overhead ของเบราว์เซอร์)
- ●ใช้ทรัพยากรน้อยที่สุด
- ●ง่ายต่อการทำงานแบบขนานด้วย asyncio
- ●เหมาะมากสำหรับ API และหน้า static
ข้อจำกัด
- ●ไม่สามารถรัน JavaScript ได้
- ●ล้มเหลวใน SPA และเนื้อหาไดนามิก
- ●อาจมีปัญหากับระบบ anti-bot ที่ซับซ้อน
วิธีสเครปข้อมูล We Work Remotely ด้วยโค้ด
Python + Requests
import requests
from bs4 import BeautifulSoup
url = 'https://weworkremotely.com/'
headers = {'User-Agent': 'Mozilla/5.0'}
try:
# Send request with custom headers
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# Target job listings
jobs = soup.find_all('li', class_='feature')
for job in jobs:
title = job.find('span', class_='title').text.strip()
company = job.find('span', class_='company').text.strip()
print(f'Job: {title} | Company: {company}')
except Exception as e:
print(f'Error: {e}')Python + Playwright
import asyncio
from playwright.async_api import async_playwright
async def run():
async with async_playwright() as p:
# Launch headless browser
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
await page.goto('https://weworkremotely.com/')
# Wait for the main container to load
await page.wait_for_selector('.jobs-container')
jobs = await page.query_selector_all('li.feature')
for job in jobs:
title = await job.query_selector('.title')
if title:
print(await title.inner_text())
await browser.close()
asyncio.run(run())Python + Scrapy
import scrapy
class WwrSpider(scrapy.Spider):
name = 'wwr_spider'
start_urls = ['https://weworkremotely.com/']
def parse(self, response):
# Iterate through listing items
for job in response.css('li.feature'):
yield {
'title': job.css('span.title::text').get(),
'company': job.css('span.company::text').get(),
'url': response.urljoin(job.css('a::attr(href)').get())
}Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://weworkremotely.com/');
// Extract data using evaluate
const jobs = await page.evaluate(() => {
return Array.from(document.querySelectorAll('li.feature')).map(li => ({
title: li.querySelector('.title')?.innerText.trim(),
company: li.querySelector('.company')?.innerText.trim()
}));
});
console.log(jobs);
await browser.close();
})();คุณสามารถทำอะไรกับข้อมูล We Work Remotely
สำรวจการใช้งานจริงและข้อมูลเชิงลึกจากข้อมูล We Work Remotely
ระบบรวบรวมงานทางไกล (Remote Job Aggregator)
สร้างแพลตฟอร์มค้นหางานเฉพาะทางสำหรับกลุ่มเทคโนโลยีเฉพาะ เช่น Rust หรือ AI
วิธีการนำไปใช้:
- 1Scrape WWR ทุกวันเพื่อหาประกาศงานใหม่
- 2กรองด้วยคีย์เวิร์ดและหมวดหมู่เฉพาะ
- 3จัดเก็บข้อมูลในฐานข้อมูลที่ค้นหาได้
- 4โพสต์งานใหม่บนโซเชียลมีเดียโดยอัตโนมัติ
ใช้ Automatio เพื่อดึงข้อมูลจาก We Work Remotely และสร้างแอปพลิเคชันเหล่านี้โดยไม่ต้องเขียนโค้ด
คุณสามารถทำอะไรกับข้อมูล We Work Remotely
- ระบบรวบรวมงานทางไกล (Remote Job Aggregator)
สร้างแพลตฟอร์มค้นหางานเฉพาะทางสำหรับกลุ่มเทคโนโลยีเฉพาะ เช่น Rust หรือ AI
- Scrape WWR ทุกวันเพื่อหาประกาศงานใหม่
- กรองด้วยคีย์เวิร์ดและหมวดหมู่เฉพาะ
- จัดเก็บข้อมูลในฐานข้อมูลที่ค้นหาได้
- โพสต์งานใหม่บนโซเชียลมีเดียโดยอัตโนมัติ
- การวิเคราะห์แนวโน้มเงินเดือน
วิเคราะห์ข้อมูลเงินเดือนงานทางไกลเพื่อกำหนดเกณฑ์มาตรฐานค่าตอบแทนทั่วโลกในแต่ละบทบาท
- ดึงข้อมูลฟิลด์เงินเดือนจากคำอธิบายงาน
- ปรับข้อมูลให้อยู่ในสกุลเงินเดียวกัน
- แบ่งส่วนตามบทบาทหน้าที่และระดับประสบการณ์
- สร้างรายงานแนวโน้มตลาดรายไตรมาส
- การสร้างลีดสำหรับ HR Tech
ระบุบริษัทที่กำลังจ้างงานทีมทางไกลอย่างจริงจังเพื่อเสนอขายซอฟต์แวร์ HR, ระบบจ่ายเงินเดือน และสวัสดิการ
- ตรวจสอบรายชื่อ 'Top 100 Remote Companies'
- ติดตามความถี่ของการโพสต์งานใหม่
- ระบุผู้มีอำนาจตัดสินใจในบริษัทที่กำลังจ้างงาน
- ติดต่อด้วยโซลูชัน B2B ที่ปรับแต่งให้เหมาะสม
- แนวโน้มการจ้างงานย้อนหลัง
วิเคราะห์ข้อมูลระยะยาวเพื่อทำความเข้าใจว่าความต้องการงานทางไกลเปลี่ยนแปลงตามฤดูกาลหรือภาวะเศรษฐกิจอย่างไร
- เก็บรวบรวมข้อมูลย้อนหลังมากกว่า 12 เดือน
- คำนวณอัตราการเติบโตต่อหมวดหมู่
- แสดงภาพแนวโน้มด้วยเครื่องมือ BI
- คาดการณ์ความต้องการทักษะในอนาค
เพิ่มพลังให้เวิร์กโฟลว์ของคุณด้วย ระบบอัตโนมัติ AI
Automatio รวมพลังของ AI agents การอัตโนมัติเว็บ และการผสานรวมอัจฉริยะเพื่อช่วยให้คุณทำงานได้มากขึ้นในเวลาน้อยลง
เคล็ดลับมืออาชีพสำหรับการ Scrape We Work Remotely
คำแนะนำจากผู้เชี่ยวชาญสำหรับการดึงข้อมูลจาก We Work Remotely อย่างประสบความสำเร็จ
ใช้ endpoint /remote-jobs.rss เพื่อรับ XML feed ที่สะอาดและอ่านได้ด้วยเครื่อง ซึ่งช่วยข้ามขั้นตอนการทำ HTML parsing ที่ซับซ้อน
สลับการใช้งาน residential proxies เพื่อหลีกเลี่ยงกำแพงความปลอดภัยของ Cloudflare และการถูกแบน IP อย่างถาวรระหว่างการ crawl ข้อมูลปริมาณมาก
กำหนดการหน่วงเวลาแบบสุ่ม (randomized delays) ระหว่างการส่ง request เพื่อเลียนแบบพฤติกรรมการใช้งานของมนุษย์และหลีกเลี่ยง rate limits
จัดระเบียบข้อมูลสถานที่ (Normalize) เช่น เปลี่ยนจาก 'Anywhere' เป็น 'Global' หรือ 'Remote' เพื่อให้การกรองข้อมูลในฐานข้อมูลมีความสม่ำเสมอมากขึ้น
ตั้งค่า User-Agent ให้เป็นสตริงของเบราว์เซอร์ทั่วไปเพื่อหลีกเลี่ยงการถูกตรวจจับว่าเป็น script scraper พื้นฐาน
คำรับรอง
ผู้ใช้ของเราพูดอย่างไร
เข้าร่วมกับผู้ใช้ที่พึงพอใจนับพันที่ได้เปลี่ยนแปลงเวิร์กโฟลว์ของพวกเขา
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
ที่เกี่ยวข้อง Web Scraping
How to Scrape Arc.dev: The Complete Guide to Remote Job Data
How to Scrape Fiverr | Fiverr Web Scraper Guide
How to Scrape Freelancer.com: A Complete Technical Guide
How to Scrape Upwork
How to Scrape Toptal | Toptal Web Scraper Guide
How to Scrape Guru.com: A Comprehensive Web Scraping Guide
How to Scrape Indeed: 2025 Guide for Job Market Data
How to Scrape Charter Global | IT Services & Job Board Scraper
คำถามที่พบบ่อยเกี่ยวกับ We Work Remotely
ค้นหาคำตอบสำหรับคำถามทั่วไปเกี่ยวกับ We Work Remotely