检测到反机器人保护
- Cloudflare
- 企业级WAF和机器人管理。使用JavaScript挑战、验证码和行为分析。需要带隐身设置的浏览器自动化。
- 速率限制
- 限制每个IP/会话在一段时间内的请求数。可通过轮换代理、请求延迟和分布式抓取绕过。
- 浏览器指纹
- 通过浏览器特征识别机器人:canvas、WebGL、字体、插件。需要伪装或真实浏览器配置文件。
- JavaScript挑战
- 需要执行JavaScript才能访问内容。简单请求会失败;需要Playwright或Puppeteer等无头浏览器。
关于The Piazza
了解The Piazza提供什么以及可以提取哪些有价值的数据。
The Piazza 由 Post Brothers 管理,是费城 Northern Liberties 社区著名的住宅和商业综合开发项目。它包含四个各具特色的豪华社区——Alta、Navona、Montesino 和 Liberties Walk,提供“城中城”式的居住体验,拥有高端设施和现代设计。
该网站是潜在租客的实时门户,展示当前的租赁价格、特定单元的入住日期以及详细的内部装修选项。对于数据科学家和房地产分析师而言,LivePiazza 是了解美国东北部增长最快的城市走廊之一——豪华多户住宅市场的关键数据源。
抓取这些数据可以对价格趋势、入驻率以及大型物业开发商提供的各种租赁激励措施的有效性进行高频监控。
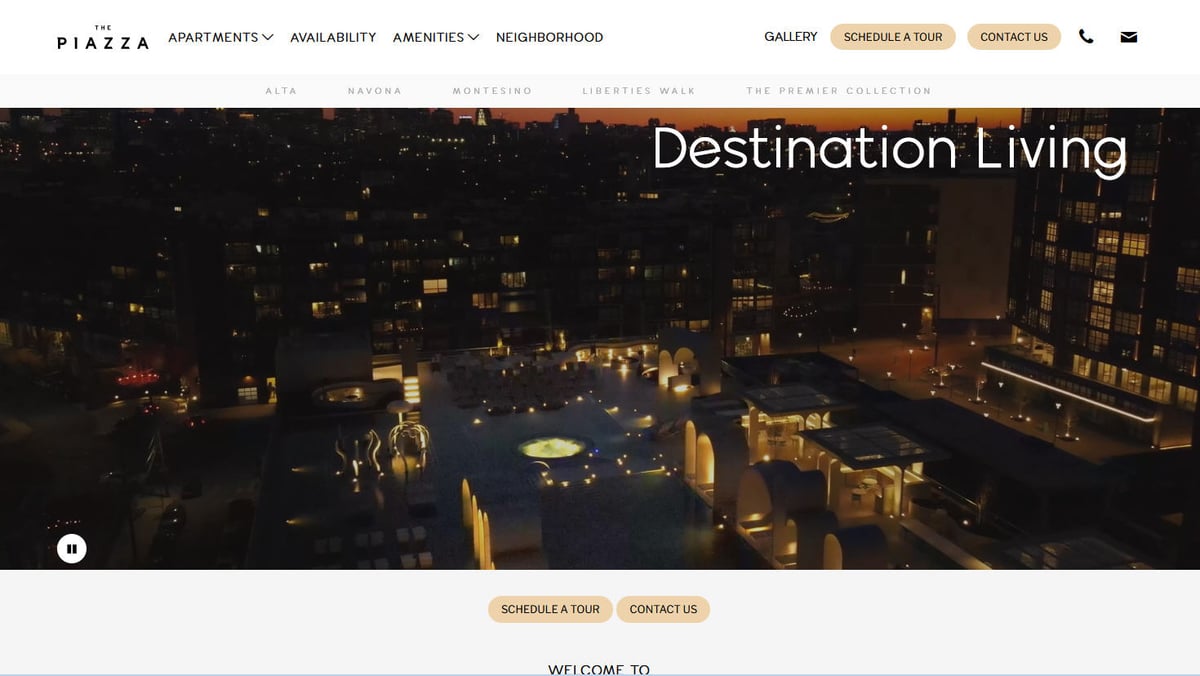
为什么要抓取The Piazza?
了解从The Piazza提取数据的商业价值和用例。
监控费城 luxury 市场租赁价格的实时波动。
追踪不同建筑社区的入驻率和单元周转率。
分析“免 2 个月租金”等租赁优惠对净有效租金的影响。
获取高分辨率户型图数据,用于建筑和室内设计研究。
为搬家公司和家具零售商等本地服务自动生成潜在客户。
与该地区其他 luxury 开发项目进行竞争性标杆分析。
抓取挑战
抓取The Piazza时可能遇到的技术挑战。
Cloudflare 的“等待室”和“稍等片刻”验证界面会拦截简单的 bot 请求。
单元空房表重度依赖客户端 JavaScript 渲染。
内部 API 接口使用的动态 tokens 过期速度非常快。
DOM 结构频繁更新,可能会导致静态 CSS 选择器失效。
使用AI抓取The Piazza
无需编码。通过AI驱动的自动化在几分钟内提取数据。
工作原理
描述您的需求
告诉AI您想从The Piazza提取什么数据。只需用自然语言输入 — 无需编码或选择器。
AI提取数据
我们的人工智能浏览The Piazza,处理动态内容,精确提取您要求的数据。
获取您的数据
接收干净、结构化的数据,可导出为CSV、JSON,或直接发送到您的应用和工作流程。
为什么使用AI进行抓取
AI让您无需编写代码即可轻松抓取The Piazza。我们的AI驱动平台利用人工智能理解您想要什么数据 — 只需用自然语言描述,AI就会自动提取。
How to scrape with AI:
- 描述您的需求: 告诉AI您想从The Piazza提取什么数据。只需用自然语言输入 — 无需编码或选择器。
- AI提取数据: 我们的人工智能浏览The Piazza,处理动态内容,精确提取您要求的数据。
- 获取您的数据: 接收干净、结构化的数据,可导出为CSV、JSON,或直接发送到您的应用和工作流程。
Why use AI for scraping:
- 自动解决 Cloudflare 挑战,无需手动配置代理。
- 像真人浏览器一样精确渲染动态 JavaScript 内容。
- 允许在复杂的户型图中视觉化选择数据点。
- 支持定时运行,以捕获每日价格变化和历史趋势。
- 将数据直接导出到 Google Sheets 或通过 Webhook 发送,以便立即分析。
The Piazza的无代码网页抓取工具
AI驱动抓取的点击式替代方案
Browse.ai、Octoparse、Axiom和ParseHub等多种无代码工具可以帮助您在不编写代码的情况下抓取The Piazza。这些工具通常使用可视化界面来选择数据,但可能在处理复杂的动态内容或反爬虫措施时遇到困难。
无代码工具的典型工作流程
常见挑战
学习曲线
理解选择器和提取逻辑需要时间
选择器失效
网站更改可能会破坏整个工作流程
动态内容问题
JavaScript密集型网站需要复杂的解决方案
验证码限制
大多数工具需要手动处理验证码
IP封锁
过于频繁的抓取可能导致IP被封
The Piazza的无代码网页抓取工具
Browse.ai、Octoparse、Axiom和ParseHub等多种无代码工具可以帮助您在不编写代码的情况下抓取The Piazza。这些工具通常使用可视化界面来选择数据,但可能在处理复杂的动态内容或反爬虫措施时遇到困难。
无代码工具的典型工作流程
- 安装浏览器扩展或在平台注册
- 导航到目标网站并打开工具
- 通过点击选择要提取的数据元素
- 为每个数据字段配置CSS选择器
- 设置分页规则以抓取多个页面
- 处理验证码(通常需要手动解决)
- 配置自动运行的计划
- 将数据导出为CSV、JSON或通过API连接
常见挑战
- 学习曲线: 理解选择器和提取逻辑需要时间
- 选择器失效: 网站更改可能会破坏整个工作流程
- 动态内容问题: JavaScript密集型网站需要复杂的解决方案
- 验证码限制: 大多数工具需要手动处理验证码
- IP封锁: 过于频繁的抓取可能导致IP被封
代码示例
import requests
from bs4 import BeautifulSoup
# Note: This direct request will likely fail due to Cloudflare
# A proxy or bypass solution like cloudscraper is recommended
url = 'https://www.livepiazza.com/residences'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9'
}
def fetch_piazza():
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# Example selector for residence cards
for card in soup.select('.residence-card'):
name = card.select_one('.residence-name').text.strip()
price = card.select_one('.price-value').text.strip()
print(f'Community: {name} | Price: {price}')
else:
print(f'Blocked by Anti-Bot: Status {response.status_code}')
except Exception as e:
print(f'Error: {e}')
fetch_piazza()使用场景
最适合JavaScript较少的静态HTML页面。非常适合博客、新闻网站和简单的电商产品页面。
优势
- ●执行速度最快(无浏览器开销)
- ●资源消耗最低
- ●易于使用asyncio并行化
- ●非常适合API和静态页面
局限性
- ●无法执行JavaScript
- ●在SPA和动态内容上会失败
- ●可能难以应对复杂的反爬虫系统
如何用代码抓取The Piazza
Python + Requests
import requests
from bs4 import BeautifulSoup
# Note: This direct request will likely fail due to Cloudflare
# A proxy or bypass solution like cloudscraper is recommended
url = 'https://www.livepiazza.com/residences'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9'
}
def fetch_piazza():
try:
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# Example selector for residence cards
for card in soup.select('.residence-card'):
name = card.select_one('.residence-name').text.strip()
price = card.select_one('.price-value').text.strip()
print(f'Community: {name} | Price: {price}')
else:
print(f'Blocked by Anti-Bot: Status {response.status_code}')
except Exception as e:
print(f'Error: {e}')
fetch_piazza()Python + Playwright
import asyncio
from playwright.async_api import async_playwright
async def scrape_live_piazza():
async with async_playwright() as p:
# Launching with a specific user agent to mimic a real browser
browser = await p.chromium.launch(headless=True)
context = await browser.new_context(user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36')
page = await context.new_page()
await page.goto('https://www.livepiazza.com/alta/')
# Wait for the dynamic unit table to load
await page.wait_for_selector('.unit-row', timeout=15000)
units = await page.query_selector_all('.unit-row')
for unit in units:
unit_id = await (await unit.query_selector('.unit-id')).inner_text()
rent = await (await unit.query_selector('.unit-rent')).inner_text()
print(f'Unit: {unit_id.strip()} | Rent: {rent.strip()}')
await browser.close()
asyncio.run(scrape_live_piazza())Python + Scrapy
import scrapy
class PiazzaSpider(scrapy.Spider):
name = 'piazza_spider'
start_urls = ['https://www.livepiazza.com/communities']
def parse(self, response):
# Scrapy requires a JS-rendering middleware (like Scrapy-Playwright) for this site
for building in response.css('.building-section'):
yield {
'building_name': building.css('h3.name::text').get(),
'link': building.css('a.explore-btn::attr(href)').get(),
'starting_price': building.css('.starting-from::text').get()
}
# Example of pagination following
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
puppeteer.use(StealthPlugin());
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto('https://www.livepiazza.com/montesino', { waitUntil: 'networkidle2' });
// Wait for the residences container to render
await page.waitForSelector('.residences-container');
const apartmentData = await page.evaluate(() => {
const rows = Array.from(document.querySelectorAll('.apartment-listing'));
return rows.map(row => ({
type: row.querySelector('.plan-type').innerText,
sqft: row.querySelector('.sqft').innerText,
available: row.querySelector('.availability').innerText
}));
});
console.log(apartmentData);
await browser.close();
})();您可以用The Piazza数据做什么
探索The Piazza数据的实际应用和洞察。
实时租金指数
创建一个实时仪表盘,追踪 Northern Liberties luxury 公寓的平均每平方英尺租金。
如何实现:
- 1提取所有开间(Studio)、一居室(1BR)和两居室(2BR)单元的每日价格。
- 2按平方英尺对价格进行归一化处理,创建 PPSF 指标。
- 3可视化 90 天内的趋势线。
使用Automatio从The Piazza提取数据,无需编写代码即可构建这些应用。
您可以用The Piazza数据做什么
- 实时租金指数
创建一个实时仪表盘,追踪 Northern Liberties luxury 公寓的平均每平方英尺租金。
- 提取所有开间(Studio)、一居室(1BR)和两居室(2BR)单元的每日价格。
- 按平方英尺对价格进行归一化处理,创建 PPSF 指标。
- 可视化 90 天内的趋势线。
- 优惠策略分析
分析物业管理者如何利用“免租期”激励措施来填补特定建筑的空置。
- 抓取每个列出单元的“Promotions(促销)”字段。
- 将促销信息与单元挂牌天数进行交叉比对。
- 确定开发商加大激励力度的“临界点”。
- 投资可行性研究
根据当前的供需情况,利用数据来论证或否决该区域新的 luxury 开发项目。
- 汇总 Alta、Navona 和 Montesino 的可用单元总量。
- 按“入住日期”对空房情况进行细分,以预测供应吸收率。
- 将 Piazza 的定价与全市 luxury 住宅平均水平进行对比。
- 搬家服务获客
识别高流量的搬入窗口期,为当地搬家和清洁服务进行精准营销。
- 筛选抓取到的房源中显示“立即入住”或特定未来日期的单元。
- 锁定未来空房量最高的建筑。
- 将广告支出与预测的最高租客更替期相对齐。
抓取The Piazza的专业技巧
成功从The Piazza提取数据的专家建议。
使用位于费城(Philadelphia)的住宅代理,以降低被 Cloudflare 安全过滤器识别的风险。
将抓取重点放在东部时间(ET)清晨,此时物业管理方通常会更新单元空房情况。
检查浏览器中的“网络(Network)”标签页,识别返回单元表格 JSON 数据的 XHR/Fetch 请求。
频繁更换 User-Agents 以避免基于指纹识别的 rate limiting。
通过解析促销优惠文本(例如“13个月租期免1个月房租”)来计算“净有效租金”。
在 scraper 中实现“等待(wait for)”逻辑,确保交互式户型图在提取前已完全渲染。
用户评价
用户怎么说
加入数千名已改变工作流程的满意用户
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
相关 Web Scraping
How to Scrape Century 21 Property Listings
How to Scrape Homes.com: Real Estate Data Extraction Guide
How to Scrape Century 21: A Technical Real Estate Guide
How to Scrape HotPads: A Complete Guide to Extracting Rental Data
How to Scrape Sacramento Delta Property Management
How to Scrape Locations Hawaii | Locations Hawaii Web Scraper
How to Scrape RE/MAX (remax.com) Real Estate Listings

How to Scrape Apartments Near Me | Real Estate Data Scraper
关于The Piazza的常见问题
查找关于The Piazza的常见问题答案