Pollen.com scrapen: Leitfaden zur Extraktion lokaler Allergiedaten
Erfahren Sie, wie Sie Pollen.com für lokalisierte Allergievorhersagen, Pollenwerte und die wichtigsten Allergene scrapen. Erhalten Sie tägliche...
Anti-Bot-Schutz erkannt
- Cloudflare
- Enterprise-WAF und Bot-Management. Nutzt JavaScript-Challenges, CAPTCHAs und Verhaltensanalyse. Erfordert Browser-Automatisierung mit Stealth-Einstellungen.
- Rate Limiting
- Begrenzt Anfragen pro IP/Sitzung über Zeit. Kann mit rotierenden Proxys, Anfrageverzögerungen und verteiltem Scraping umgangen werden.
- IP-Blockierung
- Blockiert bekannte Rechenzentrums-IPs und markierte Adressen. Erfordert Residential- oder Mobile-Proxys zur effektiven Umgehung.
- AngularJS Rendering
Über Pollen.com
Entdecken Sie, was Pollen.com bietet und welche wertvollen Daten extrahiert werden können.
Umfassende Allergiedaten für die USA
Pollen.com ist ein führendes Portal für Umweltgesundheit, das hochlokalisierte Allergieinformationen und Prognosen für die gesamten Vereinigten Staaten bereitstellt. Die Plattform wird von IQVIA, einem führenden Unternehmen für Gesundheitsdatenanalyse, betrieben und bietet spezifische Pollenwerte und Allergentypen basierend auf ZIP-Codes an. Sie dient als wichtige Ressource für Personen mit saisonalen Atemwegserkrankungen sowie für medizinisches Fachpersonal, das Trends in der Umweltgesundheit verfolgt.
Wertvolle Daten für die öffentliche Gesundheit
Die Website enthält strukturierte Daten, darunter einen Pollenindex von 0 bis 12, Kategorien der wichtigsten Allergene wie Bäume, Unkräuter und Gräser sowie detaillierte 5-Tage-Prognosen. Für Entwickler und Forscher bieten diese Daten Einblicke in regionale Umweltauslöser und historische Allergiemuster, die auf allgemeinen Wetterseiten nur schwer zu aggregieren sind.
Nutzen für Wirtschaft und Forschung
Das Scrapen von Pollen.com ist wertvoll für die Entwicklung von Anwendungen zur Gesundheitsüberwachung, die Optimierung von pharmazeutischen Lieferketten für Allergiemedikamente und die Durchführung akademischer Forschung zu den Auswirkungen des Klimawandels auf Bestäubungszyklen. Durch die Automatisierung der Extraktion dieser Datenpunkte können Organisationen Allergikern landesweit Echtzeit-Mehrwert bieten.
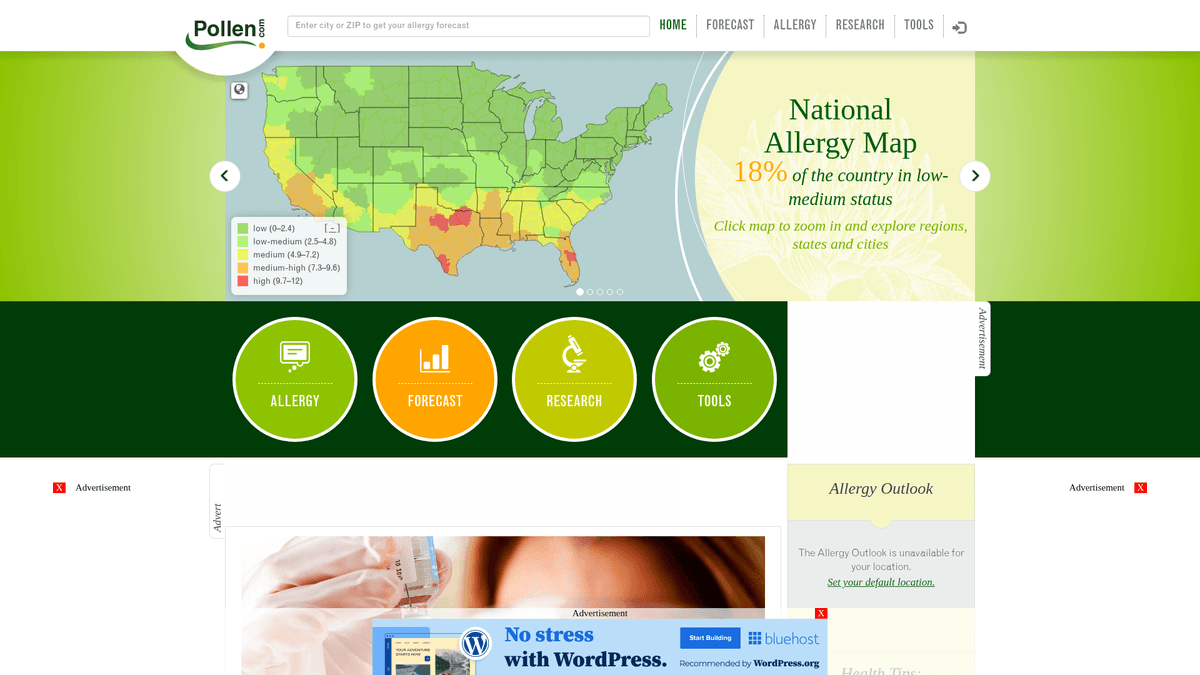
Warum Pollen.com Scrapen?
Entdecken Sie den Geschäftswert und die Anwendungsfälle für die Datenextraktion von Pollen.com.
Lokalisierte Gesundheitswarnungen erstellen
Scraping ermöglicht es Entwicklern, personalisierte Benachrichtigungssysteme zu erstellen, die Nutzer warnen, wenn die Allergenwerte in ihrem spezifischen ZIP-Code gefährliche Schwellenwerte erreichen.
Nachfrageprognosen für die Pharmaindustrie
Einzelhändler und Apotheken nutzen diese Daten, um Spitzenverkäufe bei Antihistaminika vorherzusagen, indem sie lokalisierte Pollenwerte mit dem Kaufverhalten der Konsumenten korrelieren.
Forschung zu Umweltauswirkungen
Das Sammeln von Langzeitdaten über vorherrschende Allergenarten hilft Wissenschaftlern zu verfolgen, wie der Klimamandel den Zeitpunkt und die Intensität der Pollenflugsaison verschiebt.
Inhalte für Nachrichten- und Wetterportale
Medienhäuser können ihre lokalen Wetterberichte durch die Integration von Echtzeit-Allergievorhersagen bereichern und ihren Lesern so hochwertige Gesundheitsinformationen bieten.
Smart Home IoT-Integration
Automatisierte Datenextraktion ermöglicht es Smart-Home-Systemen, Luftreinigungs- oder HVAC-Filterprotokolle auszulösen, wenn die Pollenbelastung im Freien hoch ist.
Umweltrelevante Einblicke für Immobilien
Immobilienportale können Stadtteilen einen Allergie-Score hinzufügen, um sensibilisierten Käufern zu helfen, die Luftqualität potenzieller Standorte zu bewerten.
Scraping-Herausforderungen
Technische Herausforderungen beim Scrapen von Pollen.com.
Dynamisches Rendering mit AngularJS
Die Seite stützt sich stark auf AngularJS, um Pollenindizes und Diagramme zu füllen, was bedeutet, dass standardmäßige HTTP-Clients ohne vollständige Browser-Ausführung nur leere Container sehen.
Cloudflare Anti-Bot-Maßnahmen
Pollen.com nutzt Cloudflare zur Erkennung und Blockierung von automatisiertem Traffic, was ein fortschrittliches Header-Management und Browser-Fingerprinting erfordert, um den Zugang aufrechtzuerhalten.
Massive ZIP-Code-Iteration
Das Sammeln nationaler Daten erfordert das Durchlaufen von Tausenden einzelner ZIP-Codes, was schnell Rate-Limits oder IP-Sperren auslösen kann, wenn es nicht korrekt verwaltet wird.
Volatilität interner API-Endpunkte
Obwohl Daten über interne JSON-Endpunkte abgerufen werden, sind diese nicht dokumentiert und können ihre Struktur bei Website-Updates ändern, was fragile Scraper potenziell unbrauchbar macht.
Scrape Pollen.com mit KI
Kein Code erforderlich. Extrahiere Daten in Minuten mit KI-gestützter Automatisierung.
So funktioniert's
Beschreibe, was du brauchst
Sag der KI, welche Daten du von Pollen.com extrahieren möchtest. Tippe es einfach in natürlicher Sprache ein — kein Code oder Selektoren nötig.
KI extrahiert die Daten
Unsere künstliche Intelligenz navigiert Pollen.com, verarbeitet dynamische Inhalte und extrahiert genau das, was du angefordert hast.
Erhalte deine Daten
Erhalte saubere, strukturierte Daten, bereit zum Export als CSV, JSON oder zum direkten Senden an deine Apps und Workflows.
Warum KI zum Scraping nutzen
KI macht es einfach, Pollen.com zu scrapen, ohne Code zu schreiben. Unsere KI-gestützte Plattform nutzt künstliche Intelligenz, um zu verstehen, welche Daten du möchtest — beschreibe es einfach in natürlicher Sprache und die KI extrahiert sie automatisch.
How to scrape with AI:
- Beschreibe, was du brauchst: Sag der KI, welche Daten du von Pollen.com extrahieren möchtest. Tippe es einfach in natürlicher Sprache ein — kein Code oder Selektoren nötig.
- KI extrahiert die Daten: Unsere künstliche Intelligenz navigiert Pollen.com, verarbeitet dynamische Inhalte und extrahiert genau das, was du angefordert hast.
- Erhalte deine Daten: Erhalte saubere, strukturierte Daten, bereit zum Export als CSV, JSON oder zum direkten Senden an deine Apps und Workflows.
Why use AI for scraping:
- Automatische JS-Ausführung: Automatio rendert die AngularJS-Anwendung nativ und stellt sicher, dass alle dynamischen Pollendiagramme und Indexwerte vollständig sichtbar und bereit für die Extraktion sind.
- Nahtloses ZIP-Code-Looping: Die visuelle Looping-Funktion ermöglicht es Ihnen, eine CSV-Datei mit Tausenden von ZIP-Codes einzugeben und automatisch zu jeder Seite zu navigieren, um Daten ohne manuellen Aufwand abzurufen.
- Intelligente Proxy-Rotation: Automatio übernimmt die IP-Rotation und das Management von Residential Proxies intern, sodass Sie Cloudflare und Rate-Limits mühelos und in großem Umfang umgehen können.
- Geplante Läufe am Morgen: Stellen Sie Ihren Scraper so ein, dass er jeden Morgen automatisch läuft, um das tägliche Update zu erfassen und sicherzustellen, dass Ihre Datenbank immer die aktuellsten Allergenvorhersagen widerspiegelt.
No-Code Web Scraper für Pollen.com
Point-and-Click-Alternativen zum KI-gestützten Scraping
Verschiedene No-Code-Tools wie Browse.ai, Octoparse, Axiom und ParseHub können Ihnen beim Scrapen von Pollen.com helfen. Diese Tools verwenden visuelle Oberflächen zur Elementauswahl, haben aber Kompromisse im Vergleich zu KI-gestützten Lösungen.
Typischer Workflow mit No-Code-Tools
Häufige Herausforderungen
Lernkurve
Das Verständnis von Selektoren und Extraktionslogik braucht Zeit
Selektoren brechen
Website-Änderungen können den gesamten Workflow zerstören
Probleme mit dynamischen Inhalten
JavaScript-lastige Seiten erfordern komplexe Workarounds
CAPTCHA-Einschränkungen
Die meisten Tools erfordern manuelle Eingriffe bei CAPTCHAs
IP-Sperrung
Aggressives Scraping kann zur Sperrung Ihrer IP führen
No-Code Web Scraper für Pollen.com
Verschiedene No-Code-Tools wie Browse.ai, Octoparse, Axiom und ParseHub können Ihnen beim Scrapen von Pollen.com helfen. Diese Tools verwenden visuelle Oberflächen zur Elementauswahl, haben aber Kompromisse im Vergleich zu KI-gestützten Lösungen.
Typischer Workflow mit No-Code-Tools
- Browser-Erweiterung installieren oder auf der Plattform registrieren
- Zur Zielwebseite navigieren und das Tool öffnen
- Per Point-and-Click die zu extrahierenden Datenelemente auswählen
- CSS-Selektoren für jedes Datenfeld konfigurieren
- Paginierungsregeln zum Scrapen mehrerer Seiten einrichten
- CAPTCHAs lösen (erfordert oft manuelle Eingabe)
- Zeitplanung für automatische Ausführungen konfigurieren
- Daten als CSV, JSON exportieren oder per API verbinden
Häufige Herausforderungen
- Lernkurve: Das Verständnis von Selektoren und Extraktionslogik braucht Zeit
- Selektoren brechen: Website-Änderungen können den gesamten Workflow zerstören
- Probleme mit dynamischen Inhalten: JavaScript-lastige Seiten erfordern komplexe Workarounds
- CAPTCHA-Einschränkungen: Die meisten Tools erfordern manuelle Eingriffe bei CAPTCHAs
- IP-Sperrung: Aggressives Scraping kann zur Sperrung Ihrer IP führen
Code-Beispiele
import requests
from bs4 import BeautifulSoup
# Hinweis: Dies erfasst statische News-Metadaten.
# Kern-Prognosedaten erfordern JavaScript-Rendering oder direkten Zugriff auf die interne API.
url = 'https://www.pollen.com/forecast/current/pollen/20001'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Basis-Nachrichtentitel aus der Seitenleiste extrahieren
news = [a.text.strip() for a in soup.select('article h2 a')]
print(f'Aktuelle Allergie-News: {news}')
except Exception as e:
print(f'Fehler aufgetreten: {e}')Wann verwenden
Am besten für statische HTML-Seiten, bei denen Inhalte serverseitig geladen werden. Der schnellste und einfachste Ansatz, wenn kein JavaScript-Rendering erforderlich ist.
Vorteile
- ●Schnellste Ausführung (kein Browser-Overhead)
- ●Geringster Ressourcenverbrauch
- ●Einfach zu parallelisieren mit asyncio
- ●Ideal für APIs und statische Seiten
Einschränkungen
- ●Kann kein JavaScript ausführen
- ●Scheitert bei SPAs und dynamischen Inhalten
- ●Kann bei komplexen Anti-Bot-Systemen Probleme haben
Wie man Pollen.com mit Code scrapt
Python + Requests
import requests
from bs4 import BeautifulSoup
# Hinweis: Dies erfasst statische News-Metadaten.
# Kern-Prognosedaten erfordern JavaScript-Rendering oder direkten Zugriff auf die interne API.
url = 'https://www.pollen.com/forecast/current/pollen/20001'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Basis-Nachrichtentitel aus der Seitenleiste extrahieren
news = [a.text.strip() for a in soup.select('article h2 a')]
print(f'Aktuelle Allergie-News: {news}')
except Exception as e:
print(f'Fehler aufgetreten: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
def run(playwright):
browser = playwright.chromium.launch(headless=True)
page = browser.new_page()
# Navigieren zu einer spezifischen ZIP-Code-Prognose
page.goto('https://www.pollen.com/forecast/current/pollen/20001')
# Warten, bis AngularJS den dynamischen Pollenindex rendert
page.wait_for_selector('.forecast-level')
data = {
'pollen_index': page.inner_text('.forecast-level'),
'status': page.inner_text('.forecast-level-desc'),
'allergens': [el.inner_text() for el in page.query_selector_all('.top-allergen-item span')]
}
print(f'Daten für 20001: {data}')
browser.close()
with sync_playwright() as playwright:
run(playwright)Python + Scrapy
import scrapy
class PollenSpider(scrapy.Spider):
name = 'pollen_spider'
start_urls = ['https://www.pollen.com/forecast/current/pollen/20001']
def parse(self, response):
# Für dynamische Inhalte Scrapy-Playwright oder ähnliche Middleware verwenden
# Diese Standard-Parse-Methode verarbeitet statische Elemente wie Schlagzeilen
yield {
'url': response.url,
'page_title': response.css('title::text').get(),
'news_headlines': response.css('article h2 a::text').getall()
}Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
// User-Agent setzen, um einen echten Browser zu simulieren
await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64)');
await page.goto('https://www.pollen.com/forecast/current/pollen/20001');
// Warten, bis das dynamische Prognose-Level erscheint
await page.waitForSelector('.forecast-level');
const data = await page.evaluate(() => ({
pollenIndex: document.querySelector('.forecast-level')?.innerText,
description: document.querySelector('.forecast-level-desc')?.innerText,
location: document.querySelector('h1')?.innerText
}));
console.log(data);
await browser.close();
})();Was Sie mit Pollen.com-Daten machen können
Entdecken Sie praktische Anwendungen und Erkenntnisse aus Pollen.com-Daten.
Personalisierte Allergiewarnungen
Mobile Gesundheits-Apps können Nutzer mit Echtzeit-Benachrichtigungen versorgen, wenn die Pollenbelastung in ihrem spezifischen Gebiet hohe Werte erreicht.
So implementieren Sie es:
- 1Tägliche Prognosen für vom Nutzer angegebene ZIP-Codes scrapen
- 2Identifizieren, wenn der Pollenindex einen Schwellenwert von 'Hoch' (7.3+) überschreitet
- 3Automatisierte Push-Benachrichtigungen oder SMS-Warnungen an den Nutzer senden
Verwenden Sie Automatio, um Daten von Pollen.com zu extrahieren und diese Anwendungen ohne Code zu erstellen.
Was Sie mit Pollen.com-Daten machen können
- Personalisierte Allergiewarnungen
Mobile Gesundheits-Apps können Nutzer mit Echtzeit-Benachrichtigungen versorgen, wenn die Pollenbelastung in ihrem spezifischen Gebiet hohe Werte erreicht.
- Tägliche Prognosen für vom Nutzer angegebene ZIP-Codes scrapen
- Identifizieren, wenn der Pollenindex einen Schwellenwert von 'Hoch' (7.3+) überschreitet
- Automatisierte Push-Benachrichtigungen oder SMS-Warnungen an den Nutzer senden
- Bedarfsprognose für Medikamente
Pharmazeutische Einzelhändler können ihre Lagerbestände optimieren, indem sie lokale Pollenspitzen mit der prognostizierten Nachfrage nach Antihistaminika korrelieren.
- 5-Tage-Prognosedaten für große Metropolregionen extrahieren
- Kommende Zeiträume mit hoher Allergenaktivität identifizieren
- Bestandsverteilung an lokale Apotheken koordinieren, bevor der Peak erreicht wird
- Umweltbewertung für Immobilien
Immobilienportale können ein 'Allergie-Rating' hinzufügen, um empfindlichen Käufern bei der Bewertung der Luftqualität in der Nachbarschaft zu helfen.
- Historische Pollendaten für spezifische Stadtviertel aggregieren
- Einen durchschnittlichen jährlichen Pollenintensitätswert berechnen
- Den Wert als benutzerdefiniertes Merkmal auf der Detailseite für Immobilien anzeigen
- Klimaforschung
Umweltwissenschaftler können die Dauer und Intensität von Pollensaisonen im Zeitverlauf verfolgen, um Klimaauswirkungen zu untersuchen.
- Tägliche Allergenarten und Indizes während der Frühlings- und Herbstsaison scrapen
- Start- und Enddaten der Bestäubung mit historischen Durchschnittswerten vergleichen
- Daten auf Trends analysieren, die auf längere oder intensivere Allergiesaisonen hindeuten
Optimieren Sie Ihren Workflow mit KI-Automatisierung
Automatio kombiniert die Kraft von KI-Agenten, Web-Automatisierung und intelligenten Integrationen, um Ihnen zu helfen, mehr in weniger Zeit zu erreichen.
Profi-Tipps für das Scrapen von Pollen.com
Expertentipps für die erfolgreiche Datenextraktion von Pollen.com.
Direkte URL-Logik verwenden
Überspringen Sie die Startseite und navigieren Sie direkt zum URL-Muster /forecast/current/pollen/[zipcode], um Navigationsschritte und die Serverlast zu reduzieren.
XHR-Anfragen identifizieren
Nutzen Sie Browser-Entwicklertools, um die spezifischen JSON-Endpunkte zu finden, die die Seite aufruft; diese direkt anzusteuern ist deutlich schneller als das Parsen des vollständigen HTML DOM.
Synchronisierung mit täglichen Updates
Pollen.com aktualisiert die Werte in der Regel einmal täglich am frühen Morgen; ein Scraping alle 24 Stunden ist optimal, um redundante Anfragen zu vermeiden.
Zufällige Verzögerungen implementieren
Um Fingerprinting zu vermeiden, fügen Sie eine zufällige Wartezeit von 3 bis 7 Sekunden zwischen jeder ZIP-Code-Abfrage hinzu, um das Browsing eines menschlichen Nutzers zu simulieren.
Residential Proxies priorisieren
Standardmäßige Datencenter-IPs werden von Gesundheitsdaten-Anbietern oft markiert; die Verwendung von Residential Proxies bietet die höchste Erfolgsquote beim Scraping großer Regionen.
Erfahrungsberichte
Was Unsere Nutzer Sagen
Schliessen Sie sich Tausenden zufriedener Nutzer an, die ihren Workflow transformiert haben
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Verwandte Web Scraping

How to Scrape GitHub | The Ultimate 2025 Technical Guide

How to Scrape RethinkEd: A Technical Data Extraction Guide

How to Scrape Britannica: Educational Data Web Scraper

How to Scrape Worldometers for Real-Time Global Statistics

How to Scrape Wikipedia: The Ultimate Web Scraping Guide

How to Scrape Weather.com: A Guide to Weather Data Extraction

How to Scrape American Museum of Natural History (AMNH)

How to Scrape Poll-Maker: A Comprehensive Web Scraping Guide
Häufig gestellte Fragen zu Pollen.com
Finden Sie Antworten auf häufige Fragen zu Pollen.com