Sådan scraper du Hacker News (news.ycombinator.com)
Lær hvordan du scraper Hacker News for at udtrække top tech-historier, jobopslag og diskussioner. Perfekt til markedsanalyse og trendanalyse.
Anti-bot beskyttelse opdaget
- Hastighedsbegrænsning
- Begrænser forespørgsler pr. IP/session over tid. Kan omgås med roterende proxyer, forespørgselsforsinkelser og distribueret scraping.
- IP-blokering
- Blokerer kendte datacenter-IP'er og markerede adresser. Kræver bolig- eller mobilproxyer for effektiv omgåelse.
- User-Agent Filtering
Om Hacker News
Opdag hvad Hacker News tilbyder og hvilke værdifulde data der kan udtrækkes.
Tech-hubben
Hacker News er et socialt nyhedswebsted med fokus på datalogi og iværksætteri, drevet af startup-inkubatoren Y Combinator. Det fungerer som en fællesskabsdrevet platform, hvor brugere indsender links til tekniske artikler, startup-nyheder og dybdegående diskussioner.
Datamæssig rigdom
Platformen indeholder en overflod af realtidsdata, herunder populære tech-historier, "Show HN" startup-lanceringer, "Ask HN" spørgsmål fra fællesskabet og specialiserede jobopslag. Den anses bredt for at være pulsen på Silicon Valley-økosystemet og det globale developer-community.
Strategisk værdi
Scraping af disse data giver virksomheder og forskere mulighed for at overvåge emerging technologies, spore omtale af konkurrenter og identificere indflydelsesrige tankeledere. Da sidens layout er bemærkelsesværdigt stabilt og enkelt, er det en af de mest pålidelige kilder til automatiseret teknisk nyhedsaggregering.
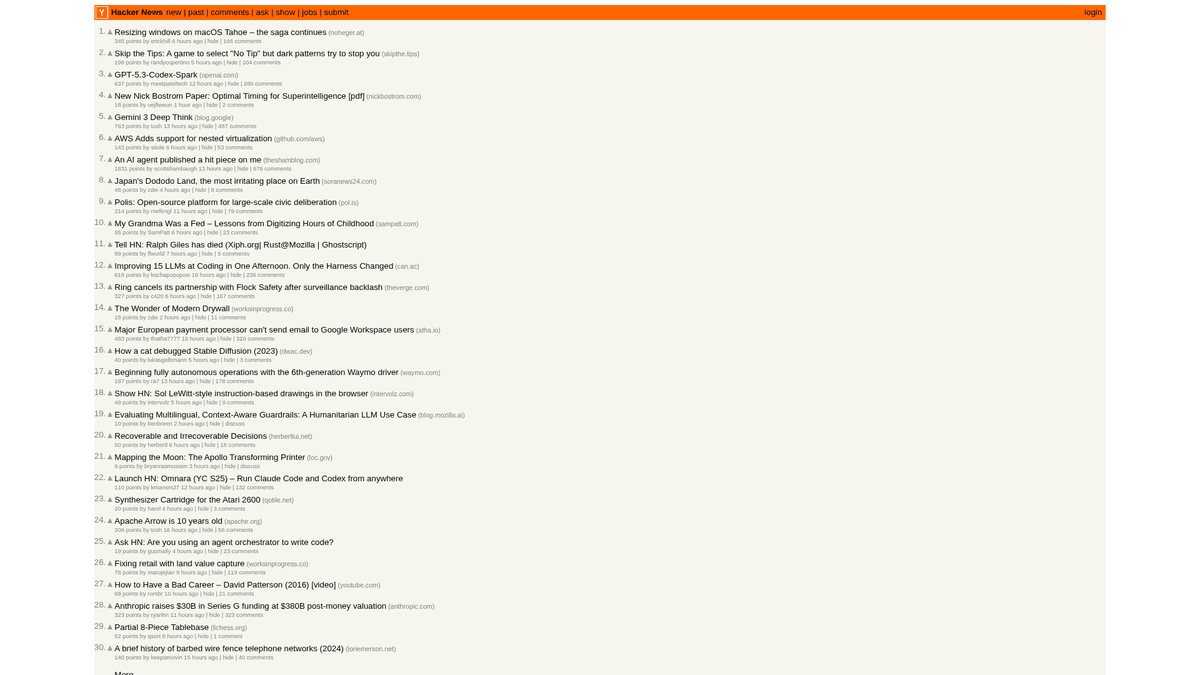
Hvorfor Skrabe Hacker News?
Opdag forretningsværdien og brugsscenarier for dataudtrækning fra Hacker News.
Identificer nye programmeringssprog og developer-værktøjer tidligt
Overvåg startup-økosystemet for nye lanceringer og finansieringsnyheder
Leadgenerering til teknisk rekruttering ved at overvåge 'Who is Hiring'-tråde
Sentiment-analyse af softwareudgivelser og virksomhedsmeddelelser
Byg tekniske nyhedsaggregatorer med højt signal til nichemålgrupper
Akademisk forskning i informationsspredning i tekniske fællesskaber
Skrabningsudfordringer
Tekniske udfordringer du kan støde på når du skraber Hacker News.
Parsing af indlejrede HTML-tabeller brugt til layouts
Håndtering af relative tidsstrenge som '2 timer siden' til databaseopbevaring
Håndtering af server-side rate-limits, der udløser midlertidige IP-forbud
Udtrækning af dybe kommentarhierarkier, der spænder over flere sider
Skrab Hacker News med AI
Ingen kode nødvendig. Udtræk data på minutter med AI-drevet automatisering.
Sådan fungerer det
Beskriv hvad du har brug for
Fortæl AI'en hvilke data du vil udtrække fra Hacker News. Skriv det bare på almindeligt sprog — ingen kode eller selektorer nødvendige.
AI udtrækker dataene
Vores kunstige intelligens navigerer Hacker News, håndterer dynamisk indhold og udtrækker præcis det du bad om.
Få dine data
Modtag rene, strukturerede data klar til eksport som CSV, JSON eller send direkte til dine apps og workflows.
Hvorfor bruge AI til skrabning
AI gør det nemt at skrabe Hacker News uden at skrive kode. Vores AI-drevne platform bruger kunstig intelligens til at forstå hvilke data du ønsker — beskriv det på almindeligt sprog, og AI udtrækker dem automatisk.
How to scrape with AI:
- Beskriv hvad du har brug for: Fortæl AI'en hvilke data du vil udtrække fra Hacker News. Skriv det bare på almindeligt sprog — ingen kode eller selektorer nødvendige.
- AI udtrækker dataene: Vores kunstige intelligens navigerer Hacker News, håndterer dynamisk indhold og udtrækker præcis det du bad om.
- Få dine data: Modtag rene, strukturerede data klar til eksport som CSV, JSON eller send direkte til dine apps og workflows.
Why use AI for scraping:
- Point-and-click valg af historier uden at skrive komplekse CSS-selectors
- Automatisk håndtering af 'More'-knappen for sømløs paginering
- Indbygget cloud-afvikling for at forhindre, at din lokale IP bliver rate-limited
- Planlagte scraping-kørsler for automatisk at fange forsiden hver time
- Direkte eksport til Google Sheets eller Webhooks for realtidsadvarsler
No-code webscrapere til Hacker News
Point-and-click alternativer til AI-drevet scraping
Flere no-code værktøjer som Browse.ai, Octoparse, Axiom og ParseHub kan hjælpe dig med at scrape Hacker News uden at skrive kode. Disse værktøjer bruger typisk visuelle interfaces til at vælge data, selvom de kan have problemer med komplekst dynamisk indhold eller anti-bot foranstaltninger.
Typisk workflow med no-code værktøjer
Almindelige udfordringer
Indlæringskurve
At forstå selektorer og ekstraktionslogik tager tid
Selektorer går i stykker
Webstedsændringer kan ødelægge hele din arbejdsgang
Problemer med dynamisk indhold
JavaScript-tunge sider kræver komplekse løsninger
CAPTCHA-begrænsninger
De fleste værktøjer kræver manuel indgriben for CAPTCHAs
IP-blokering
Aggressiv scraping kan føre til blokering af din IP
No-code webscrapere til Hacker News
Flere no-code værktøjer som Browse.ai, Octoparse, Axiom og ParseHub kan hjælpe dig med at scrape Hacker News uden at skrive kode. Disse værktøjer bruger typisk visuelle interfaces til at vælge data, selvom de kan have problemer med komplekst dynamisk indhold eller anti-bot foranstaltninger.
Typisk workflow med no-code værktøjer
- Installer browserudvidelse eller tilmeld dig platformen
- Naviger til målwebstedet og åbn værktøjet
- Vælg dataelementer med point-and-click
- Konfigurer CSS-selektorer for hvert datafelt
- Opsæt pagineringsregler til at scrape flere sider
- Håndter CAPTCHAs (kræver ofte manuel løsning)
- Konfigurer planlægning for automatiske kørsler
- Eksporter data til CSV, JSON eller forbind via API
Almindelige udfordringer
- Indlæringskurve: At forstå selektorer og ekstraktionslogik tager tid
- Selektorer går i stykker: Webstedsændringer kan ødelægge hele din arbejdsgang
- Problemer med dynamisk indhold: JavaScript-tunge sider kræver komplekse løsninger
- CAPTCHA-begrænsninger: De fleste værktøjer kræver manuel indgriben for CAPTCHAs
- IP-blokering: Aggressiv scraping kan føre til blokering af din IP
Kodeeksempler
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Stories are contained in rows with class 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Title: {title}
Link: {link}
---')
except Exception as e:
print(f'Scraping failed: {e}')Hvornår skal det bruges
Bedst til statiske HTML-sider med minimal JavaScript. Ideel til blogs, nyhedssider og simple e-handelsprodukt sider.
Fordele
- ●Hurtigste udførelse (ingen browser overhead)
- ●Laveste ressourceforbrug
- ●Let at parallelisere med asyncio
- ●Fremragende til API'er og statiske sider
Begrænsninger
- ●Kan ikke køre JavaScript
- ●Fejler på SPA'er og dynamisk indhold
- ●Kan have problemer med komplekse anti-bot systemer
Sådan scraper du Hacker News med kode
Python + Requests
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Stories are contained in rows with class 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Title: {title}
Link: {link}
---')
except Exception as e:
print(f'Scraping failed: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://news.ycombinator.com/')
# Wait for the table to load
page.wait_for_selector('.athing')
# Extract all story titles and links
items = page.query_selector_all('.athing')
for item in items:
title_link = item.query_selector('.titleline > a')
if title_link:
print(title_link.inner_text(), title_link.get_attribute('href'))
browser.close()Python + Scrapy
import scrapy
class HackerNewsSpider(scrapy.Spider):
name = 'hn_spider'
start_urls = ['https://news.ycombinator.com/']
def parse(self, response):
for post in response.css('.athing'):
yield {
'id': post.attrib.get('id'),
'title': post.css('.titleline > a::text').get(),
'link': post.css('.titleline > a::attr(href)').get(),
}
# Follow pagination 'More' link
next_page = response.css('a.morelink::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com/');
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.athing'));
return items.map(item => ({
title: item.querySelector('.titleline > a').innerText,
url: item.querySelector('.titleline > a').href
}));
});
console.log(results);
await browser.close();
})();Hvad Du Kan Gøre Med Hacker News-Data
Udforsk praktiske anvendelser og indsigter fra Hacker News-data.
Opdagelse af startup-tendenser
Identificer hvilke brancher eller produkttyper, der lanceres og diskuteres hyppigst.
Sådan implementeres:
- 1Scrap 'Show HN'-kategorien på ugentlig basis.
- 2Rens og kategoriser startup-beskrivelser ved hjælp af NLP.
- 3Ranger tendenser baseret på fællesskabets upvotes og kommentar-sentiment.
Brug Automatio til at udtrække data fra Hacker News og bygge disse applikationer uden at skrive kode.
Hvad Du Kan Gøre Med Hacker News-Data
- Opdagelse af startup-tendenser
Identificer hvilke brancher eller produkttyper, der lanceres og diskuteres hyppigst.
- Scrap 'Show HN'-kategorien på ugentlig basis.
- Rens og kategoriser startup-beskrivelser ved hjælp af NLP.
- Ranger tendenser baseret på fællesskabets upvotes og kommentar-sentiment.
- Tech Sourcing & Rekruttering
Udtræk jobopslag og virksomhedsoplysninger fra specialiserede månedlige ansættelsestråde.
- Overvåg ID'et for den månedlige 'Who is hiring'-tråd.
- Scrap alle kommentarer på øverste niveau, som indeholder jobbeskrivelser.
- Parse tekst for specifikke tech-stacks som Rust, AI eller React.
- Konkurrentovervågning
Spor omtale af konkurrenter i kommentarer for at forstå den offentlige opfattelse og klager.
- Opsæt en søgeordsbaseret scraper til specifikke brandnavne.
- Udtræk brugerkommentarer og tidsstempler til sentiment-analyse.
- Generer ugentlige rapporter om brand-helbred sammenlignet med konkurrenter.
- Automatiseret indholdskuration
Skab et teknisk nyhedsbrev med højt signal, der kun indeholder de mest relevante historier.
- Scrap forsiden hver 6. time.
- Filtrer for indlæg, der overstiger en tærskel på 200 point.
- Automatiser leveringen af disse links til en Telegram-bot eller e-mailliste.
- Venture Capital Leadgenerering
Opdag tidlige startups, der får betydelig opmærksomhed i fællesskabet.
- Spor 'Show HN'-indlæg, der når forsiden.
- Overvåg vækstraten for upvotes i løbet af de første 4 timer.
- Advar analytikere, når et indlæg viser virale vækstmønstre.
Supercharg din arbejdsgang med AI-automatisering
Automatio kombinerer kraften fra AI-agenter, webautomatisering og smarte integrationer for at hjælpe dig med at udrette mere på kortere tid.
Professionelle Tips til Skrabning af Hacker News
Ekspertråd til succesfuld dataudtrækning fra Hacker News.
Brug den officielle Firebase API til massiv indsamling af historiske data for at undgå kompleksitet med HTML-parsing.
Indstil altid en brugerdefineret User-Agent for at identificere din bot ansvarligt og undgå øjeblikkelig blokering.
Implementer et tilfældigt søvnintersval på 3-7 sekunder mellem anmodninger for at efterligne menneskelig adfærd.
Målret mod specifikke undermapper som /newest for de nyeste historier eller /ask for diskussioner i fællesskabet.
Gem 'Item ID' som din primære nøgle for at undgå dubletter, når du scraper forsiden hyppigt.
Scrap i ydertimerne (UTC nat) for at opleve hurtigere responstider og lavere risiko for rate-limiting.
Anmeldelser
Hvad vores brugere siger
Slut dig til tusindvis af tilfredse brugere, der har transformeret deres arbejdsgang
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relateret Web Scraping




Ofte stillede spørgsmål om Hacker News
Find svar på almindelige spørgsmål om Hacker News