Cum să extragi date (scrape) de pe Hacker News (news.ycombinator.com)
Învață cum să extragi date de pe Hacker News pentru a obține povești tech de top, liste de joburi și discuții ale comunității. Perfect pentru cercetare de...
Protecție anti-bot detectată
- Limitarea ratei
- Limitează cererile per IP/sesiune în timp. Poate fi ocolit cu proxy-uri rotative, întârzieri ale cererilor și scraping distribuit.
- Blocare IP
- Blochează IP-urile cunoscute ale centrelor de date și adresele semnalate. Necesită proxy-uri rezidențiale sau mobile pentru ocolire eficientă.
- User-Agent Filtering
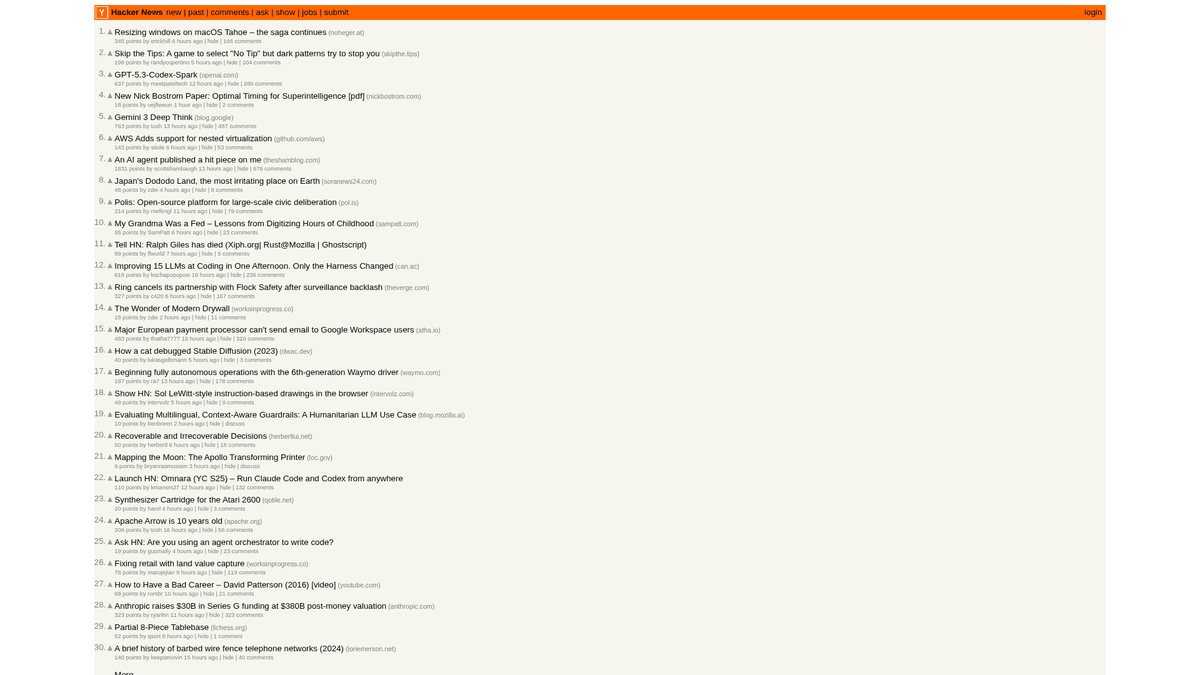
Despre Hacker News
Descoperiți ce oferă Hacker News și ce date valoroase pot fi extrase.
Hub-ul Tehnologic
Hacker News este un site web de știri sociale axat pe informatică și antreprenoriat, operat de incubatorul de startup-uri Y Combinator. Funcționează ca o platformă condusă de comunitate unde utilizatorii trimit link-uri către articole tehnice, știri despre startup-uri și discuții aprofundate.
Bogăția Datelor
Platforma conține o multitudine de date în timp real, inclusiv povești tech votate, lansări de startup-uri "Show HN", întrebări ale comunității "Ask HN" și panouri de joburi specializate. Este considerat pe scară largă pulsul ecosistemului Silicon Valley și al comunității globale de dezvoltatori.
Valoare Strategică
Extragerea acestor date permite companiilor și cercetătorilor să monitorizeze tehnologiile emergente, să urmărească mențiunile concurenților și să identifice liderii de opinie influenți. Deoarece structura site-ului este remarcabil de stabilă și simplă, acesta este una dintre cele mai fiabile surse pentru agregarea automată a știrilor tehnice.
De Ce Să Faceți Scraping La Hacker News?
Descoperiți valoarea comercială și cazurile de utilizare pentru extragerea datelor din Hacker News.
Identificarea timpurie a limbajelor de programare emergente și a instrumentelor pentru dezvoltatori
Monitorizarea ecosistemului de startup-uri pentru lansări noi și știri despre finanțare
Generarea de lead-uri pentru recrutarea tehnică prin monitorizarea firelor 'Who is Hiring'
Analiza sentimentului privind lansările de software și anunțurile corporative
Construirea de agregatoare de știri tehnice de înaltă fidelitate pentru audiențe de nișă
Cercetare academică privind propagarea informațiilor în comunitățile tehnice
Provocări De Scraping
Provocări tehnice pe care le puteți întâlni când faceți scraping la Hacker News.
Parsarea structurilor de tabele HTML imbricate folosite pentru layout
Gestionarea șirurilor de timp relative, cum ar fi '2 hours ago', pentru stocarea în baza de date
Gestionarea limitelor de rată la nivel de server care declanșează interdicții temporare de IP
Extragerea ierarhiilor profunde de comentarii care se întind pe mai multe pagini
Extrage date din Hacker News cu AI
Fără cod necesar. Extrage date în câteva minute cu automatizare bazată pe AI.
Cum funcționează
Descrie ce ai nevoie
Spune-i AI-ului ce date vrei să extragi din Hacker News. Scrie pur și simplu în limbaj natural — fără cod sau selectori.
AI-ul extrage datele
Inteligența noastră artificială navighează Hacker News, gestionează conținutul dinamic și extrage exact ceea ce ai cerut.
Primește-ți datele
Primește date curate și structurate gata de export în CSV, JSON sau de trimis direct către aplicațiile tale.
De ce să folosești AI pentru extragere
AI-ul face ușoară extragerea datelor din Hacker News fără a scrie cod. Platforma noastră bazată pe inteligență artificială înțelege ce date dorești — descrie-le în limbaj natural și AI-ul le extrage automat.
How to scrape with AI:
- Descrie ce ai nevoie: Spune-i AI-ului ce date vrei să extragi din Hacker News. Scrie pur și simplu în limbaj natural — fără cod sau selectori.
- AI-ul extrage datele: Inteligența noastră artificială navighează Hacker News, gestionează conținutul dinamic și extrage exact ceea ce ai cerut.
- Primește-ți datele: Primește date curate și structurate gata de export în CSV, JSON sau de trimis direct către aplicațiile tale.
Why use AI for scraping:
- Selecție point-and-click a poveștilor fără a scrie selectori CSS complecși
- Gestionarea automată a butonului 'More' pentru paginare fără probleme
- Execuție în cloud încorporată pentru a preveni limitarea IP-ului local
- Rulări programate de scraping pentru a captura prima pagină automat la fiecare oră
- Direct export către Google Sheets sau Webhooks pentru alerte în timp real
Scrapere Web No-Code pentru Hacker News
Alternative click-și-selectează la scraping-ul alimentat de AI
Mai multe instrumente no-code precum Browse.ai, Octoparse, Axiom și ParseHub vă pot ajuta să faceți scraping la Hacker News fără a scrie cod. Aceste instrumente folosesc de obicei interfețe vizuale pentru a selecta date, deși pot avea probleme cu conținut dinamic complex sau măsuri anti-bot.
Flux de Lucru Tipic cu Instrumente No-Code
Provocări Comune
Curba de învățare
Înțelegerea selectoarelor și a logicii de extracție necesită timp
Selectoarele se strică
Modificările site-ului web pot distruge întregul flux de lucru
Probleme cu conținut dinamic
Site-urile cu mult JavaScript necesită soluții complexe
Limitări CAPTCHA
Majoritatea instrumentelor necesită intervenție manuală pentru CAPTCHA
Blocarea IP-ului
Scraping-ul agresiv poate duce la blocarea IP-ului dvs.
Scrapere Web No-Code pentru Hacker News
Mai multe instrumente no-code precum Browse.ai, Octoparse, Axiom și ParseHub vă pot ajuta să faceți scraping la Hacker News fără a scrie cod. Aceste instrumente folosesc de obicei interfețe vizuale pentru a selecta date, deși pot avea probleme cu conținut dinamic complex sau măsuri anti-bot.
Flux de Lucru Tipic cu Instrumente No-Code
- Instalați extensia de browser sau înregistrați-vă pe platformă
- Navigați la site-ul web țintă și deschideți instrumentul
- Selectați elementele de date de extras prin point-and-click
- Configurați selectoarele CSS pentru fiecare câmp de date
- Configurați regulile de paginare pentru a scrape mai multe pagini
- Gestionați CAPTCHA (necesită adesea rezolvare manuală)
- Configurați programarea pentru rulări automate
- Exportați datele în CSV, JSON sau conectați prin API
Provocări Comune
- Curba de învățare: Înțelegerea selectoarelor și a logicii de extracție necesită timp
- Selectoarele se strică: Modificările site-ului web pot distruge întregul flux de lucru
- Probleme cu conținut dinamic: Site-urile cu mult JavaScript necesită soluții complexe
- Limitări CAPTCHA: Majoritatea instrumentelor necesită intervenție manuală pentru CAPTCHA
- Blocarea IP-ului: Scraping-ul agresiv poate duce la blocarea IP-ului dvs.
Exemple de cod
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Stories are contained in rows with class 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Title: {title}
Link: {link}
---')
except Exception as e:
print(f'Scraping failed: {e}')Când Se Folosește
Cel mai bun pentru pagini HTML statice unde conținutul este încărcat pe server. Cea mai rapidă și simplă abordare când randarea JavaScript nu este necesară.
Avantaje
- ●Execuție cea mai rapidă (fără overhead de browser)
- ●Consum minim de resurse
- ●Ușor de paralelizat cu asyncio
- ●Excelent pentru API-uri și pagini statice
Limitări
- ●Nu poate executa JavaScript
- ●Eșuează pe SPA-uri și conținut dinamic
- ●Poate avea probleme cu sisteme anti-bot complexe
How to Scrape Hacker News with Code
Python + Requests
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Stories are contained in rows with class 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Title: {title}
Link: {link}
---')
except Exception as e:
print(f'Scraping failed: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://news.ycombinator.com/')
# Wait for the table to load
page.wait_for_selector('.athing')
# Extract all story titles and links
items = page.query_selector_all('.athing')
for item in items:
title_link = item.query_selector('.titleline > a')
if title_link:
print(title_link.inner_text(), title_link.get_attribute('href'))
browser.close()Python + Scrapy
import scrapy
class HackerNewsSpider(scrapy.Spider):
name = 'hn_spider'
start_urls = ['https://news.ycombinator.com/']
def parse(self, response):
for post in response.css('.athing'):
yield {
'id': post.attrib.get('id'),
'title': post.css('.titleline > a::text').get(),
'link': post.css('.titleline > a::attr(href)').get(),
}
# Follow pagination 'More' link
next_page = response.css('a.morelink::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com/');
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.athing'));
return items.map(item => ({
title: item.querySelector('.titleline > a').innerText,
url: item.querySelector('.titleline > a').href
}));
});
console.log(results);
await browser.close();
})();Ce Puteți Face Cu Datele Hacker News
Explorați aplicațiile practice și informațiile din datele Hacker News.
Descoperirea Tendințelor Startup-urilor
Identifică ce industrii sau tipuri de produse sunt lansate și discutate cel mai frecvent.
Cum se implementează:
- 1Extrage categoria 'Show HN' săptămânal.
- 2Curăță și categorizează descrierile startup-urilor folosind NLP.
- 3Clasează tendințele pe baza voturilor comunității și a analizei de sentiment a comentariilor.
Folosiți Automatio pentru a extrage date din Hacker News și a construi aceste aplicații fără a scrie cod.
Ce Puteți Face Cu Datele Hacker News
- Descoperirea Tendințelor Startup-urilor
Identifică ce industrii sau tipuri de produse sunt lansate și discutate cel mai frecvent.
- Extrage categoria 'Show HN' săptămânal.
- Curăță și categorizează descrierile startup-urilor folosind NLP.
- Clasează tendințele pe baza voturilor comunității și a analizei de sentiment a comentariilor.
- Sourcing Tech și Recrutare
Extrage listele de locuri de muncă și detaliile companiilor din firele lunare specializate de angajare.
- Monitorizează ID-ul firului lunar 'Who is hiring'.
- Extrage toate comentariile de nivel superior care conțin descrieri de joburi.
- Parsează textul pentru stack-uri tehnice specifice, cum ar fi Rust, AI sau React.
- Analiza Concurenței
Urmărește mențiunile concurenților în comentarii pentru a înțelege percepția publică și plângerile.
- Configurează un scraper bazat pe cuvinte cheie pentru nume de brand specifice.
- Extrage comentariile utilizatorilor și timestamp-urile pentru analiza sentimentului.
- Generează rapoarte săptămânale despre sănătatea brandului față de concurenți.
- Curare Automată de Conținut
Creează un newsletter tech de înaltă calitate care include doar cele mai relevante povești.
- Extrage prima pagină la fiecare 6 ore.
- Filtrează postările care depășesc un prag de 200 de puncte.
- Automatizează livrarea acestor link-uri către un bot de Telegram sau o listă de e-mail.
- Lead Gen pentru Venture Capital
Descoperă startup-uri în stadiu incipient care câștigă o tracțiune semnificativă în comunitate.
- Urmărește postările 'Show HN' care ajung pe prima pagină.
- Monitorizează rata de creștere a voturilor în primele 4 ore.
- Alertează analiștii atunci când o postare prezintă modele de creștere virală.
Supraalimenteaza-ti fluxul de lucru cu automatizare AI
Automatio combina puterea agentilor AI, automatizarea web si integrarile inteligente pentru a te ajuta sa realizezi mai mult in mai putin timp.
Sfaturi Pro Pentru Scraping La Hacker News
Sfaturi de la experți pentru extragerea cu succes a datelor din Hacker News.
Folosește API-ul oficial Firebase pentru colectarea masivă de date istorice pentru a evita complexitatea parsării HTML.
Setează întotdeauna un User-Agent personalizat pentru a-ți identifica bot-ul în mod responsabil și pentru a evita blocarea imediată.
Implementează un interval de repaus aleatoriu de 3-7 secunde între cereri pentru a imita comportamentul uman de navigare.
Țintește subdirectoare specifice precum /newest pentru povești noi sau /ask pentru discuții ale comunității.
Stochează 'Item ID' ca cheie primară pentru a evita intrările duplicate atunci când rulați un scraper pe prima pagină frecvent.
Rulează scraper-ul în orele cu trafic redus (noaptea UTC) pentru a beneficia de timpi de răspuns mai rapizi și riscuri mai mici de rate-limiting.
Testimoniale
Ce spun utilizatorii nostri
Alatura-te miilor de utilizatori multumiti care si-au transformat fluxul de lucru
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Similar Web Scraping




Intrebari frecvente despre Hacker News
Gaseste raspunsuri la intrebarile comune despre Hacker News