Come effettuare lo scraping di Hacker News (news.ycombinator.com)
Scopri come fare lo scraping di Hacker News per estrarre le migliori storie tech, offerte di lavoro e discussioni della community. Ideale per ricerche di...
Protezione Anti-Bot Rilevata
- Rate Limiting
- Limita le richieste per IP/sessione nel tempo. Può essere aggirato con proxy rotanti, ritardi nelle richieste e scraping distribuito.
- Blocco IP
- Blocca IP di data center noti e indirizzi segnalati. Richiede proxy residenziali o mobili per aggirare efficacemente.
- User-Agent Filtering
Informazioni Su Hacker News
Scopri cosa offre Hacker News e quali dati preziosi possono essere estratti.
L'Hub Tecnologico
Hacker News è un sito di social news focalizzato su computer science e imprenditorialità, gestito dall'incubatore di startup Y Combinator. Funziona come una piattaforma guidata dalla community dove gli utenti inviano link ad articoli tecnici, news sulle startup e discussioni approfondite.
Ricchezza di Dati
La piattaforma contiene una vasta gamma di dati in tempo reale, tra cui storie tech votate, lanci di startup "Show HN", domande della community "Ask HN" e bacheche di lavoro specializzate. È ampiamente considerato il polso dell'ecosistema della Silicon Valley e della più ampia community globale di sviluppatori.
Valore Strategico
Lo scraping di questi dati consente ad aziende e ricercatori di monitorare le tecnologie emergenti, tracciare le menzioni dei competitor e identificare opinion leader influenti. Poiché il layout del sito è estremamente stabile e leggero, è una delle fonti più affidabili per l'aggregazione automatizzata di news tecniche.
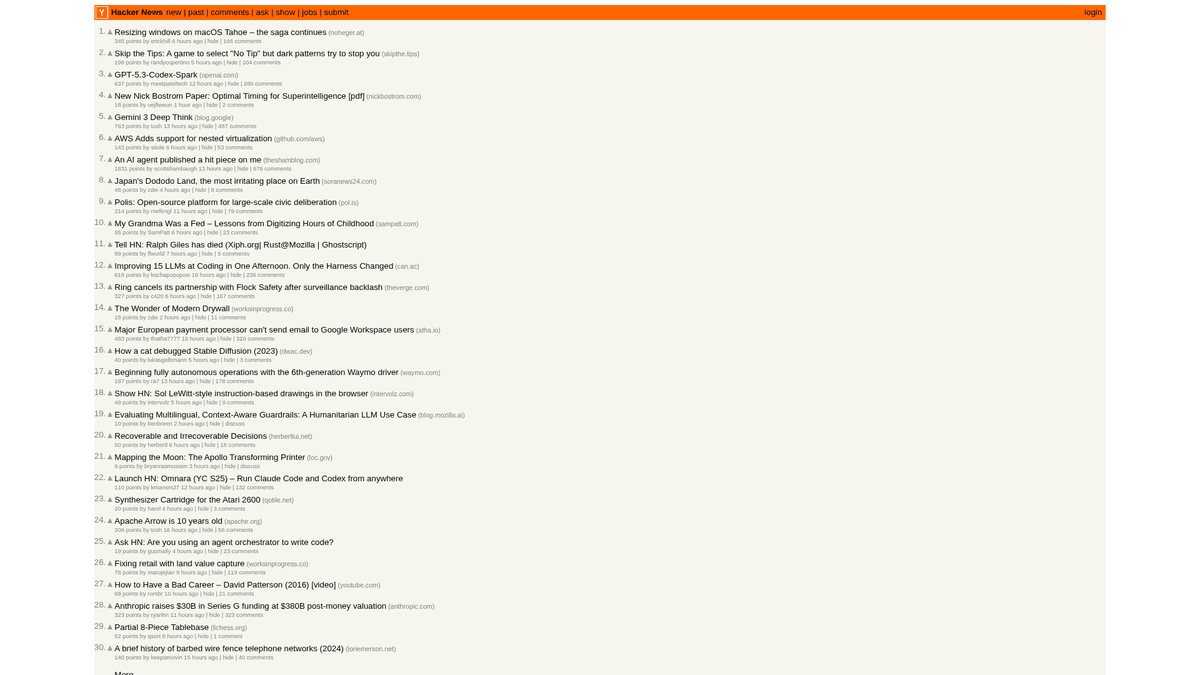
Perché Fare Scraping di Hacker News?
Scopri il valore commerciale e i casi d'uso per l'estrazione dati da Hacker News.
Identificazione dei trend di mercato
Monitora la prima pagina per vedere quali linguaggi di programmazione, framework o strumenti stanno guadagnando terreno nella community di sviluppatori in tempo reale.
Sentiment Analysis
Estrai i thread dei commenti per analizzare come un pubblico altamente tecnico reagisce al lancio di nuovi prodotti, cambiamenti di policy o spostamenti del mercato.
Startup Intelligence
Traccia i post 'Show HN' per scoprire startup in fase early-stage e progetti collaterali innovativi prima che raggiungano la copertura dei media mainstream.
Lead Generation per il Recruiting
Estrai i dati delle aziende che assumono dalla sezione Jobs per trovare società tech in crescita che cercano attivamente competenze specifiche.
Aggregazione di contenuti
Crea feed di notizie tecniche di alta qualità o newsletter filtrando i post con il maggior numero di upvote o parole chiave specifiche per sviluppatori.
Sfide dello Scraping
Sfide tecniche che potresti incontrare durante lo scraping di Hacker News.
Rate Limiting dell'IP
Hacker News è aggressivo nel limitare le richieste ad alta frequenza da un singolo indirizzo IP, rendendo necessaria una velocità di scansione ridotta o la rotazione dei proxy.
Parsing di tabelle annidate
Il sito utilizza strutture di tabelle HTML legacy per nidificare i commenti, richiedendo una logica di attraversamento attenta per ricostruire correttamente le relazioni padre-figlio.
Timestamp relativi
Gli orari sono visualizzati come 'X ore fa', il che richiede una logica di conversione se hai bisogno di timestamp assoluti per un database storico di serie temporali.
Ranking dinamici
La prima pagina cambia rapidamente mentre gli elementi salgono e scendono in classifica, il che può portare a duplicati di dati o elementi mancanti se lo scraping non viene gestito tramite ID univoci.
Scraping di Hacker News con l'IA
Nessun codice richiesto. Estrai dati in minuti con l'automazione basata sull'IA.
Come Funziona
Descrivi ciò di cui hai bisogno
Di' all'IA quali dati vuoi estrarre da Hacker News. Scrivi semplicemente in linguaggio naturale — nessun codice o selettore necessario.
L'IA estrae i dati
La nostra intelligenza artificiale naviga Hacker News, gestisce contenuti dinamici ed estrae esattamente ciò che hai richiesto.
Ottieni i tuoi dati
Ricevi dati puliti e strutturati pronti per l'esportazione in CSV, JSON o da inviare direttamente alle tue applicazioni.
Perché Usare l'IA per lo Scraping
L'IA rende facile lo scraping di Hacker News senza scrivere codice. La nostra piattaforma basata sull'intelligenza artificiale capisce quali dati vuoi — descrivili in linguaggio naturale e l'IA li estrae automaticamente.
How to scrape with AI:
- Descrivi ciò di cui hai bisogno: Di' all'IA quali dati vuoi estrarre da Hacker News. Scrivi semplicemente in linguaggio naturale — nessun codice o selettore necessario.
- L'IA estrae i dati: La nostra intelligenza artificiale naviga Hacker News, gestisce contenuti dinamici ed estrae esattamente ciò che hai richiesto.
- Ottieni i tuoi dati: Ricevi dati puliti e strutturati pronti per l'esportazione in CSV, JSON o da inviare direttamente alle tue applicazioni.
Why use AI for scraping:
- Estrazione storie No-Code: Estrai titoli, punti e URL in pochi minuti semplicemente cliccando sugli elementi invece di scrivere selettori CSS o XPath personalizzati per tabelle nidificate.
- Gestione intelligente della paginazione: Automatio gestisce senza sforzo il link 'More' per navigare automaticamente attraverso più pagine di cronologia o thread di commenti profondi.
- Rotazione dei proxy integrata: Supera automaticamente i limiti di frequenza con la rotazione dei proxy integrata, assicurando che i tuoi task di scraping non vengano mai interrotti da blocchi IP.
- Monitoraggio pianificato: Imposta una pianificazione per eseguire automaticamente lo scraping della prima pagina ogni ora per mantenere il tuo database aggiornato con gli ultimi trend tech.
- Integrazione diretta: Invia i dati estratti da Hacker News direttamente a Google Sheets o tramite webhook per attivare avvisi quando compaiono parole chiave specifiche nelle discussioni.
Scraper Web No-Code per Hacker News
Alternative point-and-click allo scraping alimentato da IA
Diversi strumenti no-code come Browse.ai, Octoparse, Axiom e ParseHub possono aiutarti a fare scraping di Hacker News senza scrivere codice. Questi strumenti usano interfacce visive per selezionare i dati, anche se possono avere difficoltà con contenuti dinamici complessi o misure anti-bot.
Workflow Tipico con Strumenti No-Code
Sfide Comuni
Curva di apprendimento
Comprendere selettori e logica di estrazione richiede tempo
I selettori si rompono
Le modifiche al sito web possono rompere l'intero flusso di lavoro
Problemi con contenuti dinamici
I siti con molto JavaScript richiedono soluzioni complesse
Limitazioni CAPTCHA
La maggior parte degli strumenti richiede intervento manuale per i CAPTCHA
Blocco IP
Lo scraping aggressivo può portare al blocco del tuo IP
Scraper Web No-Code per Hacker News
Diversi strumenti no-code come Browse.ai, Octoparse, Axiom e ParseHub possono aiutarti a fare scraping di Hacker News senza scrivere codice. Questi strumenti usano interfacce visive per selezionare i dati, anche se possono avere difficoltà con contenuti dinamici complessi o misure anti-bot.
Workflow Tipico con Strumenti No-Code
- Installare l'estensione del browser o registrarsi sulla piattaforma
- Navigare verso il sito web target e aprire lo strumento
- Selezionare con point-and-click gli elementi dati da estrarre
- Configurare i selettori CSS per ogni campo dati
- Impostare le regole di paginazione per lo scraping di più pagine
- Gestire i CAPTCHA (spesso richiede risoluzione manuale)
- Configurare la pianificazione per le esecuzioni automatiche
- Esportare i dati in CSV, JSON o collegare tramite API
Sfide Comuni
- Curva di apprendimento: Comprendere selettori e logica di estrazione richiede tempo
- I selettori si rompono: Le modifiche al sito web possono rompere l'intero flusso di lavoro
- Problemi con contenuti dinamici: I siti con molto JavaScript richiedono soluzioni complesse
- Limitazioni CAPTCHA: La maggior parte degli strumenti richiede intervento manuale per i CAPTCHA
- Blocco IP: Lo scraping aggressivo può portare al blocco del tuo IP
Esempi di Codice
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Stories are contained in rows with class 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Title: {title}
Link: {link}
---')
except Exception as e:
print(f'Scraping failed: {e}')Quando Usare
Ideale per pagine HTML statiche con JavaScript minimo. Perfetto per blog, siti di notizie e pagine prodotto e-commerce semplici.
Vantaggi
- ●Esecuzione più veloce (senza overhead del browser)
- ●Consumo risorse minimo
- ●Facile da parallelizzare con asyncio
- ●Ottimo per API e pagine statiche
Limitazioni
- ●Non può eseguire JavaScript
- ●Fallisce su SPA e contenuti dinamici
- ●Può avere difficoltà con sistemi anti-bot complessi
Come Fare Scraping di Hacker News con Codice
Python + Requests
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Stories are contained in rows with class 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Title: {title}
Link: {link}
---')
except Exception as e:
print(f'Scraping failed: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://news.ycombinator.com/')
# Wait for the table to load
page.wait_for_selector('.athing')
# Extract all story titles and links
items = page.query_selector_all('.athing')
for item in items:
title_link = item.query_selector('.titleline > a')
if title_link:
print(title_link.inner_text(), title_link.get_attribute('href'))
browser.close()Python + Scrapy
import scrapy
class HackerNewsSpider(scrapy.Spider):
name = 'hn_spider'
start_urls = ['https://news.ycombinator.com/']
def parse(self, response):
for post in response.css('.athing'):
yield {
'id': post.attrib.get('id'),
'title': post.css('.titleline > a::text').get(),
'link': post.css('.titleline > a::attr(href)').get(),
}
# Follow pagination 'More' link
next_page = response.css('a.morelink::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com/');
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.athing'));
return items.map(item => ({
title: item.querySelector('.titleline > a').innerText,
url: item.querySelector('.titleline > a').href
}));
});
console.log(results);
await browser.close();
})();Cosa Puoi Fare Con I Dati di Hacker News
Esplora applicazioni pratiche e insight dai dati di Hacker News.
Scoperta dei Trend delle Startup
Identifica quali settori o tipi di prodotti vengono lanciati e discussi più frequentemente.
Come implementare:
- 1Effettua lo scraping della categoria 'Show HN' su base settimanale.
- 2Pulisci e categorizza le descrizioni delle startup utilizzando NLP.
- 3Classifica i trend in base agli upvotes della community e al sentiment dei commenti.
Usa Automatio per estrarre dati da Hacker News e costruire queste applicazioni senza scrivere codice.
Cosa Puoi Fare Con I Dati di Hacker News
- Scoperta dei Trend delle Startup
Identifica quali settori o tipi di prodotti vengono lanciati e discussi più frequentemente.
- Effettua lo scraping della categoria 'Show HN' su base settimanale.
- Pulisci e categorizza le descrizioni delle startup utilizzando NLP.
- Classifica i trend in base agli upvotes della community e al sentiment dei commenti.
- Tech Sourcing e Recruiting
Estrai annunci di lavoro e dettagli aziendali dai thread mensili specializzati sulle assunzioni.
- Monitora l'ID del thread mensile 'Who is hiring'.
- Estrai tutti i commenti di primo livello che contengono descrizioni di lavoro.
- Analizza il testo per tech stack specifici come Rust, AI o React.
- Competitive Intelligence
Traccia le menzioni dei competitor nei commenti per comprendere la percezione pubblica e i reclami.
- Imposta uno scraper basato su parole chiave per nomi di brand specifici.
- Estrai i commenti degli utenti e i timestamp per l'analisi del sentiment.
- Genera report settimanali sulla salute del brand rispetto ai competitor.
- Curatela Automatizzata dei Contenuti
Crea una newsletter tech ad alto segnale che includa solo le storie più rilevanti.
- Effettua lo scraping della front page ogni 6 ore.
- Filtra i post che superano una soglia di 200 punti.
- Automatizza l'invio di questi link a un bot Telegram o a una lista email.
- Lead Gen per Venture Capital
Scopri startup early-stage che stanno ottenendo una trazione significativa dalla community.
- Traccia i post 'Show HN' che arrivano in front page.
- Monitora il tasso di crescita degli upvotes nelle prime 4 ore.
- Avvisa gli analisti quando un post mostra pattern di crescita virale.
Potenzia il tuo workflow con l'automazione AI
Automatio combina la potenza degli agenti AI, dell'automazione web e delle integrazioni intelligenti per aiutarti a fare di piu in meno tempo.
Consigli Pro per lo Scraping di Hacker News
Consigli esperti per estrarre con successo i dati da Hacker News.
Sfrutta l'API ufficiale
Per grandi volumi di dati, utilizza l'API ufficiale di Firebase, che è più efficiente e affidabile rispetto al parsing della struttura HTML legacy.
Rispetta il file Robots.txt
Controlla sempre il file robots.txt del sito e includi un ritardo di scansione di almeno 30 secondi per evitare di essere bloccato permanentemente dal server.
Punta agli ID univoci degli elementi
Ogni storia e commento ha un ID numerico univoco nell'HTML; usalo come chiave primaria nel tuo database per evitare voci duplicate.
Ruota gli User Agent
Cambia frequentemente gli header del browser per evitare che il server identifichi il tuo traffico come attività automatizzata di un bot.
Usa l'API di ricerca di Algolia
Per dati storici o ricerche complesse per parola chiave, l'API di Hacker News gestita dalla community di Algolia è significativamente più veloce e flessibile.
Parsing ricorsivo dei commenti
Quando effettui lo scraping dei commenti, cerca la larghezza di 'indent' nell'HTML per determinare programmaticamente il livello di nidificazione della discussione.
Testimonianze
Cosa dicono i nostri utenti
Unisciti a migliaia di utenti soddisfatti che hanno trasformato il loro workflow
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Correlati Web Scraping




Domande frequenti su Hacker News
Trova risposte alle domande comuni su Hacker News