Як скрейпити Hacker News (news.ycombinator.com)
Дізнайтеся, як скрейпити Hacker News для вилучення топових тех-історій, списків вакансій та обговорень. Ідеально для дослідження ринку та аналізу трендів.
Виявлено захист від ботів
- Обмеження частоти запитів
- Обмежує кількість запитів на IP/сесію за час. Можна обійти за допомогою ротації проксі, затримок запитів та розподіленого скрапінгу.
- Блокування IP
- Блокує відомі IP дата-центрів та позначені адреси. Потребує резидентних або мобільних проксі для ефективного обходу.
- User-Agent Filtering
Про Hacker News
Дізнайтеся, що пропонує Hacker News та які цінні дані можна витягнути.
Технологічний хаб
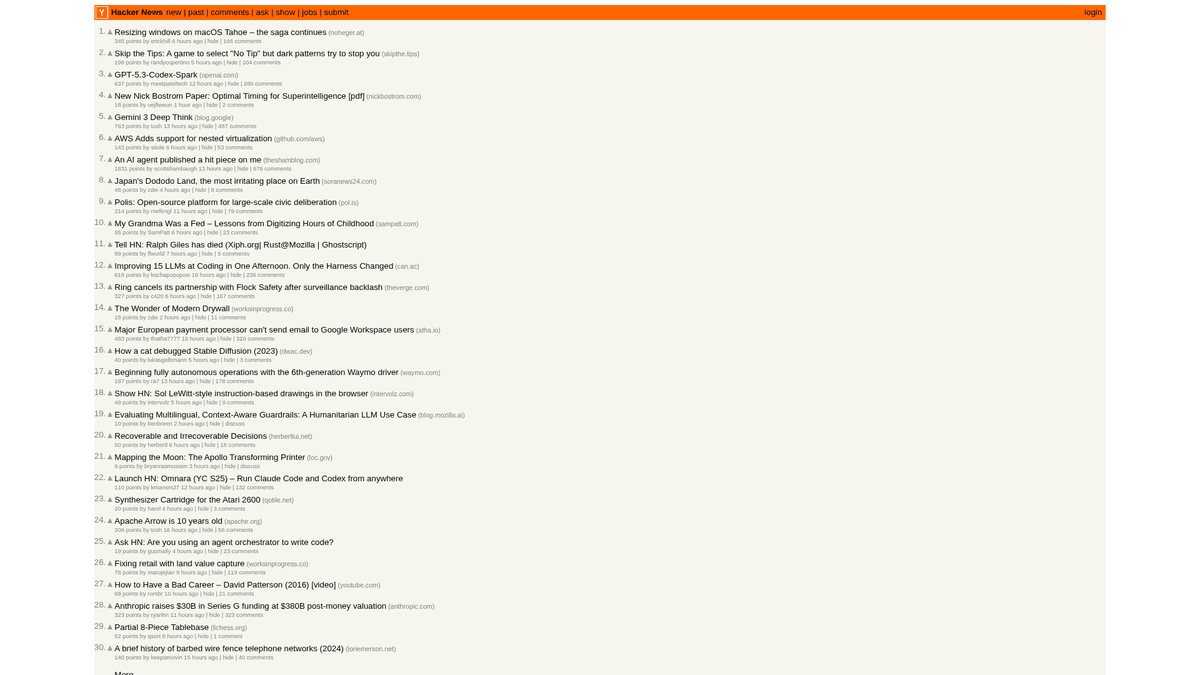
Hacker News — це соціальний новинний сайт, присвячений комп'ютерним наукам та підприємництву, яким керує стартап-інкубатор Y Combinator. Він функціонує як керована спільнотою платформа, де користувачі публікують посилання на технічні статті, новини стартапів та глибокі дискусії.
Багатство даних
Платформа містить величезну кількість даних у реальному часі, включаючи популярні тех-історії, запуски стартапів у розділі "Show HN", запитання спільноти "Ask HN" та спеціалізовані дошки вакансій. Сайт вважається пульсом екосистеми Кремнієвої долини та ширшої глобальної спільноти розробників.
Стратегічна цінність
Скрейпінг цих даних дозволяє бізнесу та дослідникам відстежувати новітні технології, згадки конкурентів та виявляти впливових лідерів думок. Оскільки макет сайту надзвичайно стабільний і легкий, він є одним із найнадійніших джерел для автоматизованої агрегації технічних новин.
Чому Варто Парсити Hacker News?
Дізнайтеся про бізнес-цінність та сценарії використання для витягування даних з Hacker News.
Раннє виявлення нових мов програмування та інструментів розробки
Моніторинг екосистеми стартапів на предмет запусків та новин про фінансування
Генерація лідів для технічного рекрутингу через моніторинг гілок 'Who is Hiring'
Аналіз тональності щодо релізів програмного забезпечення та корпоративних анонсів
Створення високоякісних технічних агрегаторів новин для нішевих аудиторій
Академічні дослідження поширення інформації в технічних спільнотах
Виклики Парсингу
Технічні виклики, з якими ви можете зіткнутися при парсингу Hacker News.
Парсинг вкладених структур HTML-таблиць, що використовуються для макетування
Обробка відносних часових рядків, як-от '2 години тому', для збереження в базі даних
Керування обмеженнями частоти запитів на стороні сервера, що викликають тимчасові бани по IP
Вилучення глибоких ієрархій коментарів, що охоплюють кілька сторінок
Скрапінг Hacker News за допомогою ШІ
Без коду. Витягуйте дані за лічені хвилини з автоматизацією на базі ШІ.
Як це працює
Опишіть, що вам потрібно
Скажіть ШІ, які дані ви хочете витягнути з Hacker News. Просто напишіть звичайною мовою — без коду чи селекторів.
ШІ витягує дані
Наш штучний інтелект навігує по Hacker News, обробляє динамічний контент і витягує саме те, що ви запросили.
Отримайте свої дані
Отримайте чисті, структуровані дані, готові до експорту в CSV, JSON або відправки безпосередньо у ваші додатки.
Чому варто використовувати ШІ для скрапінгу
ШІ спрощує скрапінг Hacker News без написання коду. Наша платформа на базі штучного інтелекту розуміє, які дані вам потрібні — просто опишіть їх звичайною мовою, і ШІ витягне їх автоматично.
How to scrape with AI:
- Опишіть, що вам потрібно: Скажіть ШІ, які дані ви хочете витягнути з Hacker News. Просто напишіть звичайною мовою — без коду чи селекторів.
- ШІ витягує дані: Наш штучний інтелект навігує по Hacker News, обробляє динамічний контент і витягує саме те, що ви запросили.
- Отримайте свої дані: Отримайте чисті, структуровані дані, готові до експорту в CSV, JSON або відправки безпосередньо у ваші додатки.
Why use AI for scraping:
- Вибір історій у режимі point-and-click без написання складних CSS-селекторів
- Автоматична обробка кнопки 'More' для безшовної пагінації
- Вбудоване хмарне виконання для запобігання блокуванню вашої локальної IP-адреси
- Заплановані запуски скрейпінгу для автоматичного оновлення даних щогодини
- Прямий експорт у Google Sheets або через Webhooks для сповіщень у реальному часі
No-code веб-парсери для Hacker News
Альтернативи point-and-click до AI-парсингу
Кілька no-code інструментів, таких як Browse.ai, Octoparse, Axiom та ParseHub, можуть допомогти вам парсити Hacker News без написання коду. Ці інструменти зазвичай використовують візуальні інтерфейси для вибору даних, хоча можуть мати проблеми зі складним динамічним контентом чи anti-bot заходами.
Типовий робочий процес з no-code інструментами
Типові виклики
Крива навчання
Розуміння селекторів та логіки вилучення потребує часу
Селектори ламаються
Зміни на вебсайті можуть зламати весь робочий процес
Проблеми з динамічним контентом
Сайти з великою кількістю JavaScript потребують складних рішень
Обмеження CAPTCHA
Більшість інструментів потребує ручного втручання для CAPTCHA
Блокування IP
Агресивний парсинг може призвести до блокування вашої IP
No-code веб-парсери для Hacker News
Кілька no-code інструментів, таких як Browse.ai, Octoparse, Axiom та ParseHub, можуть допомогти вам парсити Hacker News без написання коду. Ці інструменти зазвичай використовують візуальні інтерфейси для вибору даних, хоча можуть мати проблеми зі складним динамічним контентом чи anti-bot заходами.
Типовий робочий процес з no-code інструментами
- Встановіть розширення браузера або зареєструйтесь на платформі
- Перейдіть на цільовий вебсайт і відкрийте інструмент
- Виберіть елементи даних для вилучення методом point-and-click
- Налаштуйте CSS-селектори для кожного поля даних
- Налаштуйте правила пагінації для парсингу кількох сторінок
- Обробіть CAPTCHA (часто потрібне ручне розв'язання)
- Налаштуйте розклад для автоматичних запусків
- Експортуйте дані в CSV, JSON або підключіть через API
Типові виклики
- Крива навчання: Розуміння селекторів та логіки вилучення потребує часу
- Селектори ламаються: Зміни на вебсайті можуть зламати весь робочий процес
- Проблеми з динамічним контентом: Сайти з великою кількістю JavaScript потребують складних рішень
- Обмеження CAPTCHA: Більшість інструментів потребує ручного втручання для CAPTCHA
- Блокування IP: Агресивний парсинг може призвести до блокування вашої IP
Приклади коду
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Історії містяться в рядках із класом 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Заголовок: {title}
Посилання: {link}
---')
except Exception as e:
print(f'Помилка скрейпінгу: {e}')Коли використовувати
Найкраще для статичних HTML-сторінок з мінімумом JavaScript. Ідеально для блогів, новинних сайтів та простих сторінок товарів e-commerce.
Переваги
- ●Найшвидше виконання (без навантаження браузера)
- ●Найменше споживання ресурсів
- ●Легко розпаралелити з asyncio
- ●Чудово для API та статичних сторінок
Обмеження
- ●Не може виконувати JavaScript
- ●Не працює на SPA та динамічному контенті
- ●Може мати проблеми зі складними anti-bot системами
Як парсити Hacker News за допомогою коду
Python + Requests
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Історії містяться в рядках із класом 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Заголовок: {title}
Посилання: {link}
---')
except Exception as e:
print(f'Помилка скрейпінгу: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://news.ycombinator.com/')
# Очікування завантаження таблиці
page.wait_for_selector('.athing')
# Вилучення всіх заголовків та посилань
items = page.query_selector_all('.athing')
for item in items:
title_link = item.query_selector('.titleline > a')
if title_link:
print(title_link.inner_text(), title_link.get_attribute('href'))
browser.close()Python + Scrapy
import scrapy
class HackerNewsSpider(scrapy.Spider):
name = 'hn_spider'
start_urls = ['https://news.ycombinator.com/']
def parse(self, response):
for post in response.css('.athing'):
yield {
'id': post.attrib.get('id'),
'title': post.css('.titleline > a::text').get(),
'link': post.css('.titleline > a::attr(href)').get(),
}
# Перехід по пагінації (посилання 'More')
next_page = response.css('a.morelink::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com/');
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.athing'));
return items.map(item => ({
title: item.querySelector('.titleline > a').innerText,
url: item.querySelector('.titleline > a').href
}));
});
console.log(results);
await browser.close();
})();Що Можна Робити З Даними Hacker News
Досліджуйте практичні застосування та інсайти з даних Hacker News.
Виявлення трендів стартапів
Визначайте, які галузі або типи продуктів запускаються та обговорюються найчастіше.
Як реалізувати:
- 1Скрейпити категорію 'Show HN' щотижня.
- 2Очистити та класифікувати описи стартапів за допомогою NLP.
- 3Ранжувати тренди на основі вподобань спільноти та аналізу настроїв у коментарях.
Використовуйте Automatio для витягування даних з Hacker News та створення цих додатків без написання коду.
Що Можна Робити З Даними Hacker News
- Виявлення трендів стартапів
Визначайте, які галузі або типи продуктів запускаються та обговорюються найчастіше.
- Скрейпити категорію 'Show HN' щотижня.
- Очистити та класифікувати описи стартапів за допомогою NLP.
- Ранжувати тренди на основі вподобань спільноти та аналізу настроїв у коментарях.
- Пошук талантів та рекрутинг
Витягуйте списки вакансій та дані про компанії зі спеціалізованих щомісячних гілок найму.
- Моніторити ID щомісячної гілки 'Who is hiring' (Хто наймає).
- Скрейпити всі коментарі першого рівня, що містять описи вакансій.
- Парсити текст на наявність специфічних технологічних стеків, таких як Rust, AI або React.
- Конкурентна розвідка
Відстежуйте згадки конкурентів у коментарях, щоб зрозуміти сприйняття аудиторії та скарги.
- Налаштувати скрейпер за ключовими словами для конкретних брендів.
- Витягувати коментарі користувачів та часові мітки для аналізу тональності.
- Генерувати щотижневі звіти про стан бренду порівняно з конкурентами.
- Автоматизований відбір контенту
Створюйте високоякісну технічну розсилку, що включає лише найрелевантніші історії.
- Скрейпити головну сторінку кожні 6 годин.
- Фільтрувати пости, які перевищують поріг у 200 балів.
- Автоматизувати доставку цих посилань у Telegram-бота або на електронну пошту.
- Генерація лідів для венчурного капіталу
Виявляйте стартапи на ранніх стадіях, які отримують значну підтримку спільноти.
- Відстежувати пости 'Show HN', які потрапляють на головну сторінку.
- Моніторити темпи зростання лайків протягом перших 4 годин.
- Сповіщати аналітиків, коли пост демонструє ознаки вірального росту.
Прискорте вашу роботу з AI-автоматизацією
Automatio поєднує силу AI-агентів, веб-автоматизації та розумних інтеграцій, щоб допомогти вам досягти більшого за менший час.
Професійні Поради Щодо Парсингу Hacker News
Експертні поради для успішного витягування даних з Hacker News.
Використовуйте офіційний Firebase API для збору великих обсягів історичних даних, щоб уникнути складнощів із парсингом HTML.
Завжди встановлюйте кастомний User-Agent, щоб ідентифікувати свого бота відповідально та уникнути миттєвого блокування.
Налаштуйте випадковий інтервал очікування (sleep) від 3 до 7 секунд між запитами, щоб імітувати поведінку людини.
Орієнтуйтеся на конкретні підрозділи, як-от /newest для свіжих історій або /ask для обговорень спільноти.
Зберігайте 'Item ID' як первинний ключ, щоб уникнути дублювання записів при частому скрейпінгу головної сторінки.
Виконуйте скрейпінг у години низького навантаження (вночі за UTC), щоб отримати швидший час відповіді та знизити ризики обмеження частоти запитів (rate-limiting).
Відгуки
Що кажуть наші користувачі
Приєднуйтесь до тисяч задоволених користувачів, які трансформували свою роботу
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Пов'язані Web Scraping




Часті запитання про Hacker News
Знайдіть відповіді на поширені запитання про Hacker News