Cómo scrapear Hacker News (news.ycombinator.com)
Aprende a hacer scraping en Hacker News para extraer las mejores historias tecnológicas, ofertas de empleo y debates de la comunidad. Ideal para investigación...
Protección Anti-Bot Detectada
- Limitación de velocidad
- Limita solicitudes por IP/sesión en el tiempo. Se puede eludir con proxies rotativos, retrasos en solicitudes y scraping distribuido.
- Bloqueo de IP
- Bloquea IPs de centros de datos conocidos y direcciones marcadas. Requiere proxies residenciales o móviles para eludir efectivamente.
- User-Agent Filtering
Acerca de Hacker News
Descubre qué ofrece Hacker News y qué datos valiosos se pueden extraer.
El centro tecnológico
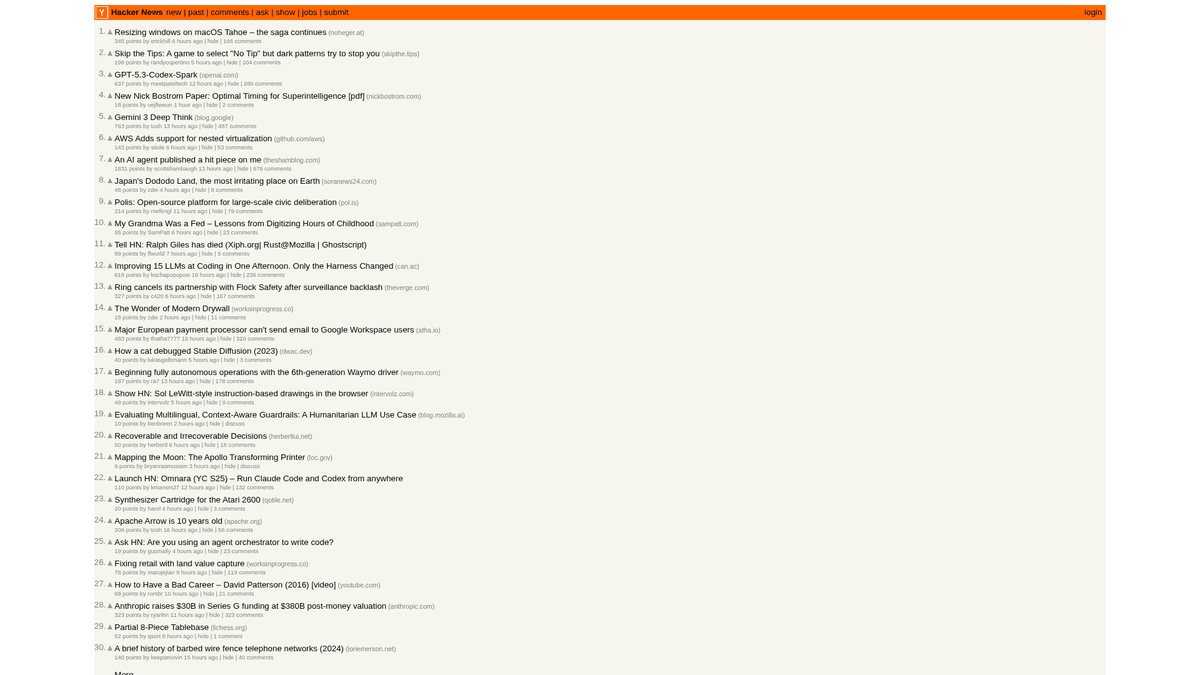
Hacker News es un sitio web de noticias sociales centrado en la informática y el emprendimiento, operado por la incubadora de startups Y Combinator. Funciona como una plataforma impulsada por la comunidad donde los usuarios envían enlaces a artículos técnicos, noticias de startups y discusiones profundas.
Riqueza de datos
La plataforma contiene una gran cantidad de datos en tiempo real, incluyendo historias tecnológicas votadas, lanzamientos de startups en "Show HN", preguntas de la comunidad en "Ask HN" y bolsas de trabajo especializadas. Es ampliamente considerada como el pulso del ecosistema de Silicon Valley y de la comunidad global de desarrolladores en general.
Valor estratégico
Scrapear estos datos permite a las empresas e investigadores monitorear tecnologías emergentes, rastrear menciones de competidores e identificar líderes de opinión influyentes. Dado que el diseño del sitio es notablemente estable y ligero, es una de las fuentes más fiables para la agregación automatizada de noticias técnicas.
¿Por Qué Scrapear Hacker News?
Descubre el valor comercial y los casos de uso para extraer datos de Hacker News.
Identificación de tendencias del mercado
Monitorea la página principal para ver qué lenguajes de programación, frameworks o herramientas están ganando tracción en la comunidad de desarrolladores en tiempo real.
Análisis de sentimiento
Extrae hilos de comentarios para analizar cómo reacciona una audiencia altamente técnica ante lanzamientos de nuevos productos, cambios en políticas o giros del mercado.
Inteligencia de startups
Rastrea las publicaciones 'Show HN' para descubrir startups en etapa temprana y proyectos secundarios innovadores antes de que lleguen a la cobertura de los medios convencionales.
Generación de leads para reclutamiento
Extrae datos de empresas que contratan desde la sección Jobs para encontrar compañías tecnológicas en crecimiento que buscan activamente experiencia específica.
Agregación de contenido
Crea feeds de noticias técnicas o newsletters de alta calidad filtrando las publicaciones con más votos positivos o palabras clave específicas de desarrolladores.
Desafíos de Scraping
Desafíos técnicos que puedes encontrar al scrapear Hacker News.
Limitación de tasa por IP
Hacker News es agresivo al limitar las peticiones de alta frecuencia desde una sola dirección IP, lo que requiere una velocidad de rastreo lenta o rotación de proxies.
Procesamiento de tablas anidadas
El sitio utiliza estructuras de tablas HTML antiguas para anidar comentarios, lo que requiere una lógica de recorrido cuidadosa para reconstruir correctamente las relaciones padre-hijo.
Marcas de tiempo relativas
Las horas se muestran como 'hace X horas', lo que requiere lógica de conversión si necesitas timestamps absolutos para una base de datos histórica de series temporales.
Rankings dinámicos
La página principal cambia rápidamente a medida que los elementos suben y bajan, lo que puede generar duplicados de datos o pérdida de elementos si la extracción no se gestiona mediante IDs únicos.
Scrapea Hacker News con IA
Sin código necesario. Extrae datos en minutos con automatización impulsada por IA.
Cómo Funciona
Describe lo que necesitas
Dile a la IA qué datos quieres extraer de Hacker News. Solo escríbelo en lenguaje natural — sin código ni selectores.
La IA extrae los datos
Nuestra inteligencia artificial navega Hacker News, maneja contenido dinámico y extrae exactamente lo que pediste.
Obtén tus datos
Recibe datos limpios y estructurados listos para exportar como CSV, JSON o enviar directamente a tus aplicaciones.
Por Qué Usar IA para el Scraping
La IA facilita el scraping de Hacker News sin escribir código. Nuestra plataforma impulsada por inteligencia artificial entiende qué datos quieres — solo descríbelo en lenguaje natural y la IA los extrae automáticamente.
How to scrape with AI:
- Describe lo que necesitas: Dile a la IA qué datos quieres extraer de Hacker News. Solo escríbelo en lenguaje natural — sin código ni selectores.
- La IA extrae los datos: Nuestra inteligencia artificial navega Hacker News, maneja contenido dinámico y extrae exactamente lo que pediste.
- Obtén tus datos: Recibe datos limpios y estructurados listos para exportar como CSV, JSON o enviar directamente a tus aplicaciones.
Why use AI for scraping:
- Extracción de historias sin código: Extrae títulos, puntos y URLs en minutos simplemente haciendo clic en los elementos, en lugar de escribir selectores CSS o XPath personalizados para tablas anidadas.
- Manejo inteligente de paginación: Automatio gestiona sin esfuerzo el enlace 'More' para rastrear automáticamente múltiples páginas de historial o hilos de comentarios profundos.
- Rotación de proxies integrada: Evita los límites de tasa automáticamente con la rotación de proxies integrada, asegurando que tus tareas de scraping nunca se vean interrumpidas por bloqueos de IP.
- Monitoreo programado: Configura un horario para extraer automáticamente la página principal cada hora y mantener tu base de datos actualizada con las últimas tendencias tecnológicas.
- Integración directa: Envía los datos extraídos de Hacker News directamente a Google Sheets o webhooks para activar alertas cuando aparezcan palabras clave específicas en las discusiones.
Scrapers Sin Código para Hacker News
Alternativas de apuntar y clic al scraping con IA
Varias herramientas sin código como Browse.ai, Octoparse, Axiom y ParseHub pueden ayudarte a scrapear Hacker News. Estas herramientas usan interfaces visuales para seleccionar elementos, pero tienen desventajas comparadas con soluciones con IA.
Flujo de Trabajo Típico con Herramientas Sin Código
Desafíos Comunes
Curva de aprendizaje
Comprender selectores y lógica de extracción lleva tiempo
Los selectores se rompen
Los cambios en el sitio web pueden romper todo el flujo de trabajo
Problemas con contenido dinámico
Los sitios con mucho JavaScript requieren soluciones complejas
Limitaciones de CAPTCHA
La mayoría de herramientas requieren intervención manual para CAPTCHAs
Bloqueo de IP
El scraping agresivo puede resultar en el bloqueo de tu IP
Scrapers Sin Código para Hacker News
Varias herramientas sin código como Browse.ai, Octoparse, Axiom y ParseHub pueden ayudarte a scrapear Hacker News. Estas herramientas usan interfaces visuales para seleccionar elementos, pero tienen desventajas comparadas con soluciones con IA.
Flujo de Trabajo Típico con Herramientas Sin Código
- Instalar extensión del navegador o registrarse en la plataforma
- Navegar al sitio web objetivo y abrir la herramienta
- Seleccionar con point-and-click los elementos de datos a extraer
- Configurar selectores CSS para cada campo de datos
- Configurar reglas de paginación para scrapear múltiples páginas
- Resolver CAPTCHAs (frecuentemente requiere intervención manual)
- Configurar programación para ejecuciones automáticas
- Exportar datos a CSV, JSON o conectar vía API
Desafíos Comunes
- Curva de aprendizaje: Comprender selectores y lógica de extracción lleva tiempo
- Los selectores se rompen: Los cambios en el sitio web pueden romper todo el flujo de trabajo
- Problemas con contenido dinámico: Los sitios con mucho JavaScript requieren soluciones complejas
- Limitaciones de CAPTCHA: La mayoría de herramientas requieren intervención manual para CAPTCHAs
- Bloqueo de IP: El scraping agresivo puede resultar en el bloqueo de tu IP
Ejemplos de Código
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Stories are contained in rows with class 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Title: {title}
Link: {link}
---')
except Exception as e:
print(f'Scraping failed: {e}')Cuándo Usar
Mejor para páginas HTML estáticas donde el contenido se carga del lado del servidor. El enfoque más rápido y simple cuando no se requiere renderizado de JavaScript.
Ventajas
- ●Ejecución más rápida (sin sobrecarga del navegador)
- ●Menor consumo de recursos
- ●Fácil de paralelizar con asyncio
- ●Excelente para APIs y páginas estáticas
Limitaciones
- ●No puede ejecutar JavaScript
- ●Falla en SPAs y contenido dinámico
- ●Puede tener dificultades con sistemas anti-bot complejos
Cómo Scrapear Hacker News con Código
Python + Requests
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Stories are contained in rows with class 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Title: {title}
Link: {link}
---')
except Exception as e:
print(f'Scraping failed: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://news.ycombinator.com/')
# Wait for the table to load
page.wait_for_selector('.athing')
# Extract all story titles and links
items = page.query_selector_all('.athing')
for item in items:
title_link = item.query_selector('.titleline > a')
if title_link:
print(title_link.inner_text(), title_link.get_attribute('href'))
browser.close()Python + Scrapy
import scrapy
class HackerNewsSpider(scrapy.Spider):
name = 'hn_spider'
start_urls = ['https://news.ycombinator.com/']
def parse(self, response):
for post in response.css('.athing'):
yield {
'id': post.attrib.get('id'),
'title': post.css('.titleline > a::text').get(),
'link': post.css('.titleline > a::attr(href)').get(),
}
# Follow pagination 'More' link
next_page = response.css('a.morelink::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com/');
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.athing'));
return items.map(item => ({
title: item.querySelector('.titleline > a').innerText,
url: item.querySelector('.titleline > a').href
}));
});
console.log(results);
await browser.close();
})();Qué Puedes Hacer Con Los Datos de Hacker News
Explora aplicaciones prácticas e insights de los datos de Hacker News.
Descubrimiento de tendencias de startups
Identifica qué industrias o tipos de productos se lanzan y se discuten con más frecuencia.
Cómo implementar:
- 1Scrapea la categoría 'Show HN' semanalmente.
- 2Limpia y categoriza las descripciones de las startups utilizando NLP.
- 3Clasifica las tendencias basándote en los upvotes de la comunidad y el sentimiento de los comentarios.
Usa Automatio para extraer datos de Hacker News y crear estas aplicaciones sin escribir código.
Qué Puedes Hacer Con Los Datos de Hacker News
- Descubrimiento de tendencias de startups
Identifica qué industrias o tipos de productos se lanzan y se discuten con más frecuencia.
- Scrapea la categoría 'Show HN' semanalmente.
- Limpia y categoriza las descripciones de las startups utilizando NLP.
- Clasifica las tendencias basándote en los upvotes de la comunidad y el sentimiento de los comentarios.
- Sourcing tecnológico y reclutamiento
Extrae ofertas de trabajo y detalles de empresas de hilos de contratación mensuales especializados.
- Monitorea el ID del hilo mensual 'Who is hiring'.
- Scrapea todos los comentarios de nivel superior que contienen descripciones de puestos.
- Analiza el texto en busca de stacks tecnológicos específicos como Rust, AI o React.
- Inteligencia competitiva
Rastrea menciones de competidores en los comentarios para entender la percepción pública y las quejas.
- Configura un scraper basado en palabras clave para nombres de marcas específicos.
- Extrae comentarios de usuarios y timestamps para análisis de sentimiento.
- Genera informes semanales sobre la salud de la marca frente a los competidores.
- Curación de contenido automatizada
Crea un boletín tecnológico de alta señal que solo incluya las historias más relevantes.
- Scrapea la página principal cada 6 horas.
- Filtra las publicaciones que superen un umbral de 200 puntos.
- Automatiza el envío de estos enlaces a un bot de Telegram o lista de correo electrónico.
- Generación de leads para Venture Capital
Descubre startups en etapas tempranas que están ganando una tracción significativa en la comunidad.
- Rastrea las publicaciones de 'Show HN' que llegan a la página principal.
- Monitorea la tasa de crecimiento de los upvotes durante las primeras 4 horas.
- Alerta a los analistas cuando una publicación muestre patrones de crecimiento viral.
Potencia tu flujo de trabajo con Automatizacion IA
Automatio combina el poder de agentes de IA, automatizacion web e integraciones inteligentes para ayudarte a lograr mas en menos tiempo.
Consejos Pro para Scrapear Hacker News
Consejos expertos para extraer datos exitosamente de Hacker News.
Aprovecha la API oficial
Para grandes volúmenes de datos, utiliza la API oficial de Firebase, que es más eficiente y confiable que procesar la estructura HTML heredada.
Respeta el archivo robots.txt
Revisa siempre el archivo robots.txt del sitio e incluye un crawl delay de al menos 30 segundos para evitar que el servidor te bloquee de forma permanente.
Utiliza IDs de ítems únicos
Cada historia y comentario tiene un ID numérico único en el HTML; úsalo como clave primaria en tu base de datos para evitar entradas duplicadas.
Rota los User Agents
Cambia los encabezados de tu navegador con frecuencia para evitar que el servidor identifique tu tráfico como actividad automatizada de bots.
Usa la API de búsqueda de Algolia
Para datos históricos o búsquedas complejas por palabras clave, la API de Algolia para HN, mantenida por la comunidad, es significativamente más rápida y flexible.
Procesamiento recursivo de comentarios
Al extraer comentarios, busca el ancho de sangría ('indent') en el HTML para determinar programáticamente el nivel de anidamiento de la discusión.
Testimonios
Lo Que Dicen Nuestros Usuarios
Unete a miles de usuarios satisfechos que han transformado su flujo de trabajo
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Relacionados Web Scraping




Preguntas Frecuentes Sobre Hacker News
Encuentra respuestas a preguntas comunes sobre Hacker News