Hacker News Verileri Nasıl Scrape Edilir (news.ycombinator.com)
Hacker News'i scrape ederek en iyi teknoloji haberlerini, iş ilanlarını ve topluluk tartışmalarını nasıl çekeceğinizi öğrenin. Pazar araştırması ve trend...
Anti-Bot Koruması Tespit Edildi
- Hız sınırlama
- IP/oturum başına zamana bağlı istek sayısını sınırlar. Dönen proxy'ler, istek gecikmeleri ve dağıtılmış kazıma ile atlatılabilir.
- IP engelleme
- Bilinen veri merkezi IP'lerini ve işaretlenmiş adresleri engeller. Etkili atlatma için konut veya mobil proxy'ler gerektirir.
- User-Agent Filtering
Hacker News Hakkında
Hacker News'in sunduklarını ve çıkarılabilecek değerli verileri keşfedin.
Teknoloji Merkezi
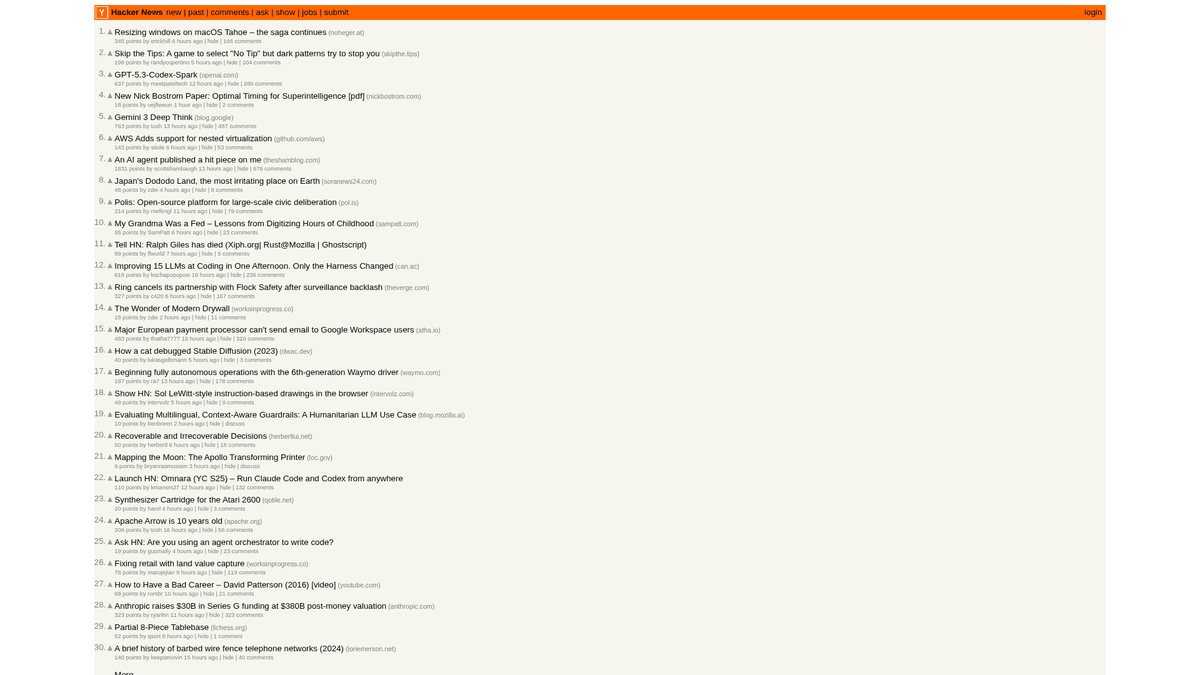
Hacker News, bilgisayar bilimi ve girişimcilik üzerine odaklanan, startup hızlandırıcısı Y Combinator tarafından işletilen bir sosyal haber sitesidir. Kullanıcıların teknik makalelere, girişim haberlerine ve derinlemesine tartışmalara bağlantılar gönderdiği topluluk odaklı bir platform olarak işlev görür.
Veri Zenginliği
Platform; oylanan teknoloji hikayeleri, "Show HN" startup lansmanları, "Ask HN" topluluk soruları ve özel iş ilanları panoları dahil olmak üzere zengin bir gerçek zamanlı veri kaynağıdır. Silicon Valley ekosisteminin ve küresel yazılımcı topluluğunun nabzını tutan bir mecra olarak kabul edilir.
Stratejik Değer
Bu verileri scrape etmek, işletmelerin ve araştırmacıların yeni gelişen teknolojileri izlemesine, rakip mention'larını takip etmesine ve etkili fikir liderlerini belirlemesine olanak tanır. Site düzeni oldukça kararlı ve yalın olduğu için, otomatik teknik haber toplama süreçleri için en güvenilir kaynaklardan biridir.
Neden Hacker News Kazımalı?
Hacker News'den veri çıkarmanın iş değerini ve kullanım durumlarını keşfedin.
Yeni gelişen programlama dillerini ve geliştirici araçlarını erkenden tespit edin
Yeni lansmanlar ve yatırım haberleri için startup ekosistemini izleyin
'Who is Hiring' başlıklarını takip ederek teknik işe alım için potansiyel adaylar bulun
Yazılım sürümleri ve kurumsal duyurular üzerinde duygu analizi yapın
Niş kitleler için yüksek sinyalli teknik haber toplayıcılar oluşturun
Teknik topluluklardaki bilgi yayılımı üzerine akademik araştırmalar yapın
Kazıma Zorlukları
Hacker News kazırken karşılaşabileceğiniz teknik zorluklar.
Düzenler için kullanılan iç içe geçmiş HTML tablo yapılarını parse etmek
Veritabanı depolaması için '2 saat önce' gibi göreceli zaman dizilerini yönetmek
Geçici IP yasaklarını tetikleyen sunucu tarafı rate limit'lerini yönetmek
Birden fazla sayfaya yayılan derin yorum hiyerarşilerini çıkarmak
AI ile Hacker News Kazıyın
Kod gerekmez. AI destekli otomasyonla dakikalar içinde veri çıkarın.
Nasıl Çalışır
İhtiyacınızı tanımlayın
AI'ya Hacker News üzerinden hangi verileri çıkarmak istediğinizi söyleyin. Doğal dilde yazmanız yeterli — kod veya seçiciler gerekmez.
AI verileri çıkarır
Yapay zekamız Hacker News'i dolaşır, dinamik içerikleri işler ve tam olarak istediğiniz verileri çıkarır.
Verilerinizi alın
CSV, JSON olarak dışa aktarmaya veya doğrudan uygulamalarınıza göndermeye hazır temiz, yapılandırılmış veriler alın.
Kazıma için neden AI kullanmalısınız
AI, kod yazmadan Hacker News'i kazımayı kolaylaştırır. Yapay zeka destekli platformumuz hangi verileri istediğinizi anlar — doğal dilde tanımlayın, AI otomatik olarak çıkarsın.
How to scrape with AI:
- İhtiyacınızı tanımlayın: AI'ya Hacker News üzerinden hangi verileri çıkarmak istediğinizi söyleyin. Doğal dilde yazmanız yeterli — kod veya seçiciler gerekmez.
- AI verileri çıkarır: Yapay zekamız Hacker News'i dolaşır, dinamik içerikleri işler ve tam olarak istediğiniz verileri çıkarır.
- Verilerinizi alın: CSV, JSON olarak dışa aktarmaya veya doğrudan uygulamalarınıza göndermeye hazır temiz, yapılandırılmış veriler alın.
Why use AI for scraping:
- Karmaşık CSS selector yazmadan hikayelerin 'point-and-click' ile seçilmesi
- Sorunsuz sayfalandırma için 'More' düğmesinin otomatik yönetimi
- Yerel IP'nizin rate-limit'e takılmasını önlemek için yerleşik bulut yürütme
- Ana sayfayı her saat otomatik olarak yakalamak için zamanlanmış scrape görevleri
- Gerçek zamanlı uyarılar için Google Sheets'e veya Webhook'lara doğrudan dışa aktarma
Hacker News için Kodsuz Web Kazıyıcılar
AI destekli kazımaya tıkla ve seç alternatifleri
Browse.ai, Octoparse, Axiom ve ParseHub gibi birçok kodsuz araç, kod yazmadan Hacker News kazımanıza yardımcı olabilir. Bu araçlar genellikle veri seçmek için görsel arayüzler kullanır, ancak karmaşık dinamik içerik veya anti-bot önlemleriyle zorlanabilirler.
Kodsuz Araçlarla Tipik İş Akışı
Yaygın Zorluklar
Öğrenme eğrisi
Seçicileri ve çıkarma mantığını anlamak zaman alır
Seçiciler bozulur
Web sitesi değişiklikleri tüm iş akışınızı bozabilir
Dinamik içerik sorunları
JavaScript ağırlıklı siteler karmaşık çözümler gerektirir
CAPTCHA sınırlamaları
Çoğu araç CAPTCHA için manuel müdahale gerektirir
IP engelleme
Agresif scraping IP'nizin engellenmesine yol açabilir
Hacker News için Kodsuz Web Kazıyıcılar
Browse.ai, Octoparse, Axiom ve ParseHub gibi birçok kodsuz araç, kod yazmadan Hacker News kazımanıza yardımcı olabilir. Bu araçlar genellikle veri seçmek için görsel arayüzler kullanır, ancak karmaşık dinamik içerik veya anti-bot önlemleriyle zorlanabilirler.
Kodsuz Araçlarla Tipik İş Akışı
- Tarayıcı eklentisini kurun veya platforma kaydolun
- Hedef web sitesine gidin ve aracı açın
- Çıkarmak istediğiniz veri öğelerini tıklayarak seçin
- Her veri alanı için CSS seçicileri yapılandırın
- Birden fazla sayfayı scrape etmek için sayfalama kuralları ayarlayın
- CAPTCHA'ları yönetin (genellikle manuel çözüm gerektirir)
- Otomatik çalıştırmalar için zamanlama yapılandırın
- Verileri CSV, JSON'a aktarın veya API ile bağlanın
Yaygın Zorluklar
- Öğrenme eğrisi: Seçicileri ve çıkarma mantığını anlamak zaman alır
- Seçiciler bozulur: Web sitesi değişiklikleri tüm iş akışınızı bozabilir
- Dinamik içerik sorunları: JavaScript ağırlıklı siteler karmaşık çözümler gerektirir
- CAPTCHA sınırlamaları: Çoğu araç CAPTCHA için manuel müdahale gerektirir
- IP engelleme: Agresif scraping IP'nizin engellenmesine yol açabilir
Kod Örnekleri
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Stories are contained in rows with class 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Title: {title}
Link: {link}
---')
except Exception as e:
print(f'Scraping failed: {e}')Ne Zaman Kullanılır
Minimal JavaScript içeren statik HTML sayfaları için en iyisi. Bloglar, haber siteleri ve basit e-ticaret ürün sayfaları için idealdir.
Avantajlar
- ●En hızlı çalışma (tarayıcı yükü yok)
- ●En düşük kaynak tüketimi
- ●asyncio ile kolayca paralelleştirilebilir
- ●API'ler ve statik sayfalar için harika
Sınırlamalar
- ●JavaScript çalıştıramaz
- ●SPA'larda ve dinamik içerikte başarısız olur
- ●Karmaşık anti-bot sistemleriyle zorlanabilir
Kod ile Hacker News Nasıl Kazınır
Python + Requests
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Stories are contained in rows with class 'athing'
posts = soup.select('.athing')
for post in posts:
title_element = post.select_one('.titleline > a')
title = title_element.text
link = title_element['href']
print(f'Title: {title}
Link: {link}
---')
except Exception as e:
print(f'Scraping failed: {e}')Python + Playwright
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://news.ycombinator.com/')
# Wait for the table to load
page.wait_for_selector('.athing')
# Extract all story titles and links
items = page.query_selector_all('.athing')
for item in items:
title_link = item.query_selector('.titleline > a')
if title_link:
print(title_link.inner_text(), title_link.get_attribute('href'))
browser.close()Python + Scrapy
import scrapy
class HackerNewsSpider(scrapy.Spider):
name = 'hn_spider'
start_urls = ['https://news.ycombinator.com/']
def parse(self, response):
for post in response.css('.athing'):
yield {
'id': post.attrib.get('id'),
'title': post.css('.titleline > a::text').get(),
'link': post.css('.titleline > a::attr(href)').get(),
}
# Follow pagination 'More' link
next_page = response.css('a.morelink::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)Node.js + Puppeteer
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com/');
const results = await page.evaluate(() => {
const items = Array.from(document.querySelectorAll('.athing'));
return items.map(item => ({
title: item.querySelector('.titleline > a').innerText,
url: item.querySelector('.titleline > a').href
}));
});
console.log(results);
await browser.close();
})();Hacker News Verileriyle Neler Yapabilirsiniz
Hacker News verilerinden pratik uygulamaları ve içgörüleri keşfedin.
Startup Trend Keşfi
Hangi sektörlerin veya ürün türlerinin en sık piyasaya sürüldüğünü ve tartışıldığını belirleyin.
Nasıl uygulanır:
- 1'Show HN' kategorisini haftalık olarak scrape edin.
- 2NLP kullanarak startup açıklamalarını temizleyin ve kategorize edin.
- 3Trendleri, topluluk oylarına ve yorumlardaki duygu analizine göre sıralayın.
Hacker News sitesinden veri çıkarmak ve kod yazmadan bu uygulamaları oluşturmak için Automatio kullanın.
Hacker News Verileriyle Neler Yapabilirsiniz
- Startup Trend Keşfi
Hangi sektörlerin veya ürün türlerinin en sık piyasaya sürüldüğünü ve tartışıldığını belirleyin.
- 'Show HN' kategorisini haftalık olarak scrape edin.
- NLP kullanarak startup açıklamalarını temizleyin ve kategorize edin.
- Trendleri, topluluk oylarına ve yorumlardaki duygu analizine göre sıralayın.
- Teknik Yetenek Arama ve İşe Alım
Özel aylık işe alım başlıklarından iş ilanlarını ve şirket detaylarını dışa aktarın.
- Aylık 'Who is hiring' (Kimler işe alıyor) başlığının ID'sini takip edin.
- İş tanımlarını içeren tüm üst düzey yorumları scrape edin.
- Metni Rust, AI veya React gibi belirli teknoloji yığınları için analiz edin.
- Rekabet İstihbaratı
Kamuoyu algısını ve şikayetleri anlamak için yorumlardaki rakip mention'larını takip edin.
- Belirli marka isimleri için anahtar kelime tabanlı bir scraper kurun.
- Duygu analizi için kullanıcı yorumlarını ve zaman damgalarını çekin.
- Rakiplere kıyasla marka sağlığı hakkında haftalık raporlar oluşturun.
- Otomatik İçerik Kürasyonu
Yalnızca en alakalı hikayeleri içeren, yüksek kaliteli bir teknoloji bülteni oluşturun.
- Ana sayfayı her 6 saatte bir scrape edin.
- 200 puan eşiğini aşan gönderileri filtreleyin.
- Bu bağlantıların bir Telegram botuna veya e-posta listesine gönderilmesini otomatize edin.
- Girişim Sermayesi (VC) Müşteri Adayı Belirleme
Topluluktan önemli ölçüde ilgi gören erken aşama startupları keşfedin.
- Ana sayfaya çıkan 'Show HN' gönderilerini takip edin.
- İlk 4 saat içindeki oy artış hızını izleyin.
- Bir gönderi viral büyüme kalıpları gösterdiğinde analistleri uyarın.
İş akışınızı güçlendirin Yapay Zeka Otomasyonu
Automatio, yapay zeka ajanlari, web otomasyonu ve akilli entegrasyonlarin gucunu birlestirerek daha az zamanda daha fazlasini basarmaniza yardimci olur.
Hacker News Kazımak için Pro İpuçları
Hacker News'den başarılı veri çıkarmak için uzman tavsiyeler.
HTML parsing karmaşıklığından kaçınmak ve devasa geçmiş verileri toplamak için resmi Firebase API kullanın.
Botunuzu sorumlu bir şekilde tanıtmak ve anında engellenmeyi önlemek için her zaman özel bir User-Agent ayarlayın.
İnsan gezinme davranışını taklit etmek için istekler arasına 3-7 saniyelik rastgele bekleme süreleri (sleep interval) ekleyin.
Yeni hikayeler için /newest veya topluluk tartışmaları için /ask gibi belirli alt dizinleri hedefleyin.
Ana sayfayı sık sık scrape ederken yinelenen kayıtları önlemek için 'Item ID' değerini birincil anahtar (primary key) olarak saklayın.
Daha hızlı yanıt süreleri ve daha düşük rate-limiting riskleri için trafiğin az olduğu saatlerde (UTC gece) scrape yapın.
Referanslar
Kullanicilarimiz Ne Diyor
Is akisini donusturen binlerce memnun kullaniciya katilin
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
Jonathan Kogan
Co-Founder/CEO, rpatools.io
Automatio is one of the most used for RPA Tools both internally and externally. It saves us countless hours of work and we realized this could do the same for other startups and so we choose Automatio for most of our automation needs.
Mohammed Ibrahim
CEO, qannas.pro
I have used many tools over the past 5 years, Automatio is the Jack of All trades.. !! it could be your scraping bot in the morning and then it becomes your VA by the noon and in the evening it does your automations.. its amazing!
Ben Bressington
CTO, AiChatSolutions
Automatio is fantastic and simple to use to extract data from any website. This allowed me to replace a developer and do tasks myself as they only take a few minutes to setup and forget about it. Automatio is a game changer!
Sarah Chen
Head of Growth, ScaleUp Labs
We've tried dozens of automation tools, but Automatio stands out for its flexibility and ease of use. Our team productivity increased by 40% within the first month of adoption.
David Park
Founder, DataDriven.io
The AI-powered features in Automatio are incredible. It understands context and adapts to changes in websites automatically. No more broken scrapers!
Emily Rodriguez
Marketing Director, GrowthMetrics
Automatio transformed our lead generation process. What used to take our team days now happens automatically in minutes. The ROI is incredible.
İlgili Web Scraping




Hacker News Hakkında Sık Sorulan Sorular
Hacker News hakkında sık sorulan soruların cevaplarını bulun